之前我们已经完成了数据库内存中事务和崩溃恢复相关的功能实现, 这节课不出意外应该是LSM Tree核心组件的最后一节课, 即介绍SSTable Compact相关功能的实现。
代码仓库:ToniXWD/toni-lsm: A KV storage engine based on LSM Tree, supporting Redis RESP 感谢您的 Star!
欢迎支持本项目同步更新的从零开始实现的视频教程:https://avo6166ew2u.feishu.cn/docx/LXmVdezdsoTBRaxC97WcHwGunOc
欢迎加入讨论群:Toni-LSM项目交流群
1. SST Compact 基本概念
首先, 让我们再次回顾LSM Tree的架构:
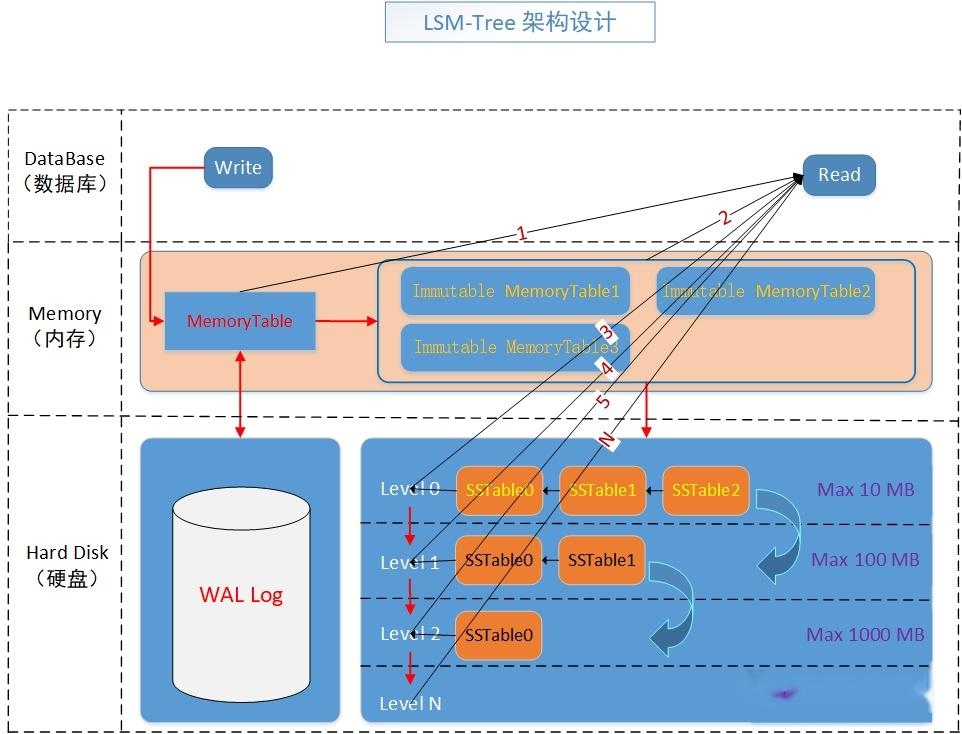
在LSM(Log-Structured Merge)树中,数据最初写入一个称为 memtable 的内存结构。一旦 memtable 达到一定大小限制,其内容会被刷写到磁盘上作为 SSTable(Sorted String Table)。随着时间的推移,可能会在 LSM 树的不同层级积累多个 SSTable。这些 SSTable 可能会导致以下问题:
- 读放大:查询一个键时,系统可能需要搜索多个不同层级的 SSTable。这会增加 I/O 操作次数,从而降低读取性能。
- 写放大:频繁的写操作生成新的 SSTable,最终需要与现有 SSTable 合并。如果没有压缩,这会导致过多的磁盘写入。
- 空间放大:被删除或覆盖的键可能仍然存在于旧的 SSTable 中,直到它们通过压缩被清除。这浪费了磁盘空间。
为了解决这些问题,需要进行 压缩(compaction)。压缩将较小的 SSTable 合并成较大的 SSTable,移除过时的数据(如已删除或覆盖的键),并平衡各层级之间的数据分布。
2. 经典的SST压缩方案
这里先介绍一些经典的SST压缩方案。
2.1 基于大小的分层压缩(Size-Tiered Compaction)
这种方案按大小和层级对 SSTable 进行分组。每一层包含大致相同大小的 SSTable。当某一层的 SSTable 数量超过阈值时,它们会被合并成一个或多个 SSTable 并移动到下一层。
流程:
- 将 Level L 的 SSTable 合并成一个或多个 SSTable 并移动到 Level L+1。
- 如果必要,递归执行此过程。
优点:
- 实现简单。
- 高效处理高写入吞吐量。
缺点:
- 可能导致显著的读放大,因为单次查询可能需要扫描多个层级。
示意图:
1
2
3
4
5
6
7
8Level 0: [SST1] [SST2] [SST3]
Level 1: [SST4] [SST5]
Level 2: [SST6]
压缩后:
Level 0: []
Level 1: [Merged(SST1,SST2,SST3)]
Level 2: [SST6]
2.2 分层压缩(Leveled Compaction)
这种方案将 SSTable 分布在不同的层级,确保每个层级包含固定数量的数据。较低层级的数据以小块形式逐步移动到较高层级。
流程:
- 将 Level L 的 SSTable 按键范围拆分成更小的部分,并与 Level L+1 中重叠的 SSTable 合并。
- 每次压缩只影响 Level L+1 中的一小部分 SSTable。
优点:
- 相比基于大小的分层压缩,减少了读放大。
- 确保每个层级的键范围不重叠。
缺点:
- 实现复杂度更高。
- 频繁的小规模合并导致较高的写放大。
示意图:
1
2
3
4
5
6
7
8Level 0: [SST1] [SST2] [SST3]
Level 1: [RangeA] [RangeB] [RangeC]
Level 2: [RangeD] [RangeE]
压缩后:
Level 0: []
Level 1: [Merged(SST1,RangeA)] [Merged(SST2,RangeB)] [Merged(SST3,RangeC)]
Level 2: [RangeD] [RangeE]
2.3 混合压缩(Hybrid Compacti2.3)
一些系统结合了基于大小的分层压缩和分层压缩的优点。例如,前几层使用基于大小的分层压缩,而较深层级切换到分层压缩。
优点:
