Lab 2.2 迭代器
1 迭代器的作用
我们需要实现整个MemTable的迭代器, 这算是本Lab的一个难点, 因为新的SkipList中的元素会导致旧的SkipList的部分元素失效, 因此不能简单地将不同SkipList的遍历结果拼接起来就完事儿。
试想下面这个场景:
SkipList0: ("k1", "v1") -> ("k4", "") -> ("k5", "v3")
SkipList1: ("k2", "v2") -> ("k3", "v3") -> ("k4", "v4")
SkipList0中的("k4", "")表示删除了"k4", 因此如果我们先消耗了SkipList0的迭代器, 那么SkipList1中就无法获取"k3"的不合法性, 因此需要对不同SkipList的迭代器进行merge操作来删除这些无效的元素。
本实验的建议方案是:
可以维护一个堆,堆首先根据key排序, 然后根据SkipList id排序, 因此相同的key, 后插入的记录肯定更靠近堆顶(因为SkipList id越小表示其越新), 因此堆顶的某个key一定是整个MemTable中该key的最新记录, 迭代器对该key只需要堆顶的这一个元素, 其余在取出堆顶后即可全部移除(因为首先按照key排序, 所以他们一定连续出现在堆顶)
2 堆去重的原理
我们假设有以下两个 SkipList:
SkipList0 (id=0): ("k1", "v1") -> ("k4", "") -> ("k5", "v3") // 最新的
SkipList1 (id=1): ("k2", "v2") -> ("k3", "v3") -> ("k4", "v4")
我们借助之前Skiplist的迭代器, 遍历各个Skiplist, 把所有键值对按 key 排序后放入堆,排序依据是:
- 先按
key升序,即key越小越靠近堆顶 - 对于相同的
key,选择tranc_id较大(越新)的优先(越靠近堆顶)(这一条你可暂时哦忽略, 测试中tranc_id都是0) - 按照
SkipList来源的新旧排序, 新SkipList的键值对更靠近堆顶(这里的id是构建堆时手动赋予的)
最后的排序依据中, 这个新旧的顺序需要你手动指定, 无论你实现的排序是更大的
id表示更新的SKiplist还是更小的id表示更新的SKiplist, 自身逻辑自洽即可 建议将更新的Skiplist用更大的id标识, 因为id随新的Skiplist增长是很正常的事情
遍历迭代器, 并逐一构建堆元素插入堆中, 最终的堆的示意图为:
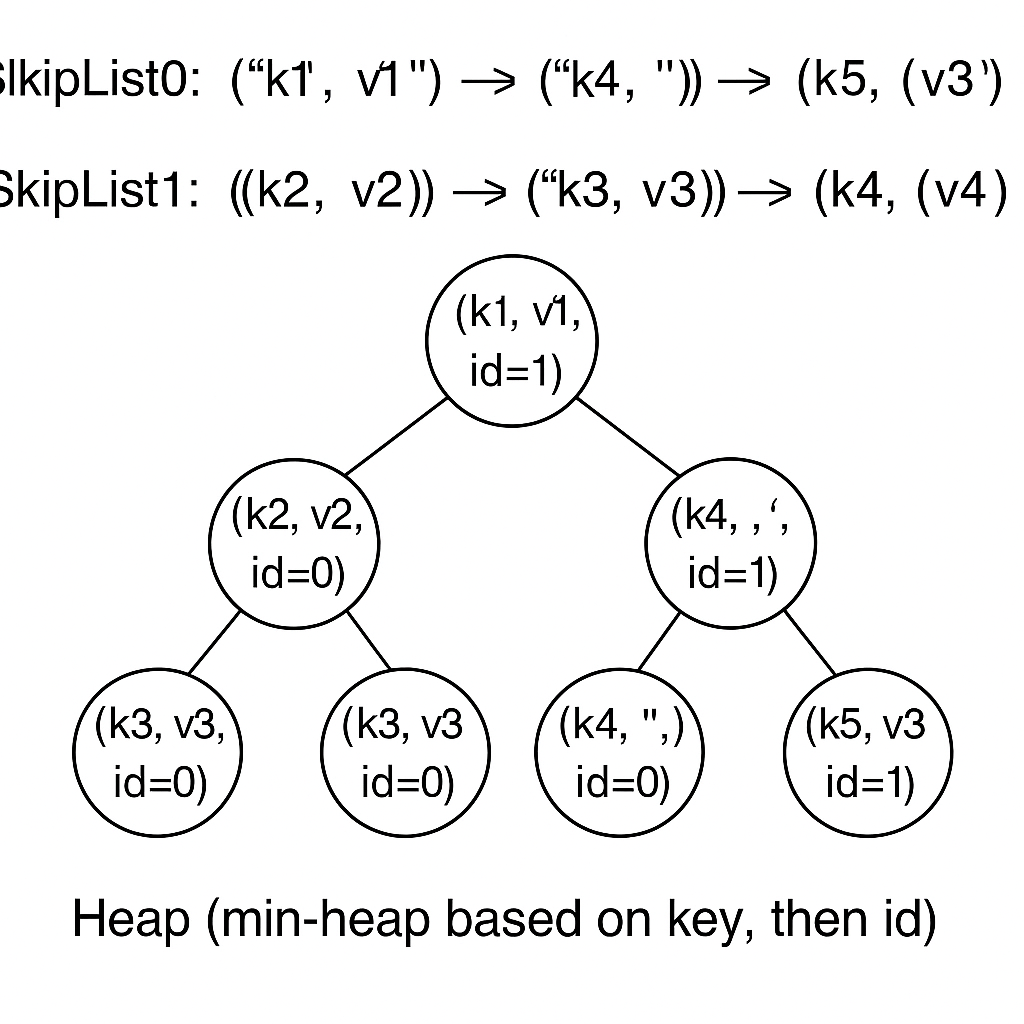
这里可以看到, k4的键值对中, 更新的跳表中的键值对更靠近堆顶, 当我们遍历这个堆并不断弹出元素时, 相同key的元素只能被迭代器(这个堆肯定是迭代器封装的一个成员变量)对外暴露一次, 其余相同key的键值对进行丢弃即可, 这样我们就能利用类似堆排序的功能, 同时完成了排序和去重。
3 基于堆的迭代器实现
3.1 代码框架介绍
因此,本实验你首先要基于上述原理的介绍实现一个基于堆的迭代器。
本小节需要你修改的代码:
src/iterator/iterator.cppinclude/iterator/iterator.h(Optional)src/memtable/memtable.cppinclude/memtable/memtable.h(Optional)
首先是SearchItem, 我们来看定义:
// *************************** SearchItem ***************************
struct SearchItem {
std::string key_;
std::string value_;
uint64_t tranc_id_;
