本章是对目前的LSM Tree功能的补全, 提供全局的迭代器遍历功能。
代码仓库:ToniXWD/toni-lsm: A KV storage engine based on LSM Tree, supporting Redis RESP 感谢您的 Star!
欢迎支持本项目同步更新的从零开始实现的视频教程:https://avo6166ew2u.feishu.cn/docx/LXmVdezdsoTBRaxC97WcHwGunOc
欢迎加入讨论群:Toni-LSM项目交流群
1 架构回顾
首先回顾LSM Tree的架构:
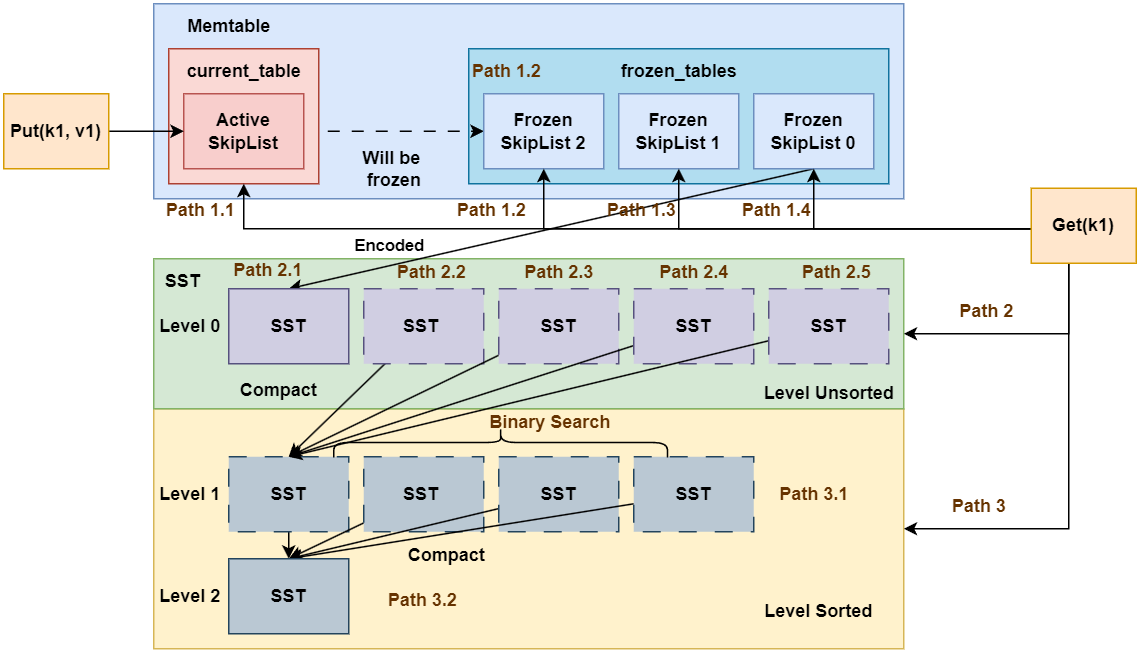
可以看到, 越靠近左上角的组件, 优先级越高, 在查询时我们按照优先级依次从active skiplist、frzozen skiplist、l0 sst、l1 sst中查找, 如果查到就返回, 否则继续向下查找。
但我们要实现全局迭代器就会存在问题, 有点key只在底层的sst中存在, 有的key同时在多个sst和skiplist中存在(此时需要按照优先级进行滤除)。同时,我们还需要考虑到事务id的可见性对某些重复的键值对进行屏蔽。因此,我们需要实现一个全局的迭代器,将以上组件进行串联,最终实现全局迭代器。
2 全局迭代器的设计
2.1 数据结构设计
由于前述分析可知, 我们的这个迭代器就是按照优先级的不同, 将不同组件的迭代器进行逐次遍历, 因此其需要将不同组件的优先级进行区分, 这里可以采用将各个组件的迭代器按序存入一个vector实现, 每个迭代器在vector中的位置就是其优先级, 因此, 我们如下定义头文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
#pragma once
#include "../iterator/iterator.h"
#include <memory>
#include <optional>
#include <shared_mutex>
class LSMEngine;
class Level_Iterator : public BaseIterator {
public:
Level_Iterator() = default;
Level_Iterator(std::shared_ptr<LSMEngine> engine_, uint64_t max_tranc_id);
virtual BaseIterator &operator++() override;
virtual bool operator==(const BaseIterator &other) const override;
virtual bool operator!=(const BaseIterator &other) const override;
virtual value_type operator*() const override;
virtual IteratorType get_type() const override;
virtual uint64_t get_tranc_id() const override;
virtual bool is_end() const override;
virtual bool is_valid() const override;
BaseIterator::pointer operator->() const;
private:
std::shared_ptr<LSMEngine> engine_;
std::vector<std::shared_ptr<BaseIterator>> iter_vec;
size_t cur_idx_;
uint64_t max_tranc_id_;
mutable std::optional<value_type> cached_value;
std::shared_lock<std::shared_mutex> rlock_;
private:
void update_current() const;
std::pair<size_t, std::string> get_min_key_idx() const;
void skip_key(const std::string &key);
};
|
其中, 这里最重要的数据结构就是:
1
| std::vector<std::shared_ptr<BaseIterator>> iter_vec
|
其存储了不同组件的迭代器指针, 因为这里所有迭代器都是BaseIterator的父类, 所以我们可以对各种算法或子迭代器类进行良好的代码复用。
另外cur_idx_标记当前迭代器应该选择哪一个组件的迭代器进行输出, 也就是当前生效的迭代器在iter_vec中的索引。其余数据结构就是一些简单的记录, 比如获取父engine的智能指针、当前查询事务id、锁和缓存键值对等。
2.2 构造函数
构造函数中需要构建这个item_vec, 也就是初始化各个组件的迭代器, 代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
Level_Iterator::Level_Iterator(std::shared_ptr<LSMEngine> engine,
uint64_t max_tranc_id)
: engine_(engine), max_tranc_id_(max_tranc_id), rlock_(engine_->ssts_mtx) {
auto mem_iter = engine_->memtable.begin(max_tranc_id_);
std::shared_ptr<HeapIterator> mem_iter_ptr = std::make_shared<HeapIterator>();
*mem_iter_ptr = mem_iter;
