Lab 1 跳表实现
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab git checkout your_branch git merge lab如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
1 跳表在 LSM Tree 中的作用
本Lab中, 你将实现内存的基础数据结构作为MemTable的容器, 这里使用基于红黑树的std::map也是可行的, 但LSM Tree的原始论文中使用的是跳表, 因此我们选择使用跳表作为MemTable的容器,并且正好实现以下这个数据结构 (造轮子是C++的快乐)。
我们再次回顾下面的这张架构图:
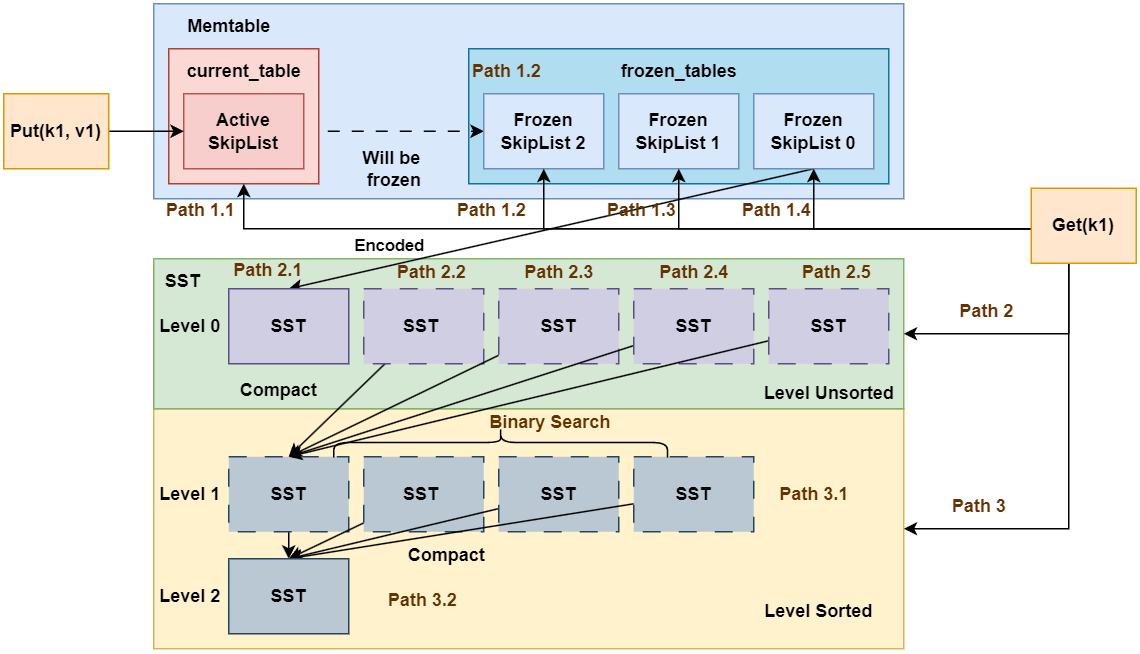
这里的MemTable用于存储内存中的键值对数据, 其存储的基础容器即为Skiplist。SkipList被划分为2组: current_table和frozen_table。current_table可读可写, 并是唯一写入的SkipList, frozen_table是只读状态, 用于存储已经写入的键值对数据。current_table容量超出阈值即转化为frozen_table中的一个。
2 跳表的原理
这里简单介绍一下跳表是什么, 跳表就是过个链表, 每个链表的步长不同, 且链表节点是排序的, 查找或插入时, 先使用最大步长层级的链表, 然后定位大区间后, 转入下层低步长层级的链表继续查询, 是不是非常简单? :smile:
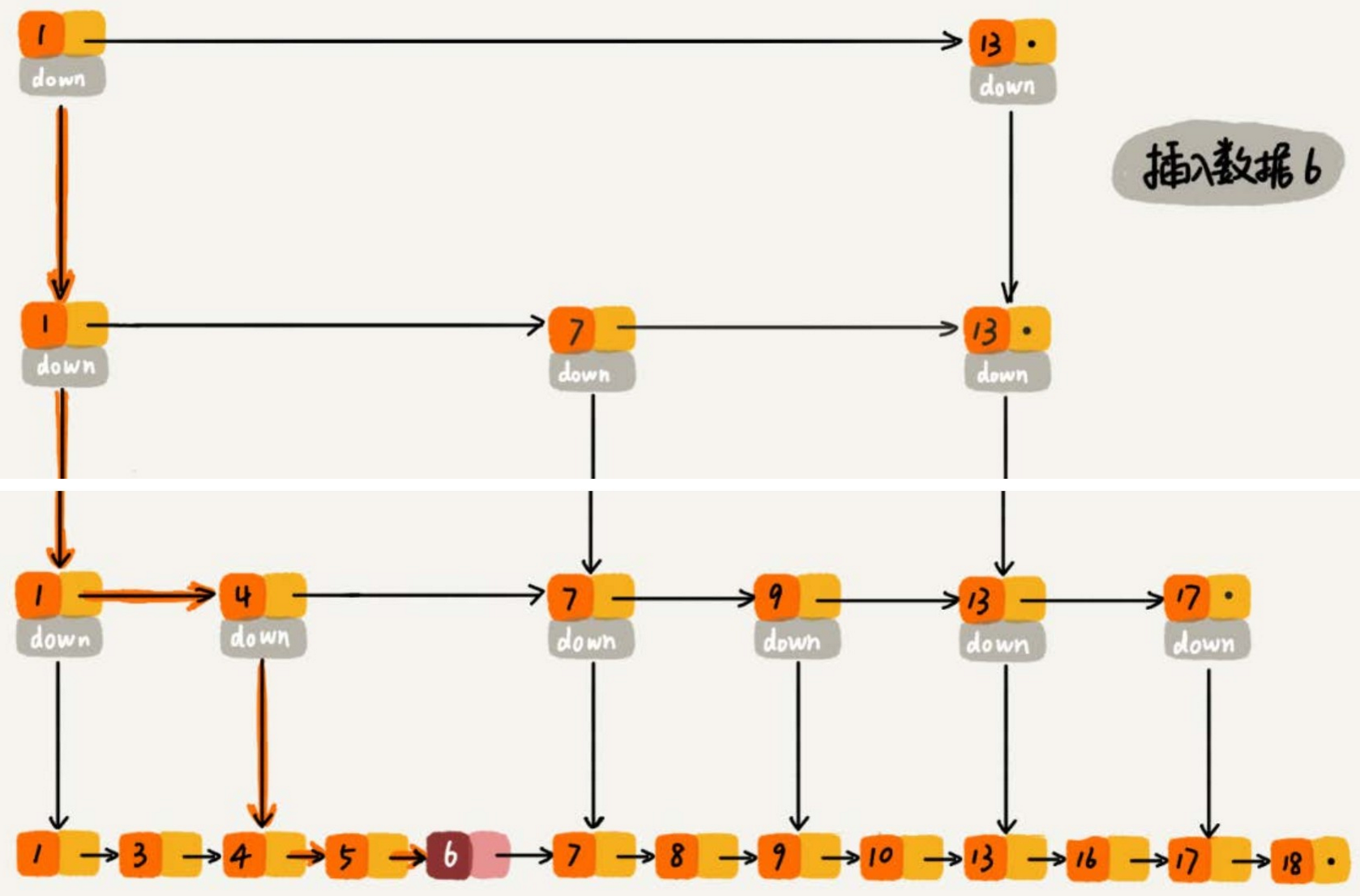
上图所示为跳表的简单示意图, 可以看出跳表由多层链表组成,每一层都是一个有序链表。最底层的链表包含所有元素,而上层的链表只包含部分元素,这些元素作为“索引”加速查找过程。