int idx_;
int level_; // 来自sst的level
SearchItem() = default;
SearchItem(std::string k, std::string v, int i, int l, uint64_t tranc_id)
: key_(std::move(k)), value_(std::move(v)), idx_(i), level_(l),
tranc_id_(tranc_id) {}
};
bool operator<(const SearchItem &a, const SearchItem &b);
bool operator>(const SearchItem &a, const SearchItem &b);
bool operator==(const SearchItem &a, const SearchItem &b);
其就是我们之前提到的每个堆节点的数据结构, 这里的构造函数中, k, v, i即为key, value, id(跳表的), l表示来源的层级, 现在我们都是在内存操作, 设为0即可, tranc_id不需要你理解, 直接赋值即可。
然后是你要实现的迭代器HeapIterator的定义:
class HeapIterator : public BaseIterator {
public:
HeapIterator() = default;
HeapIterator(std::vector<SearchItem> item_vec, uint64_t max_tranc_id);
// ...
private:
std::priority_queue<SearchItem, std::vector<SearchItem>,
std::greater<SearchItem>>
items;
mutable std::shared_ptr<value_type> current; // 用于存储当前元素
uint64_t max_tranc_id_ = 0;
};
这里的priority_queue就是我们之前提到的堆, C++的堆实际上就是优先队列。
在
C++中,当使用std::priority_queue来实现小根堆(min-heap)时,你需要使用std::greater<SearchItem>作为比较函数对象。感兴趣的同学可以查一查为什么要这么设计。
3.2 实现 SearchItem 的比较规则
bool operator<(const SearchItem &a, const SearchItem &b) {
// TODO: Lab2.2 实现比较规则
return true;
}
bool operator>(const SearchItem &a, const SearchItem &b) {
// TODO: Lab2.2 实现比较规则
return true;
}
bool operator==(const SearchItem &a, const SearchItem &b) {
// TODO: Lab2.2 实现比较规则
return true;
}
这里你需要按照之前介绍的比较规则进行代码补全。
3.3 实现构造函数
接下来你需要实现HeapIterator的构造函数, 其参数就是已经遍历了所有Skiplist的迭代器构造的vector, max_tranc_id你可以暂时忽略:
HeapIterator::HeapIterator(std::vector<SearchItem> item_vec,
uint64_t max_tranc_id)
: max_tranc_id_(max_tranc_id) {
// TODO: Lab2.2 实现 HeapIterator 构造函数
}
Hint: 构造完堆后, 是否需要额外的一些初始化的滤除?