iter_vec.push_back(mem_iter_ptr);
std::vector<SearchItem> item_vec;
for (auto &sst_id : engine_->level_sst_ids[0]) {
auto sst = engine_->ssts[sst_id];
for (auto iter = sst->begin(max_tranc_id_);
iter.is_valid() && iter != sst->end(); ++iter) {
if (max_tranc_id_ != 0 && iter.get_tranc_id() > max_tranc_id_) {
continue;
}
item_vec.emplace_back(iter.key(), iter.value(), -sst_id, 0,
iter.get_tranc_id());
}
}
std::shared_ptr<HeapIterator> l0_iter_ptr =
std::make_shared<HeapIterator>(item_vec, max_tranc_id);
iter_vec.push_back(l0_iter_ptr);
for (auto &[level, sst_id_list] : engine_->level_sst_ids) {
if (level == 0) {
continue;
}
std::vector<std::shared_ptr<SST>> ssts;
for (auto sst_id : sst_id_list) {
auto sst = engine_->ssts[sst_id];
ssts.push_back(sst);
std::shared_ptr<ConcactIterator> level_i_iter =
std::make_shared<ConcactIterator>(ssts, max_tranc_id);
iter_vec.push_back(level_i_iter);
}
}
}
|
这里迭代器包括:
- 内存迭代器
mem_iter: 就是遍历整个内存中的键值对, 并使用HeapIterator进行排序和去重, HeapIterator就是使用了一个堆结构, 将所有键值对按照优先级进行排序, 并且去重, 具体内容可以参见之前的第8章。
L0层迭代器l0_iter_ptr: 由于L0这一层的SST之间不是排序且无重叠的, 因此这里同样要求进行去重, 我们仍然使用了HeapIterator实现去重和排序, 这一实现方案存在一定缺陷, 因为L0的数据量还是不小的, 后续可以考虑在这一层嵌套一个Level_Iterator, 因为L0这一层的SST也是按照先后优先级进行排序的, 符合Level_Iterator的迭代器设计原则, 可以减少内存开销。- 其余
Level的迭代器level_i_iter: 其余层的迭代器都是按照SST的先后顺序进行排序的, 因此这里直接使用ConcactIterator进行迭代即可, ConcactIterator就是将多个迭代器进行拼接, 并且按照sst的id顺序作为优先级进行排序, 不需要进行额外的去重操作, 且支持惰性的文件IO读取, 避免了文件IO开销。ConcactIterator的内容可以参考第19章中的介绍。
注意代码中的..., 这是非常重要的步骤, 后续进行介绍
2.2 自增运算符重载
2.2.1 整体重载逻辑
这里的自增操作的逻辑就是将iter_vec中解引用后等于当前key的迭代器进行自增, 这里的逻辑是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
BaseIterator &Level_Iterator::operator++() {
skip_key(cached_value->first);
while (!is_end()) {
auto [min_idx, _] = get_min_key_idx();
cur_idx_ = min_idx;
update_current();
if (cached_value->second.size() == 0) {
skip_key(cached_value->first);
continue;
} else {
break;
}
}
return *this;
}
|
首先, 需要将当前活跃的key所属的迭代器进行自增, 也就是skip_key函数所做的事儿:
1
2
3
4
5
6
7
8
9
|
void Level_Iterator::skip_key(const std::string &key) {
for (size_t i = 0; i < iter_vec.size(); ++i) {
while ((*iter_vec[i]).is_valid() && (**iter_vec[i]).first == key) {
++(*iter_vec[i]);
}
}
}
|
这里不仅要将当前key所属的活跃迭代器进行自增, 其余解引用后拥有相同key的迭代器也要进行自增, 因为多个迭代器存在相同的key是允许的情况, 只是由于不同迭代器在数组中索引不同或其事务id不同, 才导致只有一个活跃迭代器被选中(即cur_idx_指向的迭代器)。
2.2.2 重新选择迭代器
在对原本的当前迭代器的key进行自增后, 需要重新选择当前key最小的迭代器, 也就是重新选择当前key所属的迭代器, 也就是Level_Iterator::operator++()代码中的while循环部分。这里的逻辑是,只要当前迭代器没有到达end, 就选择所有迭代器中key最小的迭代器作为当前迭代器, 这家就是get_min_key_idx的逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
