Lab 4.9 布隆过滤器
除了缓存池之外,我们下一个要实现的优化方案是布隆过滤器。布隆过滤器你可能在各大校招实习的八股文中都遇到过(尤其是和经典问题:如何避免Redis的缓存穿透问题)。本小节我们就将自己实现一个布隆过滤器。
1 布隆过滤器简介
1.1 原理介绍
布隆过滤器是一种 probabilistic 数据结构,用于判断一个元素是否在集合中。它通过一个概率的方式来判断,即使集合中存在一个元素,但是布隆过滤器也依然可以判断出来。
布隆过滤器的核心思想是使用一个位数组和多个哈希函数来表示一个集合。它的特点是可以高效地判断某个元素是否“可能存在”或“确定不存在”,但它有一定的误判率,即可能会误判某个不存在的元素为“可能存在”。其实现方式如下:
- 初始化位数组:布隆过滤器使用一个固定大小的位数组(如长度为
m),所有位初始化为0。 - 插入元素时在位数组记录:当插入一个元素时,使用
k个独立的哈希函数对该元素进行哈希运算,得到k个哈希值(每个值对应位数组的索引)。将这些索引位置的位设置为1。 - 查询元素时在位数组校验:当查询一个元素是否存在时,同样使用
k个哈希函数对该元素进行哈希运算,得到k个哈希值。如果这些哈希值对应的位数组中的所有位都为1,则判断该元素“可能存在”;如果有任意一位为0,则判断该元素“确定不存在”。
特点
- 优点:布隆过滤器的空间效率和查询效率非常高,适合处理大规模数据。
- 缺点:存在一定的误判率(即可能会误判不存在的元素为“可能存在”),并且无法删除元素(删除可能会影响其他元素的判断)。
1.2 案例介绍
下面我们通过一个案例来看看布隆过滤器的运行机制:
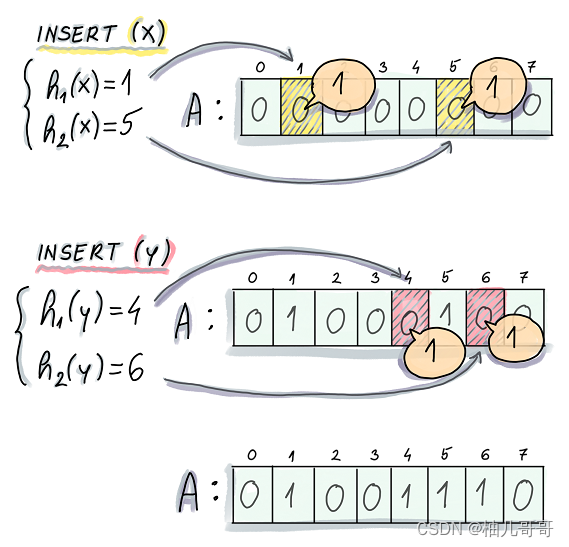
- 在新增一个记录时(
put/insert等), 通过预定义数量(案例图片中是2个)的哈希函数对key进行哈希, 将哈希值对位数组的长度取模, 将结果作为索引, 将索引位置的位设置为1 - 在查询时(
get), 通过预定义数量(案例图片中是2个)的哈希函数对key进行哈希, 将哈希值对位数组的长度取模, 将结果作为索引, 如果索引位置的位为1, 则认为该key可能存在, 否则认为该key不存在
2 LSM-Tree中的布隆过滤器
尽管我们之前为整个LSM-Tree设计了bock cache, 但面对大量不存在于LSM-Tree中的key时, bock cache会频繁的进行磁盘IO, 这将导致LSM-Tree的性能降低。
这里的原理类似后端八股文中
Redis常问的缓存击穿、缓存穿透、缓存雪崩,而设置布隆过滤器就是一个景点的解决方案,背过八股的同学们应该会很熟悉。
因此,我们可以在编码SST文件时,为每个SST文件都设计一个bloom filter, 在其中记录整个SST中的所有key, 并将其持久化到文件系统中, 在读取文件时, 相应的布隆过滤器部分也需要被解码并加载到内存中。这样当查询时, 我们只需要判断key是否存在于bloom filter中, 如果不存在, 则认为该key不存在于LSM-Tree, 否则, 我们需要继续在LSM-Tree中查找。这样以来, 我们就可以避免大量的无效访问。
3 布隆过滤器代码解读
同样地, 我们解读下头文件的定义:
class BloomFilter {
public:
// 构造函数,初始化布隆过滤器
// expected_elements: 预期插入的元素数量
// false_positive_rate: 允许的假阳性率
BloomFilter();
BloomFilter(size_t expected_elements, double false_positive_rate);
// ...
private:
// 布隆过滤器的位数组大小
size_t expected_elements_;
// 允许的假阳性率
double false_positive_rate_;
size_t num_bits_;
// 哈希函数的数量
size_t num_hashes_;
// 布隆过滤器的位数组
std::vector<bool> bits_;
private:
// 第一个哈希函数
// 返回值: 哈希值
size_t hash1(const std::string &key) const;
// 第二个哈希函数
// 返回值: 哈希值
size_t hash2(const std::string &key) const;
size_t hash(const std::string &key, size_t idx) const;
};
我们需要完成如下的功能:
- 能够在初始化时通过假阳性率和键的数量来确定哈希函数的数量和位数组的长度
- 支持编码与解码
对于通过假阳性率和键的数量来确定哈希函数的数量和位数组的长度, 我们可以按照指定的公式求取, 但问题在于我们是不知道哈希函数的数量的, 难道我们要手动写很多个哈希函数吗?