3.4 实现自增函数
接下来自增函数是最重要的, 自增函数的逻辑是:
- 自增后的
key不能是之前相同的key, 如果是(以为着实际上被前者覆写了), 则跳过 - 自增后的键值对不能是删除标记, 即
value为空
BaseIterator &HeapIterator::operator++() {
// TODO: Lab2.2 实现 ++ 重载
return *this;
}
同时, 这些辅助函数的实现有助于你完成:operator++()和之前的构造函数:
bool HeapIterator::top_value_legal() const {
// TODO: Lab2.2 判断顶部元素是否合法
// ? 被删除的值是不合法
// ? 不允许访问的事务创建或更改的键值对不合法(暂时忽略)
return true;
}
void HeapIterator::skip_by_tranc_id() {
// TODO: Lab2.2 后续的Lab实现, 只是作为标记提醒
}
3.4 其他运算符重载函数
其他运算符重载函数就简单了很多, 但仍然是对你代码理解的考验:
HeapIterator::pointer HeapIterator::operator->() const {
// TODO: Lab2.2 实现 -> 重载
return nullptr;
}
HeapIterator::value_type HeapIterator::operator*() const {
// TODO: Lab2.2 实现 * 重载
return {};
}
BaseIterator &HeapIterator::operator++() {
// TODO: Lab2.2 实现 ++ 重载
return *this;
}
bool HeapIterator::operator==(const BaseIterator &other) const {
// TODO: Lab2.2 实现 == 重载
return true;
}
bool HeapIterator::operator!=(const BaseIterator &other) const {
// TODO: Lab2.2 实现 != 重载
return true;
}
其中->运算符重载, 你可以直接利用已有的成员变量mutable std::shared_ptr<value_type> current, 返回器地址, 但你需要在构造函数和自增函数中对其进行正确的初始化和重置, 下面这个函数即为初始化和重置的逻辑实现:
void HeapIterator::update_current() const {
// current 缓存了当前键值对的值, 你实现 -> 重载时可能需要
// TODO: Lab2.2 更新当前缓存值
}
4 MemTable的迭代器
接下来, 有了HeapIterator, 你可以实现MemTable组件的全局迭代器了:
HeapIterator MemTable::begin(uint64_t tranc_id) {
// TODO Lab 2.2 MemTable 的迭代器
return {};
}
HeapIterator MemTable::end() {
// TODO Lab 2.2 MemTable 的迭代器
return HeapIterator{};
}
这里的逻辑就是利用之前实现的HeapIterator对整个MemTable进行遍历。
5 测试
当你完成上述所有功能后, 你可以通过如下测试:
✗ xmake
✗ xmake run test_memtable
[==========] Running 9 tests from 1 test suite.
[----------] Global test environment set-up.
[----------] 9 tests from MemTableTest
[ RUN ] MemTableTest.BasicOperations
[ OK ] MemTableTest.BasicOperations (0 ms)
[ RUN ] MemTableTest.RemoveOperations
[ OK ] MemTableTest.RemoveOperations (0 ms)
[ RUN ] MemTableTest.FrozenTableOperations
[ OK ] MemTableTest.FrozenTableOperations (0 ms)
[ RUN ] MemTableTest.LargeScaleOperations
[ OK ] MemTableTest.LargeScaleOperations (0 ms)
[ RUN ] MemTableTest.MemorySizeTracking
[ OK ] MemTableTest.MemorySizeTracking (0 ms)
[ RUN ] MemTableTest.MultipleFrozenTables
[ OK ] MemTableTest.MultipleFrozenTables (0 ms)
[ RUN ] MemTableTest.IteratorComplexOperations
[ OK ] MemTableTest.IteratorComplexOperations (0 ms)
[ RUN ] MemTableTest.ConcurrentOperations
[ OK ] MemTableTest.ConcurrentOperations (601 ms)
[ RUN ] MemTableTest.PreffixIter
[ OK ] MemTableTest.PreffixIter (0 ms)
[----------] 9 tests from MemTableTest (602 ms total)
[----------] Global test environment tear-down
[==========] 9 tests from 1 test suite ran. (602 ms total)
[ PASSED ] 9 tests.
接下来你可以开启下一小节的Lab