本文是本人学习CUDA整理的笔记, 该内容基本上是基于CUDA官方文档以及Youtube博主的CUDA Programming Course – High-Performance Computing with GPUs的视频教程。我这里只记录的CUDA的核心概念, 提供简单入门的途经, 详细的内容需要参考官方文档。
本文是CUDA工具链的使用方法, 建议先阅读上一篇介绍CUDA基础概念的文章再阅读本文
1 nvcc
1.1 基础编译指令
nvcc是CUDA的编译器, 其语法与gcc/g++类似, 但是增加了一些CUDA特有的指令。
基础指令:
1 | nvcc -o output_file input_file.cu |
优化级别:
和gcc/g++类似, nvcc也可以指定编译优化级别, 例如:
1 | nvcc -o output_file input_file.cu -O2 |
调试信息:
也支持生成附带调试信息的可执行文件, 例如:
1 | nvcc -G -g -o output_file input_file.cu |
这里需要对-G和-g进行解释, 在CUDA编程中,nvcc编译器的 -G 和 -g 选项都与调试相关,但它们的作用范围和行为有所不同。以下是它们的区别:
| 特性 | -G |
-g |
|---|---|---|
| 作用对象 | 设备代码(GPU代码) | 主机代码(CPU代码) |
| 调试范围 | 调试CUDA内核和设备函数 | 调试主机端的C++代码 |
| 优化行为 | 禁用设备代码的优化 | 不影响设备代码的优化 |
| 调试工具 | 适用于CUDA调试工具(如cuda-gdb、Nsight) |
适用于常规调试工具(如gdb) |
启用与禁用警告:
- 禁用所有警告信息
1
nvcc -w -o output_file input_file.cu
- 启用所有警告信息
1
nvcc -Wall -o output_file input_file.cu
1.2 CUDA特性的编译选择
1.2.1 -use_fast_math
在CUDA编程中,-use_fast_math 是 nvcc 编译器的一个优化选项,用于加速数学运算,但可能会牺牲一定的精度。具体行为包括:
- 替换数学函数:将标准数学函数(如
sin、cos、exp、log等)替换为更快的近似版本。 - 启用浮点优化:允许编译器进行更激进的浮点运算优化,例如忽略某些IEEE浮点规范(如非正规数的处理)。
- 减少精度:快速数学函数通常以牺牲精度为代价来换取性能提升。
以下面这个正弦函数计算为例:
1 |
|
按照不同的方式编译运行:
1 | $ nvcc -use_fast_math -O3 sinf.cu -o sinf-fast |
可以明显看出, 使用-use_fast_math编译的程序运行速度更快。
1.2.2 -arch && -code
-arch用于指定目标GPU的虚拟架构, 而-code用于指定目标GPU的实际架构。
实际测试发现, 通常设不设置貌似区别都不大
可以先在 https://developer.nvidia.cn/cuda-gpus#compute 中查询GPU的计算能力: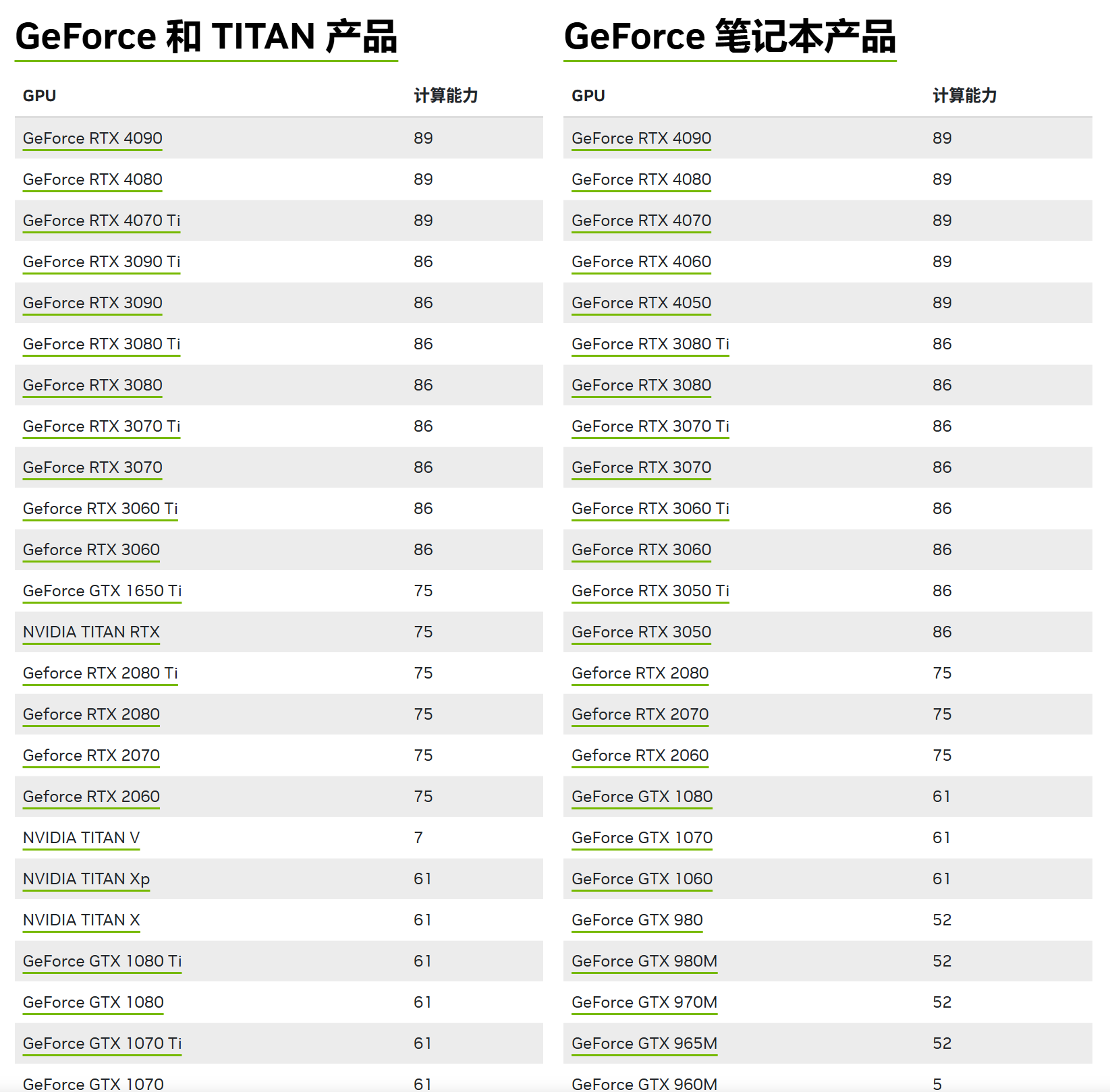
以40系显卡为例, 其计算能力为89, 则编译选项为:
1 | $ nvcc -arch=compute_89 -code=sm_89 -use_fast_math -O3 sinf.cu -o sinf-fast-89 |
1.2.3 –fmad
--fmad=true 是 nvcc 编译器的一个浮点运算优化选项,用于控制 浮点乘加运算(Fused Multiply-Add, FMA) 的行为, 能够在单条指令中完成乘法和加法的组合操作,即a * b + c。
- 在大多数情况下,
