Lab 3 SST
1 概述
这一章的开头我们再次搬出我们的经典架构图:
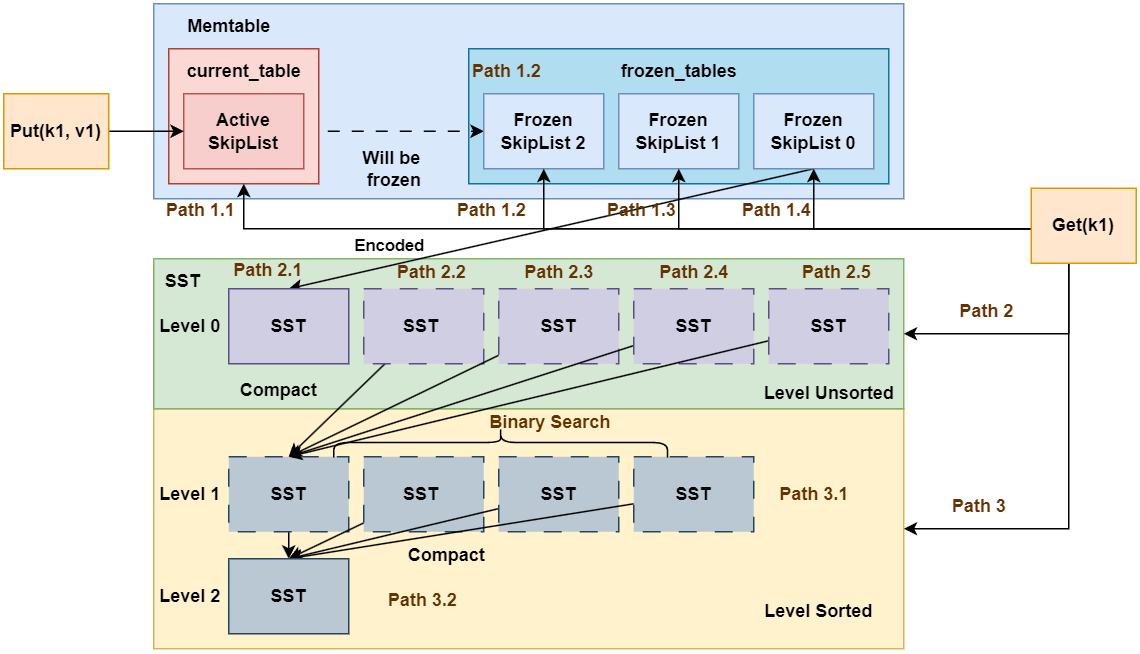
通过Lab1和Lab2的学习,我们已经初步完成了LSM Tree中内存的基础读写组件, 这一章我们将眼光从内存迁移到磁盘, 实现SST相关的内容。
从架构图中我们知道,SST文件是LSM Tree中持久化的存储文件,其中Level 0的SST存储了MemTable中单个Skiplist的数据,并且提供了LSM Tree中数据的有序性。因此对于一个磁盘中的文件, 我们肯定需要实现文件的编解码设计。其中编码设计用于将内存的Skiplist类的实例转化为SST文件, 而读取SST中的某些键值对时我们需要将文件进行解码并读取数据到内存。因此这一章中编解码是一大主题内容。而且相对之前常驻内存的MemTable而言, 这里的编解码代码的实现更为复杂, 尤其是Debug难度比之前要大上不少。
此外,我们从架构图中还了解到,不同Level的SST是需要再容量超出阈值时进行合并(Compact)的, 但Compact在本实验中是由更上层的控制结构实现的, 因此本节实验你不需要担心Compact, 这是后续Lab的内容, 这里提一嘴只是为了有助于从理论上理解其运行机制。
2 SST 的结构
从架构图中我们了解到,不同Level之间的容量呈指数增长, 其中最小的Level 0的SST也是SkipList的大小, 而SkipList实例在内存中是由多个链表组成的, 查询速度基本上和红黑树差不多。但假若我们想从SST中查一个键值对,总不可能把整个SST都解码放到内存中吧? 要知道高层Level的SST是可以轻易增长到GB的大小的。因此,SST必须进行内部的切分, 这里切分形成的一块数据我们称之为Block。因此对Block的组织管理就是SST设计的核心内容。Toni-LSM的SST文件结构如下:

SST文件由多个Block组成,每个Block_x内部暂且看成一个黑箱, 只需要知道其是我们查询的基本IO单元即可。 每个Block_x后会追加32位的哈希值,用于校验。每个Block对应一个Meta, 每个Meta记录这个Block在SST文件中的偏移量、第一个和最后一个key的元数据(长度和大小)。
这里,Block是基本的IO单元,这就意味着在查询一个key时, 其所在的整个Block的数据都会被解码并加载到内存中的。你可以类比操作系统中的Page, 其是内存和磁盘之间的基本IO单元。
另一方面,在查询一个key时,如何确定查哪一个Block呢? 这里就需要将SST中的Extra Information中的元数据提前加载到内存中, 这些元数据能够定位到Meta Section, 而Meta Section是一个数组, 其中每个Meta_x记录了对应Block在整个SST中的位置, 可以以此来快速对指定为位置的二进制数据进行解码。
你肯定能想到, 作为基本的IO单元, 我们肯定会为其实现一个缓存池的, 这样可以避免每次查询时都进行磁盘IO。
心细的你肯定也注意到, 这里有一个Bloom Section, 这其实就是布隆过滤器中的bit位数组, 其用处是拦截无效的访问, 这会在后续的Lab中进行详细讲解。
3 Block的结构
现在我们来看Block的结构, Block是SST中的基本IO单元,即SST的每个查询最终是在Blcok中定位到具体的键值对的, 其结构为:

上图的
B表示一个字节
一个Block包含:Data Section、Offset Section和Extra Information三部分:
Data Section: 存放所有的数据, 也就是key和value的序列化数据- 每一对
key和value都是一个Entry, 编码信息包括key_len、key、value_len和valuekey_len和value_len都是2B的uint16_t类型, 用于表示key和value的长度key和value就是对应长度的字节数, 因此需要用varlen来表示。
- 每一对
Offset Section: 存放所有Entry的偏移量, 用于快速定位Extra Information: 存放num_of_elements, 也就是Entry的数量
这样编码满足了最基本的要求, 从最后的2个字节可以知道Block包含了多少kv对, 再从Offset Section中查询对应的kv对数据的偏移。
4 思考
现在有了Block和SST的设计方案, 你可以思考如下几个问题:
Blcok和SST是如何构建的?Block如何进行划分?Block内部如何实现迭代器吗?SST的迭代器是单独设计, 还是对已有Blcok迭代器的封装? 如何封装?Block的缓存池如何设计?- 布隆过滤器和缓存池的设计各自有什么作用? 他们的功能是否重复?
当你对上述问题有过简单思考后, 你可以开启本次Lab了, 你需要有一定心理准备, 这一大章节的Lab原比之前的MemTable和Skiplist复杂, 现在开始第一部分 Block 实现。