之前基于我们目前已有的LSM Tree存储引擎, 实现了Redis的kv, hash, list, 本章继续实现剩下的set, zset. 本章完成后, 可以得到一个包含Redis基础功能的简易版redis-server
代码仓库:ToniXWD/toni-lsm: A KV storage engine based on LSM Tree, supporting Redis RESP
欢迎点个Star
1 Redis ZSet 实现 1.1 实现思路 这里也不介绍Redis zset的语法了, 既然看这篇文章, 相比大家对Redis非常熟悉了, 这里我选择实现如下常见的api:
zaddzremzrangezcardzscorezincrbyzrank
我们可以看出, zset最大的难点就是需要双向的查询索引: 既要能够通过zscore查询指定成员的分数, 也要能够通过zrank、zrange按照分数排序。对于按照分数排序查询, 由于我们的LSM Tree本来就是按照key排序的, 所以我们只需要将所有的成员按照他们的分数构建一个符合顺序的key就可以了; 对于按照成员查询分数, 我们只能再额外存储一个key.
因此我们使用如下的方案:
整个zset控制结构的键值对只标记其存在, 不在value中存储有效信息(但不能为空, 因为value为空表示被删除)
需要存储(score, elem)键值对, score为固定的前缀+key+真正的score拼接而成
需要存储(elem, score)键值对, elem为固定的前缀+key+真正的elem拼接而成
需要注意的是score为固定的前缀+key+真正的score拼接而成, 为保证这个key在我们的LSM Rree中排序符合score的顺序, 这个score我们限制器为整型数, 且其长度对其到32位, 否则如果支持小数的话, 排序和解析就会复杂很多
1.2 TTL 类似上一章的TTL设计, 我们需要为这个zset也实现TTL机制. 首先需要明白, Redis 的 TTL 只能对整个键(key)设置过期时间,而不能针对列表(list)、集合(set)、哈希(hash)等数据结构中的单个成员单独设置过期时间。
类似上一章节的lsit和hash的工作流程, 我们每次读写zset时, 都需要检查TTL是否过期, 如果过期, 则删除zset:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 bool RedisWrapper::expire_zset_clean ( const std::string &key, std::shared_lock<std::shared_mutex> &rlock) std::string expire_key = get_explire_key (key); auto expire_query = this ->lsm->get (expire_key); if (is_expired (expire_query, nullptr )) { rlock.unlock (); std::unique_lock<std::shared_mutex> wlock (redis_mtx) ; lsm->remove (key); lsm->remove (expire_key); auto preffix = get_zset_key_preffix (key); auto result_elem = this ->lsm->lsm_iters_monotony_predicate ( [&preffix](const std::string &elem) { return -elem.compare (0 , preffix.size (), preffix); }); if (result_elem.has_value ()) { auto [elem_begin, elem_end] = result_elem.value (); std::vector<std::string> remove_vec; for (; elem_begin != elem_end; ++elem_begin) { remove_vec.push_back (elem_begin->first); } lsm->remove_batch (remove_vec); } return true ; } return false ; }
这里的逻辑几乎和之前hash的清理工作一致, 这里也不再介绍锁升级和锁冲突等注意事项了, 这里的重点就是我们的前兆查询部分:
1 2 3 4 auto result_elem = this ->lsm->lsm_iters_monotony_predicate ( [&preffix](const std::string &elem) { return -elem.compare (0 , preffix.size (), preffix); });
这里的前缀查询的目的, 就是在查询中指定当前方向, 如果LSM Tree中查询的某个位置(例如二分查询的位置)比目标更大, 则应该王小的方向移动查询位置, 返回一个负值, 反之如果查询位置比目标小, 则应该向大的方向移动查询位置, 返回一个正值, 否则返回0, 这样我们的查询就会按照目标方向进行查询, 直到查询到目标为止.