nvcc默认启用 FMA 优化(即--fmad=true)。 - 如果需要禁用 FMA 优化,可以显式设置
--fmad=false。
1.2.4 -ptx
就类似C++生成汇编代码的功能, 大概率用不到, 可以跳过
-ptx 是 nvcc用于生成 PTX(Parallel Thread Execution) 中间代码。PTX 是一种低级的、与GPU架构无关的中间代码。它类似于CPU编程中的汇编代码,但比真正的机器代码(SASS)更抽象。PTX 代码可以在运行时由GPU驱动程序动态编译为特定GPU架构的机器代码(SASS)。
生成 PTX 文件:
- 使用
-ptx选项时,nvcc会生成.ptx文件,而不是最终的二进制可执行文件。 .ptx文件包含CUDA内核的中间表示,可以用于进一步分析或跨平台编译。
- 使用
跨平台兼容性:
- PTX 代码具有较好的兼容性,可以在多种GPU架构上运行。
- 运行时,GPU驱动程序会将 PTX 代码动态编译为当前GPU架构的机器代码。
在编译CUDA代码时,可以通过以下方式生成 PTX 文件:
1 | nvcc -ptx -o my_kernel.ptx my_kernel.cu |
使用场景
跨平台编译:
- 当希望生成的代码能够在多种GPU架构上运行时,可以生成 PTX 文件。
- 运行时,GPU驱动程序会将 PTX 代码动态编译为当前GPU架构的机器代码。
调试和分析:
- PTX 代码比 SASS 代码更易读,适合用于调试和分析CUDA内核的行为。
- 可以通过检查 PTX 代码来了解编译器的优化行为。
动态代码生成:
- 在某些高级应用中,PTX 代码可以用于动态生成和加载CUDA内核。
1.2.5 -cubin && -fatbin
大概率用不到, 可以跳过
-cubin 和 -fatbin 是 nvcc 编译器的两个选项,用于生成特定格式的二进制文件。它们的作用和生成的文件类型有所不同,以下是详细说明:
-cubin 选项
- 作用:生成 CUBIN(CUDA Binary) 文件。
- CUBIN 文件:
- 包含针对特定GPU架构的 SASS(Streaming ASSembly) 机器代码。
- SASS 是GPU的本地机器代码,直接运行在特定架构的GPU上。
- CUBIN 文件是二进制格式,不可跨平台运行。
- 使用场景:
- 当你需要直接生成特定GPU架构的机器代码时使用。
- 适用于对性能要求极高的场景,或者需要直接分析机器代码的场景。
- 示例:
1
nvcc -cubin -arch=sm_75 -o my_kernel.cubin my_kernel.cu
- 这会生成计算能力 7.5(Turing)的 CUBIN 文件。
-fatbin 选项
- 作用:生成 FATBIN(Fat Binary) 文件。
- FATBIN 文件:
- 包含多种格式的代码,例如 PTX 代码和 SASS 代码。
- FATBIN 文件可以在运行时由GPU驱动程序选择最适合当前GPU的代码版本。
- 支持跨平台运行,因为包含了 PTX 中间代码。
- 使用场景:
- 当你希望生成的代码能够在多种GPU架构上运行时使用。
- 适用于需要兼容多种GPU架构的场景。
- 示例:
1
nvcc -fatbin -arch=compute_75 -code=sm_75 -o my_kernel.fatbin my_kernel.cu
- 这会生成计算能力 7.5(Turing)的 FATBIN 文件。
-cubin 和 -fatbin 的区别
| 特性 | -cubin |
-fatbin |
|---|---|---|
| 文件内容 | 仅包含 SASS 机器代码 | 包含 PTX 代码和 SASS 代码 |
| 兼容性 | 仅兼容指定的 GPU 架构 | 兼容多种 GPU 架构 |
| 文件大小 | 较小 | 较大(因为包含多种代码格式) |
