Lab 4 LSM Engine
本章Lab将串联之前实现的MemTable, SST, Block, 各类Iterator, 实现一个初版的完整的单机KV存储引擎。
提示: 强烈建议你自己创建一个分组实现
Lab的内容, 并在每次新的Lab开始时进行如下同步操作:git pull origin lab git checkout your_branch git merge lab如果你发现项目仓库的代码没有指导书中的 TODO 标记的话, 证明你需要运行上述命令更新代码了
1 概述
实现了之前的Skiplist, MemTable, SST, Block, 各类Iterator之后, 我们对其进行"简单"地封装, 即可得到一份可以运行的LSM Engine。完成这一章Lab后, 你将得到一个可以被外部结构调用的共享链接库, 其暴露了各种基础的KV存储引擎接口。
同样地, 我们再一次回顾我们的架构:
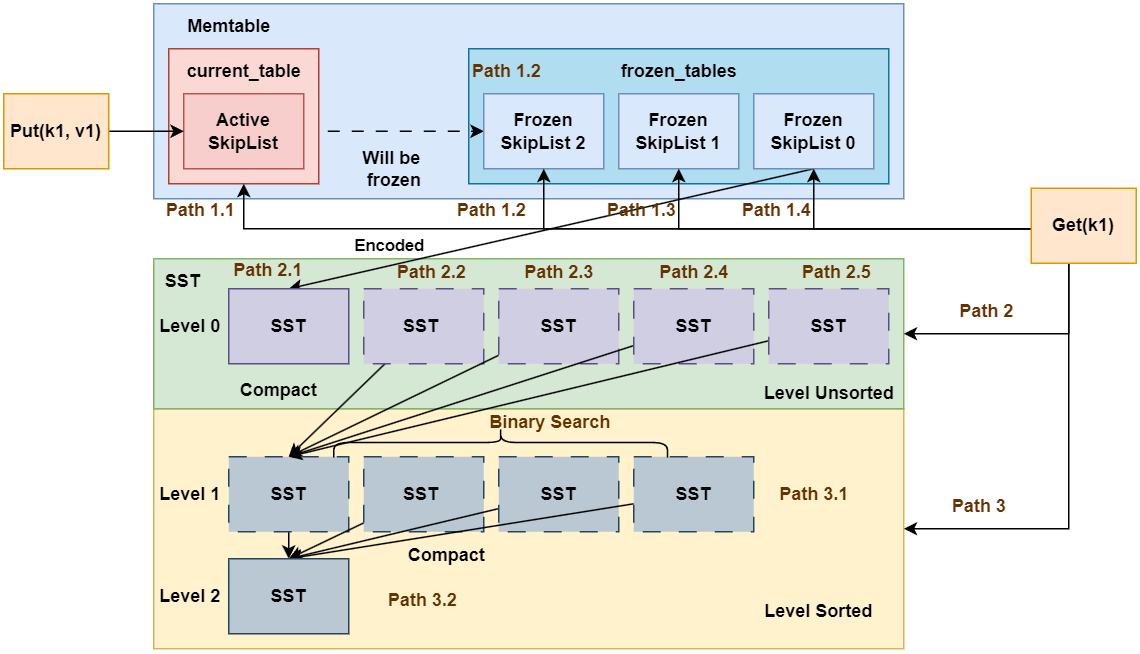
可以看到, 不同组件之间存在各种交互, 这些交互内容包括:
MemTable和SST之间进行Encoded并刷盘形成SST文件- 不同
SST之间的连接(例如遍历这一层的SST的键值对) - 相邻
Level之间SST的Compact操作 Client发出Get请求到MemTable和SST组件的查询路径
这一章的Lab就是将我们之前已经实现的组件进行串联, 形成初版的LSM Tree存储引擎。
2 思考
同样地, 请先思考下面几个问题, 然后带着问题开始本章的Lab:
- 不同组件之间交互的媒介是什么? 是迭代器吗?
- 之前提到的布隆过滤器和缓存池的优化并未在架构图中给出, 他们位于哪个位置?
- 缓存池缓存的是
Blcok, 但如果SST被压缩形成新的SST文件, 缓存池中的Block将不再有效, 缓存池中的无效的Block将如何处理? - 不同
Level的SST Compact采用什么策略? 他们对Read/Write性能有什么影响? - 我们实现整个
LSM Engine的范围查询等操作时, 去重和排序逻辑和之前的组件有什么区别? - 为什么
Level 0要设计成Unsorted? 所有的Level的SST都是Sorted不好吗? - 不同组件交互过程中, 如何设计并发控制策略, 保证其性能?
- 实现上述的功能, 是不是又要设计新的迭代器?
这些问题你不一定要马上给出一个清晰的答案, 只需要有一个整体的认知和思考即可, 这样有助于你对整个项目代码设计思路的理解。
由于本实现的设计目的就是让更广大的开发者或CS专业的学生对
KV存储有初步的认真, 因此难度是被刻意降低了的, 你不需要进行架构设计层面的思考以及对应代码的编写, 只需要补全作者挖空的关键函数。因此,如果你一味地完成
Lab的代码, 却缺乏对作者给出思考题的理解, 那么你对本实验项目的理解可能是不到位的, 即你知道这么设计的代码能正常运行, 但却不知道他为什么这么设计。