1. LSM Tree 简介
在具体进入本实验之前,我们先来简单介绍LSM Tree。
LSM Tree是一种KV存储架构。其核心思想是,将KV存储的数据以SSTable的形式进行持久化,并通过MemTable进行内存缓存,当MemTable的数据量达到一定阈值时,将其持久化到磁盘中,并重新创建一个MemTable。LSM Tree的核心思想是,将KV存储的数据以SSTable的形式进行持久化,并通过MemTable进行内存缓存。并且, 数据以追加写入的方式进行,删除数据也是通过更新的数据进行覆盖的方式实现。
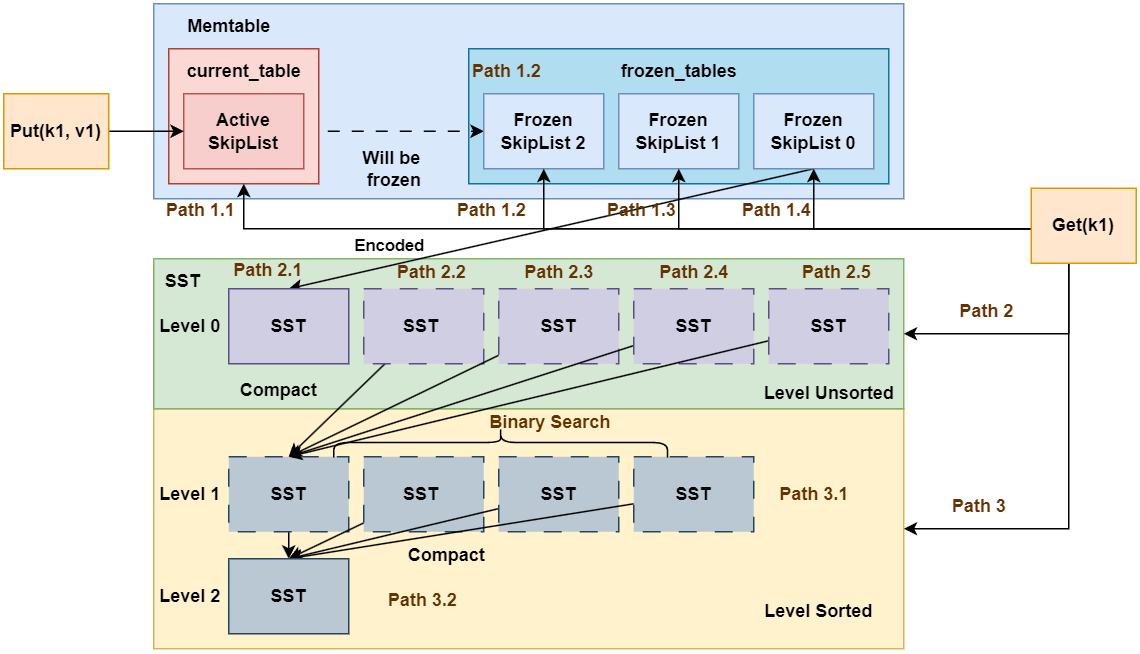
如图所示为LSM Tree的核心架构。我们通过Put, Remove和Get操作的流程对其进行介绍。
1.1 Put 操作流程
Put操作流程如下:
- 将
Put操作的数据写入MemTable中MemTable中包括多个键值存储容器(本项目是采用的跳表SkipList)- 其中有一份称为
current_table, 即活跃跳表, 其可读可写 - 其余的多份跳表均为
frozen_tables, 即即冻结跳表, 其只能进行读操作
- 其中有一份称为
Put的键值对首先插入到current_table中- 如果
current_table的数据量未达到阈值, 直接返回给客户端 - 如果
current_table的数据量达到阈值, 则将current_table被冻结称为frozen_tables中的一份, 并重新初始化一份current_table
- 如果
- 如果前述步骤导致了新的
frozen_table产生, 判断frozen_table的容量是否超出阈值 - 如果超出阈值, 则将
frozen_table持久化到磁盘中, 形成SST(全程是Sorted String Table), 单个SST是有序的。SST按照不同的层级进行划分, 内存中的MemTable刷出的SST位于Level 0,Level 0的SST是存在重叠的。(例如SST 0的key范围是[0, 100),SST 1的key范围是[50, 150), 那么SST 0和SST 1的key在50, 100)范围是重叠的, 因此无法在整个层级进行二分查询)- 当
Level 0的SST数量达到一定阈值时, 会进行Level 0的SST合并, 将SST进行compact操作, 新的SST将放在Level 1中。同时,为保证此层所有SST的key有序且不重叠,compact的SST需要与原来Level 1的SST进行重新排序。由于compact时将上一层所有的SST合并到了下一层, 因此每层单个SST的容量是呈指数增长的。 - 当每一层的
SST数量达到一定阈值时,compact操作会递归地向下一层进行。
1.2 Remove 操作流程
由于LSM Tree的操作是追加写入的, 因此Remove操作与Put操作本质上没有区别, 只是Remove的value被设定为空以标识数据的删除。
1.3 Get 操作流程
Get操作流程如下:
- 先在
Memtable中查找, 如果找到则直接返回。- 优先查找活跃跳表
current_table - 其次尝试查找
frozen_tables, 按照id倒序查找(因为id越小, 表示SkipList越旧)
- 优先查找活跃跳表
- 如果在
Memtable中未找到, 则在SST中查找。- 先在
Level 0层查找, 如果找到则直接返回。注意的是,Level 0层不懂的SST没有进行排序, 因此需要按照SST的id倒序逐个查找(因为id越小, 表示SST越旧, 优先级越低) - 随后逐个在后面的
Level层查找, 此时所有的SST都已经进行过排序, 因此可在Level层面进行二分查询。
- 先在
- 如果
SST中为查询到, 返回。
至此,你对LSM Tree的CRUD操作流程有了一个初步的印象, 如果你现在看不懂的话, 没关系。后续的Lab中会对每个模块有详细的讲解。