| 使用场景 | 针对特定 GPU 架构优化 | 跨平台运行,兼容多种 GPU 架构 |
1.2.7 -M
-M用于生成 依赖文件。依赖文件通常用于构建系统(如 make)中,以跟踪源文件所依赖的头文件和其他文件。
-M选项会分析CUDA源文件(.cu),并生成一个依赖文件(.d),列出该源文件所依赖的所有头文件和其他文件。依赖文件通常用于构建系统(如
make),以确保在头文件或其他依赖文件发生变化时,重新编译受影响的源文件。依赖文件的格式:
- 依赖文件的格式与
make工具的规则兼容,通常是一个目标文件及其依赖文件的列表。 - 例如:
1
my_program.o: my_program.cu my_header.h
- 依赖文件的格式与
使用方式
在编译CUDA代码时,可以通过以下方式生成依赖文件:
1 | nvcc -M -o my_program.d my_program.cu |
-M:指定生成依赖文件。-o my_program.d:指定输出的依赖文件名。
依赖文件的内容
生成的依赖文件(如 my_program.d)会列出源文件所依赖的所有头文件和其他文件。例如:
1 | my_program.o: my_program.cu my_header.h /usr/local/cuda/include/cuda_runtime.h |
- 这表示
my_program.o依赖于my_program.cu、my_header.h和cuda_runtime.h。
在 make 中使用依赖文件
依赖文件通常与 make 工具一起使用。例如,假设 Makefile 内容如下:
1 | SRC = my_program.cu |
-M -MF $*.d:生成依赖文件。-include $(DEP):包含依赖文件,确保在头文件变化时重新编译。- 例如:这会将依赖文件输出到
1
nvcc -M -MF my_dependencies.d my_program.cu
my_dependencies.d。
- 例如:
**
-MT**:指定依赖文件中的目标文件名称。- 例如:这会将依赖文件中的目标文件名称设置为
1
nvcc -M -MT my_program.o my_program.cu
my_program.o。
- 例如:
示例
假设 CUDA 源文件是 my_program.cu,内容如下:
1 |
|
使用以下命令生成依赖文件:
1 | nvcc -M -o my_program.d my_program.cu |
生成的 my_program.d 文件内容可能如下:
1 | my_program.o: my_program.cu my_header.h /usr/local/cuda/include/cuda_runtime.h |
在 make 中使用依赖文件
依赖文件通常与 make 工具一起使用。例如,假设 Makefile 内容如下:
1 | SRC = my_program.cu |
-M -MF $*.d:生成依赖文件。-include $(DEP):包含依赖文件,确保在头文件变化时重新编译。
1.2.8 -dc && -dlink
-dc 和 -dlink 是 nvcc 用于处理 设备代码的分离编译和链接。它们通常用于将多个CUDA源文件分别编译为设备代码对象文件,然后再将这些对象文件链接在一起。
1. -dc 选项
- 作用:将CUDA源文件编译为 设备代码对象文件(Device Code Object File)。
- 设备代码对象文件:
- 包含设备代码(如
__global__和__device__函数)的机器代码(SASS)或PTX代码。 - 设备代码对象文件通常以
.o或.obj为扩展名。
- 包含设备代码(如
- 使用场景:
- 当项目包含多个CUDA源文件时,可以使用
-dc分别编译每个源文件,生成对应的设备代码对象文件。 - 这种方式支持分离编译(Separate Compilation),可以提高编译效率。