我们可以采用这样的方案: 只写2个哈希函数, 通过对这两个哈希函数的线性组合构造新的哈希函数, 这也就是你在头文件定义中看到的hash1和hash2
这里有一个坑,
std::vector<bool>中单个元素存储只占一个位, 而不是一个字节
此外, 你应该从之前的介绍中了解到, 布隆过滤器只能滤除百分百不存在的元素, 但其不能保证一个元素一定存在。不过我们可以给出一个目标概率, 例如,如果目标概率为0.01,则表示我们希望布隆过滤器误判的概率不超过1%。这就是成员变量中的false_positive_rate。
假阳性率和位数组长度之间的关系可以用以下公式表示:
$$m = - \frac{n \cdot \ln(p)}{(\ln(2))^2}$$
其中,m 是位数组的长度,n 是预期插入的元素数量,p 是假阳性率。
而哈希函数的数量由公式: $$k = \frac{m}{n} \cdot \ln(2)$$
为什么公式是这样的? 你可以尝试自己推导, 也可以去
LLM
4 代码实现
4.1 构造函数
// 构造函数,初始化布隆过滤器
// expected_elements: 预期插入的元素数量
// false_positive_rate: 允许的假阳性率
BloomFilter::BloomFilter(size_t expected_elements, double false_positive_rate)
: expected_elements_(expected_elements),
false_positive_rate_(false_positive_rate) {
// TODO: Lab 4.9: 初始化数组长度
}
这里, 构造函数就是按照之前理论介绍部分中的公式, 确定数组长度并初始化容器和哈希函数数量
4.2 hash
如同之前介绍的, hash函数有很多个, 我们不可能手动写出一大堆候选函数出来, 因此这里你需要对hash1和hash2进行组合, 构造出新的哈希函数(idx标识这是第几个哈希函数):
size_t BloomFilter::hash(const std::string &key, size_t idx) const {
// TODO: Lab 4.9: 计算哈希值
// ? idx 标识这是第几个哈希函数
// ? 你需要按照某些方式, 从 hash1 和 hash2 中组合成新的哈希函数
return 0;
}
4.3 add
添加记录时, 我们根据哈希函数的序号, 调用你之前实现的hash函数, 将结果对位数组的长度取模, 将结果作为索引, 将索引位置的位设置为1:
void BloomFilter::add(const std::string &key) {
// TODO: Lab 4.9: 添加一个记录到布隆过滤器中
}
4.4 encode/decode
与缓存池不同, 布隆过滤器需要持久化到文件系统中。这是因为我们的Block在形成后就是只读的形式了, 不会发生变化。如果不持久化到文件系统中, 那么在重启时, 我们就则需要对每个键值对再次进行解码和哈希运算构造新的布隆过滤器实例, 这显然是不合理的。因此你需要实现编码和解码函数:
// 编码布隆过滤器为 std::vector<uint8_t>
std::vector<uint8_t> BloomFilter::encode() {
// TODO: Lab 4.9: 编码布隆过滤器
return std::vector<uint8_t>();
}
// 从 std::vector<uint8_t> 解码布隆过滤器
BloomFilter BloomFilter::decode(const std::vector<uint8_t> &data) {
BloomFilter bf;
// TODO: Lab 4.9: 解码布隆过滤器
return bf;
}
这里我们仍然使用std::vector<uint8_t>作为编码后的数据结构, 你需要将位数组中的每个元素都编码为一个字节, 并将所有字节拼接起来。这里的二进制数组将整合到SST文件中。
5 将 BloomFilter 集成到 SST
现在你已经实现了BloomFilter, 你需要将其集成到SST文件中。具体来说,你需要修改SST文件的编码和解码函数:
- 编码时调用
BloomFilter::encode将编码的布隆过滤器部分的std::vector<uint8_t>拼接到SST文件的正确位置; - 解码时从
SST文件的指定偏移位置取出std::vector<uint8_t>切片, 并解码出BloomFilter放置于SST类实例的控制结构的成员变量中。
这里回顾一下我们的SST文件的结构:

你应该知道这里Bloom Section的...里面放置的是什么了吧?
首先, 之前的SSTBuilder::build和SST::open涉及整个SST的持久化和编解码, 是你肯定需要修改的。此外由于每个人的设计思路不同, 因此其他地方没有固定的修改文件和函数, 你只需要保证编解码过程正确、查询数据时能够正常利用到布隆过滤器即可。
6 测试
对于布隆过滤器本身, 你应该可以通过下面的测试:
✗ xmake
✗ xmake run test_utils # 布隆过滤器的测试包含在 `test_utils` 中
[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from BloomFilterTest
[ RUN ] BloomFilterTest.ComprehensiveTest
False positive rate: 0.08
[ OK ] BloomFilterTest.ComprehensiveTest (2 ms)
[----------] 1 test from BloomFilterTest (2 ms total)
[----------] Global test environment tear-down
[==========] 1 test f
类似之前缓存池的小节, 在逻辑层面本节实验并未新添加任何接口, 只是做出了IO层面的优化, 因此, 你只需要像Lab 4.7 复杂查询那样再次运行单元测试, 观察前后数据读取的效率变化即可。
需要说明的是, 你需要尤其关注Persistence这个测例(位于test/test_lsm.cpp), 因为其会插入大量的数据并刷盘, 此时的大部分查询请求都是在SST文件层面进行的, 能够较为明显地观察出加入缓存池优化后的速度变化。