这里的lsm_iters_monotony_predicate会返回start和end的迭代器, 我们只需要遍历这个迭代器, 就可以得到所有满足条件的key了
1.3 zadd zadd的逻辑是:
查询TTL判断是否过期并进行清理工作
如果zset不存在或者过期, 则新建一个zset的控制结构的键值对
插入score, elem的键值对
插入elem, score的键值对
需要先判断elem是否存在, 如果存在, 则需要删除旧的score, elem键值对
但不需要删除旧的elem, score键值对, 因为其会被本次操作覆盖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 std::string RedisWrapper::redis_zadd (std::vector<std::string> &args) { std::string key = args[1 ]; std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_zset_clean (key, rlock); if (!is_expired) { rlock.unlock (); } std::unique_lock<std::shared_mutex> lock (redis_mtx) ; std::vector<std::pair<std::string, std::string>> put_kvs; std::vector<std::string> del_keys; auto value = get_zset_key_preffix (key); if (!lsm->get (value).has_value ()) { put_kvs.emplace_back (key, value); } std::vector<std::string> remove_keys; int added_count = 0 ; for (size_t i = 2 ; i < args.size (); i += 2 ) { std::string score = args[i]; std::string elem = args[i + 1 ]; std::string key_score = get_zset_key_socre (key, score); std::string key_elem = get_zset_key_elem (key, elem); auto query_elem = lsm->get (key_elem); if (query_elem.has_value ()) { std::string original_score = query_elem.value (); if (original_score == score) { continue ; } std::string original_key_score = get_zset_key_socre (key, original_score); remove_keys.push_back (original_key_score); } put_kvs.emplace_back (key_score, elem); put_kvs.emplace_back (key_elem, score); added_count++; } lsm->remove_batch (del_keys); lsm->put_batch (put_kvs); return ":" + std::to_string (added_count) + "\r\n" ; }
这里值得注意的一个点是我们采用了remove_batch和put_batch来批量删除和插入, 这样可以减少锁的持有时间, 提高性能. 其实也就是写到这里是才更新的逻辑, 之前的lsit, hash都可以采用这样的批量接口, 但当时没有实现相应的接口, 有兴趣可以完善之前的lsit和hash使其也使用这样的批量接口
1.4 zrem zrem的逻辑是:
查询TTL判断是否过期并进行清理工作
如果zset不存在或者过期, 则直接返回0
删除score, elem的键值对
删除elem, score的键值对
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 std::string RedisWrapper::redis_zrem (std::vector<std::string> &args) { if (args.size () < 3 ) { return "-ERR wrong number of arguments for 'zrem' command\r\n" ; } std::string key = args[1 ]; std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_zset_clean (key, rlock); if (is_expired) { return ":0\r\n" ; } rlock.unlock (); std::unique_lock<std::shared_mutex> lock (redis_mtx) ; int removed_count = 0 ; for (size_t i = 2 ; i < args.size (); ++i) { std::string elem = args[i]; std::string key_elem = get_zset_key_elem (key, elem); auto query_elem = lsm->get (key_elem); if (query_elem.has_value ()) { std::string score = query_elem.value (); std::string key_score = get_zset_key_socre (key, score); lsm->remove (key_elem); lsm->remove (key_score); removed_count++; } } return ":" + std::to_string (removed_count) + "\r\n" ; }