- 在读放大和写放大之间取得平衡。
- 根据工作负载特性提供灵活性。
缺点:
- 管理多种压缩策略增加了复杂性。
3 本项目 SST Compact 设计
本项目的compact机制采用了一种混合方法,主要在第0层使用基于大小的分层压缩,而在更高层则转向分层压缩。以下是详细的设计说明:
3.1 触发压缩的时机
- Level 0:如果 Level 0 的 SSTable 数量超过一个阈值
LSM_SST_LEVEL_RATIO,则触发全量压缩,将所有 Level 0 的 SSTable 移动到 Level 1。 - 更高层:如果某一层的 SSTable 数量超过
LSM_SST_LEVEL_RATIO,系统会递归检查下一层是否也需要压缩,然后继续执行。
这里重点解释一下 LSM_SST_LEVEL_RATIO的含义, 它的含义是相邻两层的单个SST容量之比, 同时也是单层SST数量的阈值。这里我为了方便压缩触发的条件判断的便捷性, 规定每一个Level的SST数量阈值恒定。例如, 每层SST数量超过16时就需要进行compact, 这一层16个SST被合并为下一层的单个SST, 因此这个单个SST的容量是上一个Level中单个SST的容量的16倍。这个案例中, LSM_SST_LEVEL_RATIO就是16。
3.2 递归压缩
确定源层和目标层:
- 确定源层 (
src_level) 和目标层 (src_level + 1)。 - 获取这两层的 SSTable ID。
- 确定源层 (
判断是否进行递归压缩
- 由于
src_level层是触发了这一次compact操作, 因此其SST数量肯定大于等于LSM_SST_LEVEL_RATIO - 但还需要判断目标层(
src_level + 1)的SST数量是否大于等于LSM_SST_LEVEL_RATIO。如果时, 则需要先将src_level + 1层的SST全部压缩到src_level + 2层 - 上述的判断递归地在更高的
Level中进行
- 由于
合并SSTable:
- 对于
Level 0,由于其不同SST中的key有重叠, 需要使用full_l0_l1_compact处理键范围重叠的问题 - 对于更高层, 其
key本来就是从小大大排布的, 使用full_common_compact合并不重叠键范围的SSTable。
- 对于
生成新SSTable:
- 使用
gen_sst_from_iter从合并后的迭代器结果生成新的 SSTable。 - 确保新 SSTable 的大小符合
get_sst_size定义的限制。
- 使用
更新元数据:
- 删除旧的 SSTable(从内存和磁盘中移除)。
- 将新的 SSTable 添加到适当的目标层。
- 更新
level_sst_ids并对其进行排序以便高效访问。
这里的
full_l0_l1_compact和full_common_compact会在后文中介绍
关键特性
- 事务处理:在压缩过程中,确保只将可见记录(基于事务ID)包含在新的 SSTable 中。
- 并发控制:使用锁(
std::shared_mutex)防止在访问共享资源(如ssts_mtx)时发生竞争条件。 - 高效迭代:利用迭代器(
TwoMergeIterator、HeapIterator、ConcactIterator)高效遍历和合并来自多个 SSTable 的数据。
示例流程
假设初始状态如下:
压缩前:
1
2
3Level 0: [SST1] [SST2] [SST3]
Level 1: [SST4] [SST5]
Level 2: [SST6]触发条件:Level 0 有三个 SSTable,超过了阈值(
LSM_SST_LEVEL_RATIO = 2)。压缩过程:
- 合并
[SST1]、[SST2]和[SST3]成为一个迭代器。 - 将该迭代器的结果与
[SST4]和[SST5]从 Level 1 中合并。 - 生成新的 SSTable 并将其分配到 Level 1。
- 合并
压缩后:
1
2
3Level 0: []
Level 1: [NewSST1] [NewSST2]
Level 2: [SST6]
4 本项目 SST Compact 代码实现
在介绍完之前的流程后, 本项目compact部分的代码就很好理解了
4.1 触发时机