std::pair<size_t, std::string> Level_Iterator::get_min_key_idx() const {
size_t min_idx = 0;
std::string min_key = "";
for (size_t i = 0; i < iter_vec.size(); ++i) {
if (!iter_vec[i]->is_valid()) {
continue;
} else if (min_key == "") {
min_key = (**iter_vec[i]).first;
min_idx = i;
} else if ((**iter_vec[i]).first < (**iter_vec[min_idx]).first) {
min_key = (**iter_vec[i]).first;
min_idx = i;
} else if ((**iter_vec[i]).first == min_key) {
if (max_tranc_id_ != 0) {
if ((*iter_vec[i]).get_tranc_id() >
(*iter_vec[min_idx]).get_tranc_id()) {
min_idx = i;
}
}
}
}
return std::make_pair(min_idx, min_key);
}
|
get_min_key_idx在比较key之前, 还需判断迭代器是否有效, 比较key之后还需要判断事物id的可见性, 这里的max_tranc_id_就是当前事务id, 其查询到的事务的id不能比这个事务id大, 否则该事务的记录是不可见的。
2.2.3 构造函数的补全
之前提到了, 构造函数中的...部分需要进行补全, 原因就是, 默认的cur_idx_为0, 但第0个迭代器可能是删除标记,也可能齐全key不是最小的, 又或者其事务id对当前迭代器不可见, 因此也需要进行初始迭代器的选举和滤除:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
Level_Iterator::Level_Iterator(std::shared_ptr<LSMEngine> engine,
uint64_t max_tranc_id)
: engine_(engine), max_tranc_id_(max_tranc_id), rlock_(engine_->ssts_mtx) {
while (!is_end()) {
auto [min_idx, _] = get_min_key_idx();
cur_idx_ = min_idx;
update_current();
auto cached_kv = *cached_value;
if (cached_kv.second.size() == 0) {
skip_key(cached_value->first);
continue;
} else {
break;
}
}
}
|
2.3 解引用运算符重载
这部分就很简单了, 直接获取缓存值即可, 缓存值会在构造函数以及后续每一次自增时进行更新:
1
2
3
4
5
6
7
|
BaseIterator::value_type Level_Iterator::operator*() const {
if (!cached_value.has_value()) {
throw std::runtime_error("Level_Iterator is invalid");
}
return *cached_value;
}
|
3 全局迭代器的接口
现在我们可以在上层组件中暴露begin和end来获取当前迭代器的全局接口了:
1
2
3
4
5
6
|
Level_Iterator LSMEngine::begin(uint64_t tranc_id) {
return Level_Iterator(shared_from_this(), tranc_id);
}
Level_Iterator LSMEngine::end() { return Level_Iterator{}; }
|
我们可以在外部如下使用全局迭代器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#include "../include/lsm/engine.h"
#include "../include/lsm/level_iterator.h"
#include <iostream>
#include <string>
int main() {
LSM lsm("example_data");
std::cout << "All key-value pairs:" << std::endl;
for (auto it = lsm.begin(0); it != lsm.end(); ++it) {
std::cout << it->first << ": " << it->second << std::endl;
}
return 0;
}
|
4 小节
本小节没有什么复杂的内容, 就是赋予不同组件的迭代器不同的优先级, 将其整合形成一个更高级的迭代器。通过这章的学习,相比大家对于C++中迭代器的理解应该会更加清晰, 迭代器是不同组件信息交流的桥梁, 非常重要。
本项目的初版差不多已经完结了,后续会不定期更新一些功能的补全。然后会开一个新坑————基于目前的单机的存储引擎Toni-LSM, 进行raft或curp共识算法的封装, 最终形成一个分布式数据库。(不知道什么时候开坑,速度可能有点慢,但肯定不会鸽)。
如果本项目有帮到你,请给个star吧,您的支持是我继续维护和开发这个项目的动力。如果你想自己从零开始手敲代码实现这个项目,欢迎支持我的付费视频课程:https://avo6166ew2u.feishu.cn/docx/LXmVdezdsoTBRaxC97WcHwGunOc