2.1 查找过程
假设我们要查找值为6的节点:
- 从最高层开始:从最高层的头节点开始,沿着水平指针向右移动,直到遇到大于目标值的节点或到达该层的末尾。
- 向下移动:如果当前层没有找到目标值,则沿着垂直指针向下移动到下一层,重复上述步骤。
- 继续查找:在每一层中重复这个过程,直到在最底层找到目标值或确定目标值不存在。
2.2 插入过程
假设我们要插入值为6的节点:
- 查找插入位置:首先按照查找过程找到值为6应该插入的位置。在这个例子中,值为6应该插入在4和7之间。
- 创建新节点:在最底层创建一个新节点,值为6,并将其插入到正确的位置。
- 随机决定层数:使用随机算法决定新节点的层数。例如,可以以50%的概率决定是否将新节点添加到上一层。
- 更新指针:在每一层中更新指针,确保新节点被正确地链接到链表中。
2.3 删除过程
假设我们要删除值为6的节点:
- 查找要删除的节点:首先按照查找过程找到值为6的节点。
- 逐层删除:从最底层开始,逐层删除该节点,并更新相应的指针。
- 调整层数:如果某一层只剩下头节点和尾节点,则可以考虑删除这一层以优化空间。
3 还欠缺什么?
在你了解到了上述LSM的基础知识后, 你可能觉得SkipList的实现不过如此, 很简单吧。但实际上也没有那么简单,首先你需要思考下面几个问题:
- 不同
Level的链表的步长如何确定?- 最底层
Level 0的链表步长肯定是1, 那么Level 1呢,Level 2呢?
- 最底层
- 什么时候我们需要创建新的
Level的?- 一开始的时候,
SkipList的Level是多少? - 新创建的
Level是逐层创建的吗? 还是说一次性提升好几层?
- 一开始的时候,
- 上面演示的
SkipList仅仅是单向链表, 如果是双向链表, 有什么区别呢?
带着疑问, 你可以开启下一章跳表 put/remove 的实现的Lab实验了