由于本项目是一个教学项目, 教学项目最好是便于学习者进行Debug, 因此, 我将compact触发设计为惰性的同步触发机制, 这样最便于大家单步调试。因此,我们需要再每次SST刷盘时进行compact的触发检查:
1 | // src/lsm/engine.cpp |
这里当然存在一个并发问题, 就是刷盘时我们获取了一把锁ssts_mtx, 这里是对读写锁获取写锁, 因此, 在我们目前的实现中, sst压缩时, 其他SST的查询是被阻塞的。这里其实可以用如下的方案来解决这个并发问题:
compact时, 先将ssts_mtx锁换成读锁, 这样其他线程可以查询SST- 刷盘后的
sst文件进行原子重命名, 因此只在文件重命名时需要获取锁
这样就解决了并发问题, 不过需要注意的就是, 这里的压缩函数会递归地进行, 因此这里重命名的过程较为琐碎。介于目前的项目主要是作为教学项目存在,且本人实在精力有限, 因此我没有实现这个优化,感兴趣的朋友可尝试下,欢迎来提PR
4.2 相邻层的压缩
4.2.1 整体压缩逻辑
full_compact处理相邻层压缩的整体逻辑, 即遍历相邻层的迭代器, 将键值对打到新的SST中:
1 | // src/lsm/engine.cpp |
具体而言, LSMEngine::full_compact 函数的目标是将指定层级 src_level 的所有 SSTable 压缩到下一层级 src_level + 1,并通过合并和优化减少冗余数据,提升读写性能。其步骤为:
a. 递归检查下一层是否需要压缩
- 在对当前层级(
src_level)进行全量压缩之前,先检查下一层级(src_level + 1)是否也需要进行全量压缩。 - 如果
src_level + 1层的 SSTable 数量超过阈值(LSM_SST_LEVEL_RATIO),则递归调用full_compact(src_level + 1)对下一层进行压缩。 - 这种递归机制确保了在压缩当前层之前,目标层已经处于优化状态。
b. 获取源层级和目标层级的 SSTable ID
- 从
level_sst_ids[src_level]和level_sst_ids[src_level + 1]中分别获取当前层级和目标层级的所有 SSTable ID。 - 将这些 ID 转换为两个向量:
lx_ids(源层级)和ly_ids(目标层级),便于后续处理。
c. 根据层级选择不同的压缩方式
- 根据
src_level是否为 Level 0,选择不同的压缩方法:- Level 0:由于 Level 0 的 SSTable 可能存在键范围重叠,调用
full_l0_l1_compact(lx_ids, ly_ids)处理。 - 其他层级:调用
full_common_compact(lx_ids, ly_ids, src_level + 1)处理,这些层级的 SSTable 键范围不重叠。
- Level 0:由于 Level 0 的 SSTable 可能存在键范围重叠,调用
d. 移除旧的 SSTable
- 压缩完成后,删除源层级和目标层级中所有旧的 SSTable:
- 调用
del_sst()方法释放磁盘资源。 - 从
ssts映射中移除这些 SSTable。
- 调用
- 清空
level_sst_ids[src_level]和level_sst_ids[src_level + 1],为新生成的 SSTable 准备空间。
e. 更新最大层级
- 更新
cur_max_level,确保其始终表示当前 LSM 树中的最大层级。
f. 添加新的 SSTable
- 将新生成的 SSTable 添加到目标层级(
src_level + 1):- 将新 SSTable 的 ID 插入到
level_sst_ids[src_level + 1]。 - 将新 SSTable 本身插入到
ssts映射中。
- 将新 SSTable 的 ID 插入到
- 对
level_sst_ids[src_level + 1]进行排序,确保 SSTable 按顺序存储,便于高效访问。
4.2.2 L0-L1层的压缩
full_l0_l1_compact函数处理Level 0层和Level 1层之间的压缩,Level 0层和Level 1层之间的SSTable的key有重叠,因此需要处理键范围重叠的问题:
1 | // src/lsm/engine.cpp |
