本小节继续整合之前的所有模块, 实现迭代器。
代码仓库:https://github.com/ToniXWD/toni-lsm
欢迎点个Star
1 迭代器实现思路
实现整个LSM Tree的迭代器会复杂一点, 迭代器本质上就是数据定位信息的汇总, 回顾一下我们的LSM Tree引擎的定义头文件:
1
2
3
4
5
6
7
8
9
10
| class LSMEngine {
public:
std::string data_dir;
MemTable memtable;
std::list<size_t> l0_sst_ids;
std::unordered_map<size_t, std::shared_ptr<SST>> ssts;
std::shared_mutex ssts_mtx;
std::shared_ptr<BlockCache> block_cache;
...
}
|
因此基础的定位信息数据包括:
- 数据属于
memtable还是sst
- 如果数据属于
memtable, 其在哪个skiplist中? 在这个skiplist中的哪个位置?
- 如果数据属于
sst, 其在哪个sst中? 在这个sst中的哪个block? 在该block的索引是多少?
乍一看挺复杂的, 但由于我们之前已经实现了SstIterator和SkipListIterator, 因此我们只需要将这些迭代器组合起来即可。组合逻辑就是:
- 遍历多个
SstIterator形成一个HeapItearator为h1
- 遍历多个
SkipListIterator形成一个HeapItearator为h2
- 将
h1和h2进行合并, 得到一个新的迭代器类似, 称为MergeIterator, 记为m
这里用图示来说明一下:
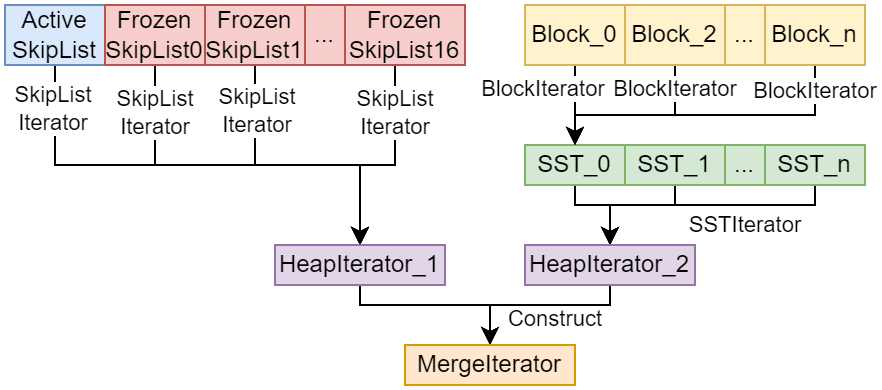
2 MergeIterator
MergeIterator需要包括2个Heaporator, 其中一个由MemTable整理而来, 另一个由SST整理而来, 因此这2个Heaporator由优先级之分, 对于相同的key, 优先选择MemTable的迭代器, 并跳过SST中相同的迭代器。由于Heaporator本质上都是小根堆, 因此相同的key肯定会同时出现的, 跳过流程也很简单。这里先给出头文件定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| #pragma once
#include "../iterator/iterator.h"
#include "../sst/sst_iterator.h"
#include <memory>
class MergeIterator {
using value_type = std::pair<std::string, std::string>;
using pointer = value_type *;
private:
HeapIterator it_a;
HeapIterator it_b;
bool choose_a = false;
mutable std::shared_ptr<value_type> current;
void update_current() const;
public:
MergeIterator();
MergeIterator(HeapIterator it_a, HeapIterator it_b);
bool choose_it_a();
void skip_it_b();
bool is_end() const;
std::pair<std::string, std::string> operator*() const;
MergeIterator &operator++();
bool operator==(const MergeIterator &other) const;
bool operator!=(const MergeIterator &other) const;
pointer operator->() const;
};
|
接下来就是自增和*运算符重载的实现:
自增
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| void MergeIterator::skip_it_b() {
if (!it_a.is_end() && !it_b.is_end() && it_a->first == it_b->first) {
++it_b;
}
}
MergeIterator &MergeIterator::operator++() {
if (choose_a) {
++it_a;
} else {
++it_b;
}
skip_it_b();
choose_a = choose_it_a();
return *this;
}
|
这里的skip_it_b就是判断如果a和b的key相同, 那么就跳过b的迭代器。a就是由memtable整理而来, b就是由sst整理而来。
*运算符重载
1
2
3
4
5
6
7
| std::pair<std::string, std::string> MergeIterator::operator*() const {
if (choose_a) {
return *it_a;
} else {
return *it_b;
}
}
|
3 迭代器的构建流程
有了MergeIterator, 我们就可以构建整个LSM的迭代器了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| MergeIterator LSMEngine::begin() {
std::vector<SearchItem> item_vec;
std::shared_lock<std::shared_mutex> lock(ssts_mtx);
for (auto &sst_id : l0_sst_ids) {
auto sst = ssts[sst_id];
for (auto iter = sst->begin(); iter != sst->end(); ++iter) {
item_vec.emplace_back(iter.key(), iter.value(), -sst_id);
}
}
HeapIterator l0_iter(item_vec);
auto mem_iter = memtable.begin();
return MergeIterator(mem_iter, l0_iter);
}
|
这里有一点需要注意, 我们的HeapIterator是个小根堆, 我们先要堆顶的元素是最近写入存储引擎的话, 就需要其排序比较运算符更小, 但实际上sst_id是越大表示越新, 因此这里有个小技巧, 就是对其取一个负值, 这样就让新的sst排在堆顶了。
end()函数构建一个2个迭代器都为空的迭代器就可以了:
1
| MergeIterator LSMEngine::end() { return MergeIterator{}; }
|