1.5 zrange zrange直接进行前缀查询就可以了, TTL判定的逻辑是一样的, 也需要注意索引为负数这样表示从尾部想头部遍历这样的操作, 需要将索引转化为正数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 std::string RedisWrapper::redis_zrange (std::vector<std::string> &args) { std::string key = args[1 ]; int start = std::stoi (args[2 ]); int stop = std::stoi (args[3 ]); std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_zset_clean (key, rlock); if (is_expired) { return "*0\r\n" ; } std::string preffix_score = get_zset_score_preffix (key); auto result_elem = this ->lsm->lsm_iters_monotony_predicate ( [&preffix_score](const std::string &elem) { return -elem.compare (0 , preffix_score.size (), preffix_score); }); if (!result_elem.has_value ()) { return "*0\r\n" ; } auto [elem_begin, elem_end] = result_elem.value (); std::vector<std::pair<std::string, std::string>> elements; for (; elem_begin != elem_end; ++elem_begin) { std::string key_score = elem_begin->first; std::string elem = elem_begin->second; std::string score = get_zset_score_item (key_score); elements.emplace_back (score, elem); } if (start < 0 ) start += elements.size (); if (stop < 0 ) stop += elements.size (); if (start < 0 ) start = 0 ; if (stop >= elements.size ()) stop = elements.size () - 1 ; if (start > stop) return "*0\r\n" ; std::ostringstream oss; oss << "*" << (stop - start + 1 ) << "\r\n" ; for (int i = start; i <= stop; ++i) { oss << "$" << elements[i].second.size () << "\r\n" << elements[i].second << "\r\n" ; } return oss.str (); }
1.6 zcard zcard直接进行前缀查询就可以然后判断查询数量就可以, TTL判定的逻辑是一样的. 这里查询score和查询elem任意选择一个计数就可以了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 std::string RedisWrapper::redis_zcard (const std::string &key) { std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_zset_clean (key, rlock); if (is_expired) { return ":0\r\n" ; } std::string preffix = get_zset_score_preffix (key); auto result_elem = this ->lsm->lsm_iters_monotony_predicate ( [&preffix](const std::string &elem) { return -elem.compare (0 , preffix.size (), preffix); }); if (!result_elem.has_value ()) { return ":0\r\n" ; } auto [elem_begin, elem_end] = result_elem.value (); int count = 0 ; while (elem_begin != elem_end) { count++; ++elem_begin; } return ":" + std::to_string (count) + "\r\n" ; }
1.7 zscore/zrank 这些就最简单了, 直接拼接key, 然后执行点查询即可, 同样的也需要判定TTL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 std::string RedisWrapper::redis_zscore (const std::string &key, const std::string &elem) std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_zset_clean (key, rlock); if (is_expired) { return "$-1\r\n" ; } std::string key_elem = get_zset_key_elem (key, elem); auto query_elem = lsm->get (key_elem); if (query_elem.has_value ()) { return "$" + std::to_string (query_elem.value ().size ()) + "\r\n" + query_elem.value () + "\r\n" ; } else { return "$-1\r\n" ; } } std::string RedisWrapper::redis_zrank (const std::string &key, const std::string &elem) std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_zset_clean (key, rlock); if (is_expired) { return "$-1\r\n" ; } std::string key_elem = get_zset_key_elem (key, elem); auto query_elem = lsm->get (key_elem); if (!query_elem.has_value ()) { return "$-1\r\n" ; } std::string score = query_elem.value (); std::string key_score = get_zset_key_socre (key, score); std::string preffix_score = get_zset_key_preffix (key); auto result_elem = this ->lsm->lsm_iters_monotony_predicate ( [&preffix_score](const std::string &elem) { return -elem.compare (0 , preffix_score.size (), preffix_score); }); if (!result_elem.has_value ()) { return "$-1\r\n" ; } auto [elem_begin, elem_end] = result_elem.value (); int rank = 0 ; for (; elem_begin != elem_end; ++elem_begin) { if (elem_begin->first == key_score) { return ":" + std::to_string (rank) + "\r\n" ; } rank++; } return "$-1\r\n" ; }
2 Redis Set 实现 2.1 实现思路 Set就是在ZSet的基础上做了减法, 不需要排序性和score这个变量, 这里我们对其进行一些简化:
只存储key_elem的键值对, 其key由固定前缀+整个Set的key+当前的elem拼接而成
查询时也是范围查询
整个Set的控制结构的键值对存储elem的数量
2.2 sadd sadd比zadd简单多了, 但需要记得更新控制结构中的计数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 std::string RedisWrapper::redis_sadd (std::vector<std::string> &args) { std::string key = args[1 ]; std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_set_clean (key, rlock); if (!is_expired) { rlock.unlock (); } std::vector<std::pair<std::string, std::string>> put_kvs; std::unique_lock<std::shared_mutex> lock (redis_mtx) ; for (size_t i = 2 ; i < args.size (); ++i) { std::string member = args[i]; std::string member_key = get_set_member_key (key, member); if (!lsm->get (member_key).has_value ()) { put_kvs.emplace_back (member_key, get_set_member_value ()); } } auto key_query = lsm->get (key); int set_size = put_kvs.size (); if (key_query.has_value ()) { auto prev_size = std::stoi (key_query.value ()); set_size += prev_size; } put_kvs.emplace_back (key, std::to_string (set_size)); lsm->put_batch (put_kvs); return ":" + std::to_string (put_kvs.size () - 1 ) + "\r\n" ; }
2.3 srem/sismember srem/sismember只需要拼接key_elem然后删除/查询即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 std::string RedisWrapper::redis_srem (std::vector<std::string> &args) { std::string key = args[1 ]; std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_set_clean (key, rlock); if (is_expired) { return ":0\r\n" ; } rlock.unlock (); std::unique_lock<std::shared_mutex> lock (redis_mtx) ; std::vector<std::string> del_kvs; for (size_t i = 2 ; i < args.size (); ++i) { std::string member = args[i]; std::string member_key = get_set_member_key (key, member); if (lsm->get (member_key).has_value ()) { del_kvs.emplace_back (member_key); } } auto key_query = lsm->get (key); int set_size = -del_kvs.size (); if (key_query.has_value ()) { auto prev_size = std::stoi (key_query.value ()); set_size += prev_size; } this ->lsm->put (key, std::to_string (set_size)); this ->lsm->remove_batch (del_kvs); return ":" + std::to_string (del_kvs.size ()) + "\r\n" ; } std::string RedisWrapper::redis_sismember (const std::string &key, const std::string &member) std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_set_clean (key, rlock); if (is_expired) { return ":0\r\n" ; } std::string member_key = get_set_member_key (key, member); if (lsm->get (member_key).has_value ()) { return ":1\r\n" ; } else { return ":0\r\n" ; } }
2.4 smembers smembers就需要想之前一样进行范围查询了, 这里的谓词和之前的介绍一样, 不展开了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 std::string RedisWrapper::redis_smembers (const std::string &key) { std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_set_clean (key, rlock); if (is_expired) { return "*0\r\n" ; } std::string prefix = get_set_member_prefix (key); auto result_elem = this ->lsm->lsm_iters_monotony_predicate ( [&prefix](const std::string &elem) { return -elem.compare (0 , prefix.size (), prefix); }); if (!result_elem.has_value ()) { return "*0\r\n" ; } auto [elem_begin, elem_end] = result_elem.value (); std::vector<std::string> members; for (; elem_begin != elem_end; ++elem_begin) { std::string member_key = elem_begin->first; std::string member = member_key.substr (prefix.size ()); members.emplace_back (member); } std::ostringstream oss; oss << "*" << members.size () << "\r\n" ; for (const auto &member : members) { oss << "$" << member.size () << "\r\n" << member << "\r\n" ; } return oss.str (); }
2.5 scard scard直接查询控制结构的value:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 std::string RedisWrapper::redis_scard (const std::string &key) { std::shared_lock<std::shared_mutex> rlock (redis_mtx) ; bool is_expired = expire_set_clean (key, rlock); if (is_expired) { return ":0\r\n" ; } auto key_query = lsm->get (key); if (key_query.has_value ()) { return ":" + key_query.value () + "\r\n" ; } else { return ":0\r\n" ; } }
3 IO操作 现在我们的LSM-Tree已经可以支持Redis几乎所有的数据结构的基础命令了, 但还缺乏一些IO控制的命令, 基础的就是清空数据库和持久胡数据库. 虽然我们的LSM-Tree后台会在超出阈值后自动进行持久化, 但这里我们还是提供手动持久化的接口:
1 2 3 4 5 6 7 8 9 10 11 std::string flushall_handler (RedisWrapper &engine) { engine.clear (); return "+OK\r\n" ; } std::string save_handler (RedisWrapper &engine) { engine.flushall (); return "+OK\r\n" ; }
Redis的flush是清空数据库的意思, 但我们的Lsm Tree的flush是刷盘的意思, 含义不同
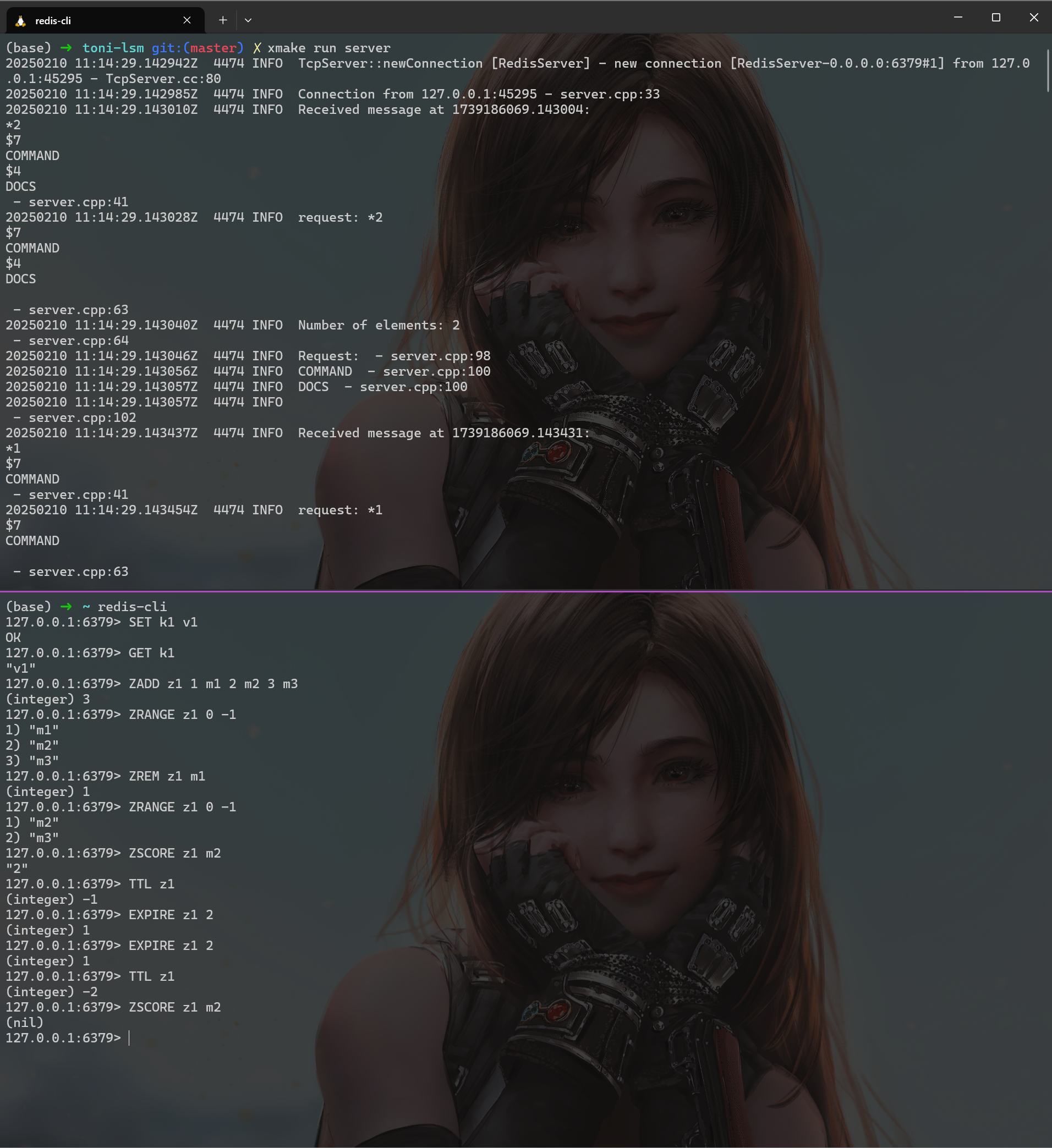
4 测试 现在我们已经初步完成了Redis的基础命令, 我们可以进行一些测试:
完美!!!
5 总结 我们已经完成了初步的Redis接口, 但其实还有很多操作类型没有实现, 比 stream, pubsub等, 这些就不展开了, 这里的核心就是介绍KV存储如何利用自身的特性完成更复杂的操作. 例如, Pingcap的Talent Plan的TinySql中, 关系型数据库底层也是用KV存储完成了, 可见KV存储的功能远比我们想象的更强大! 后续我们会实现SST的压缩.
后续课程我可能更新频率会变低, 毕竟得交论文+毕业工作了, 有兴趣的朋友也可以联系我一起完成这个教学项目!