- 当项目包含多个CUDA源文件时,可以使用
- 示例:
1
nvcc -dc -o my_kernel.o my_kernel.cu
- 这会生成
my_kernel.o,其中包含my_kernel.cu中的设备代码。
- 这会生成
2. -dlink 选项
- 作用:将多个设备代码对象文件链接为 设备代码可执行文件(Device Code Executable)。
- 设备代码可执行文件:
- 包含所有设备代码的最终二进制表示。
- 通常与主机代码(Host Code)一起链接,生成完整的可执行文件。
- 使用场景:
- 在使用
-dc分别编译多个CUDA源文件后,使用-dlink将这些设备代码对象文件链接在一起。 - 这种方式支持分离链接(Separate Linking),适用于大型项目。
- 在使用
- 示例:
1
nvcc -dlink -o my_program_device.o my_kernel1.o my_kernel2.o
- 这会生成
my_program_device.o,其中包含my_kernel1.o和my_kernel2.o中的设备代码。
- 这会生成
-dc 和 -dlink 的工作流程
分离编译:
- 使用
-dc将每个CUDA源文件编译为设备代码对象文件。 - 例如:
1
2nvcc -dc -o my_kernel1.o my_kernel1.cu
nvcc -dc -o my_kernel2.o my_kernel2.cu
- 使用
分离链接:
- 使用
-dlink将所有设备代码对象文件链接为设备代码可执行文件。 - 例如:
1
nvcc -dlink -o my_program_device.o my_kernel1.o my_kernel2.o
- 使用
最终链接:
- 将设备代码可执行文件与主机代码链接,生成完整的可执行文件。
- 例如:
1
nvcc -o my_program my_program_device.o my_host_code.o
2 调试与性能分析
2.1 CUDA-GDB
- CUDA-GDB 是 NVIDIA 提供的基于命令行的调试工具,类似于 GNU GDB,但专门用于调试 CUDA 程序。
- 功能:
- 支持调试主机代码(CPU 代码)和设备代码(GPU 代码)。
- 可以设置断点、单步执行、查看变量、检查内存等。
- 支持多 GPU 调试。
- 使用方式:
- 编译 CUDA 程序时,需要使用
-G选项生成调试信息:1
nvcc -G -g -o my_program my_program.cu
- 使用 CUDA-GDB 启动调试:
1
cuda-gdb ./my_program
- 常用命令:
break:设置断点。run:运行程序。next:单步执行(跳过函数调用)。step:单步执行(进入函数调用)。print:打印变量值。info cuda threads:查看当前 CUDA 线程状态。info cuda kernels:查看当前运行的 CUDA 内核。
- 编译 CUDA 程序时,需要使用
2.2 Nsight Compute
Nsight Compute 是 NVIDIA 提供的一款性能分析工具,用于分析和优化 CUDA、OpenCL、Vulkan 等程序的性能。Nsight Compute提供命令行工具nsys和图形界面工具Nsight Compute。如果你是正常安装了CUDA,那么nsys和Nsight Compute是默认安装的。
2.2.1 编译时链接性能分析工具
1 | nvcc mat.cu -o mat -lnvToolsExt |
2.2.2 运行时生成报告
1 | nsys profile --stats=true ./ma |
2.2.3 图形界面查看报告
将上一步生成的report.nsys-rep文件拖入Nsight Compute中即可查看报告。