2. LSM Tree VS B-Tree
接下来对比分析一下LSM Tree 和 B-Tree。B-Tree 和 LSM-Tree 是两种最常用的存储数据结构,广泛应用于各种数据库和存储引擎中。
2.1 B-Tree 概述
2.1.1 基本结构
- 多路搜索树:每个节点可包含多个键值对及对应子节点指针。
- 页(Page)存储:通常以固定大小页(如 4 KB)为单位,将数据保存在叶子节点或中间节点中。
2.1.2 读写流程
- 查找:从根节点开始,依次向下比较键值,直到叶子节点。
- 写入:在页内定位并修改;若页已满,则分裂节点并向上调整,保持树的平衡。
2.1.3 性能特点
- 查找:时间复杂度 O(log n),适合读密集型应用。
- 写入:每次随机写与节点分裂会带来较高的 I/O 开销,不利于写密集型场景。
2.2. LSM-Tree 概述
2.2.1 设计动机
为了解决传统 B-Tree 在写密集场景下的随机写和高写放大问题,LSM-Tree 采取“先内存写、再后台合并”的思路,以空间换时间,提升写入吞吐。
2.2.2 主要组件与流程
- MemTable(内存表):所有写操作首先追加到内存中的有序结构(如跳表)。
- SSTable(磁盘表):当 MemTable 达到阈值时,将其定期刷新为只读的磁盘文件。
- 后台 Compaction(合并):将多个旧的 SSTable 合并、去重,并生成新的 SSTable,控制文件数量与数据冗余。
2.2.3 优化手段
- Bloom Filter:快速判断某 key 是否存在于某个 SSTable,减少不必要的磁盘查找。
- Index Block / Block Cache:缓存热点数据页,加速读请求。
- Tiered / Leveled Compaction:通过分层或分阶段合并,平衡写放大与读放大。
2.3. B-Tree vs. LSM-Tree 对比
| 特性 | B-Tree | LSM-Tree |
|---|---|---|
| 写入模式 | 随机写,页内更新,可能分裂节点 | 顺序写(追加),后台合并 |
| 写放大 | 较低 | 较高(受合并策略影响) |
| 读取路径 | 单次树搜索 | 多级查找(MemTable + 多个 SSTable + 合并) |
| 读写性能场景 | 读密集型 | 写密集型 |
| 磁盘友好性 | 随机 I/O | 顺序 I/O,更适合 SSD |
小结:LSM-Tree 在写入吞吐上优于 B-Tree,但读取延迟与 I/O 成本相对更高。 更深入的对比分析可以阅读: https://tikv.org/deep-dive/key-value-engine/b-tree-vs-lsm/
2.4 常见系统及应用场景
| 存储引擎 / 数据库 | 类型 |
|---|---|
| LevelDB | 嵌入式 KV 存储引擎 |
| RocksDB | KV 存储引擎 |
| HyperLevelDB | 分布式 KV 存储 |
| PebbleDB | 嵌入式 KV 存储 |
| Cassandra | 分布式列存储数据库 |
| ClickHouse | 分析型数据库 |
| InfluxDB | 时间序列数据库 |
2.5 LSM-Tree 优化研究
LSM Tree自1997年提出后,有很多研究人员在LSM Tree的基础上进行了改进,部分代表性工作比如:
RocksDB, LevelDB:经典的LSM Based KV存储引擎.
WiscKey: Separating Keys from Values in SSD-Conscious Storage:分离 Key 和 Value,降低写放大
Monkey: Optimal Bloom Filters and Tuning for LSM-Trees:优化布隆过滤器分配策略,减少读放大
这里不再进行详细介绍,感兴趣的可以阅读相关论文。