这里, 我们又复用了HeapIterator对Level 0不同的sst进行相同key的去重; 然后再与Level 1的sst的迭代器进行遍历, 随遍历流程构建新的SST(gen_sst_from_iter的处理)。需要注意的是,这里两个迭代器的遍历过程中,使用了TwoMergeIterator, 这里的迭代器泛型是HeapIterator和ConcactIterator的组合,实现了两个迭代器的按照不同优先级的遍历。
从这里也可以看出,我们为什么要在之前进行迭代器的统一, 就是为了借助C++的多态特性实现算法的高效复用。
4.2.3 Lx-Lx+1 层的压缩
full_common_compact函数完成其他层级的压缩, 其他的每一层, 不同sst之间的key都是从小大大排序的, 且无重叠。因此,则需要简单地迭代遍历即可:
1 | // src/lsm/engine.cpp |
这里要做的, 就是使用TwoMergeIterator, 按照低层级优先的规则, 迭代遍历lx_iters(Level x层的迭代器)和ly_iters(Level y层的迭代器, y = x + 1)。
4.3 SST的构建
最后, 就是遍历迭代器时新SST的构建:
1 | // src/lsm/engine.cpp |
这里构建SST没有什么别的好讲的, 就是不断地将键值对插入到SSTBuilder中, 当超出阈值后就刷盘形成SST
4 Block缓存池的被动失效
这里大家可能注意到一个非常有意思的事情:SST_id的分配是单调递增的
也就是说, SST_0被压缩后, 其新合并的SST的id不会复用之前的SST的id, 举个例子:
假设初始时, 有三个Level 0的SST和一个Level 1的SST, 且LSM_SST_LEVEL_RATIO=3, 那么压缩前, 其状态为:
1 | L0: SST_6, SST_5, SST_4 |
压缩后, 其状态为:
1 | L1: SST_8, SST_7 |
这里, SST_6, SST_5, SST_4和SST_3一起被压缩, 其新合并的SST的id为SST_8, SST_7, 他们不会复用之前的SST_id, 为什么如此设计呢? 主要是考虑到缓存池失效的问题, 这里回顾一下我的的缓存池设计:
1 | std::shared_ptr<Block> SST::read_block(size_t block_idx) { |
这里, 从缓存池中查找时, 唯一标识block的信息就是sst_id和block_idx。 因此, 如果我们compact后复用之前的SST_id, 且block_cache中就存在了compact前的SST相同的SST_id, 在compact后SST_id已经发生了变化, 这是缓存池中的block就会索引到已经被删掉的compact前的SST中的block, 导致得到过时的缓存block。
为了解决这里缓存失效的问题,我将sst_id设计为单调递增的, 这样, 在compact后, SST_id不会复用之前的SST_id, 随着缓存池的访问, 之前已经被compact的SST的无效缓存记录逐渐被清空, 同时,没有compact部分的SST的缓存block依然有效。
假设我们复用sst_id的话, 那么在compact后我们需要手动清理掉旧SST的无效缓存, 这不但需要我们记录哪些SST已经被compact了, 且需要对我们的Block Cache进行侵入式的代码修改, 并且主动修改缓存的设计本来就不够优雅, 且耗费性能。
5 总结
本章主要讲了LSM Tree的SST压缩算法的设计, 并且实现了一个简单的LSM Tree的SST压缩算法。到此为止,我们的LSM Tree的所有组件都已经完成了, 本项目已经接近尾声了, 接下来可能会补充一点细节优化和bug修复的内容。如果大家感兴趣,可能也会更一些利用本项目进行简历包装的指导。
写到这里,本项目已经有20篇文章了(Lec00-Lec19),一开始自己只是打算对自己过往几年对存储和数据库领域学习的知识进行简单整理, 但没想到逐渐写出来一个较为复杂的项目, 也耗费了自己不少的心血, 项目统计代码行数都接近1W了:
1 | ✗ cloc . |
在此也非常感谢各位网友的支持, 如果你对本项目感兴趣, 欢迎点个Star, 也欢迎你将本项目推荐给更多的网友, 让更多人了解这个项目。同时, 将本项目用在自己实习或秋招的简历上也是可以的。如果想进一步支持一下一贫如洗的作者, 可以购买作者录制的付费版视频课程