本文是本人学习CUDA整理的笔记, 该内容基本上是基于CUDA官方文档以及Youtube博主的CUDA Programming Course – High-Performance Computing with GPUs的视频教程。我这里只记录的CUDA的核心概念, 提供简单入门的途经, 详细的内容需要参考官方文档。
本文不会介绍C++基础, 适合有C++基础, 想要快速了解CUDA的读者。
1 什么是CUDA
简单说, CUDA是NVIDIA提供的一套并行计算框架, 可以利用GPU进行并行计算。本文由于篇幅有限不做过多介绍, 可以参考本人的另一篇笔记: Stanford-CS149-并行计算-Lec07-笔记-GPU && CUDA
同时CUDA的安装可以参考: WSL入门到入土
2 CUDA基础概念
2.1 Host 和 Device
CUDA程序中, 存在Host和Device两个概念, 前者是CPU, 后者是GPU。熟悉Pytorch的读者应该知道, Pytorch的CPU和GPU的计算是分开的, CPU上的数据需要通过.cuda()函数传递到GPU上。本质上就是GPU的计算使用的显存, 而CPU的计算使用的是内存。
2.2 Kernel
Kernel是CUDA中最重要的概念, 此Kernel不是操作系统的内核, 而是指的是在GPU上执行的函数。Kernel的执行是并行的, 可以同时执行多个线程(也不是操作系统的线程, 后面会介绍)。Kernel的执行需要通过<<<,>>>操作符来指定执行的线程数和线程块数。
2.3 Grid, Block, Thread
Thread(线程):
- 最基本的执行单元,每个线程独立运行相同的代码,但处理不同的数据。
- 线程通过唯一的
threadIdx标识。
Block(线程块):
- 一组线程的集合,块内的线程可以通过共享内存和同步操作(如
__syncthreads())协作。 - 块通过唯一的
blockIdx标识,块内的线程通过threadIdx标识。
- 一组线程的集合,块内的线程可以通过共享内存和同步操作(如
Grid(网格):
- 由多个线程块组成,网格中的所有线程块执行相同的内核函数。
- 网格通过唯一的
gridDim和blockIdx标识。gridDim表示网格中包含的线程块block数,blockIdx表示线程块的索引。
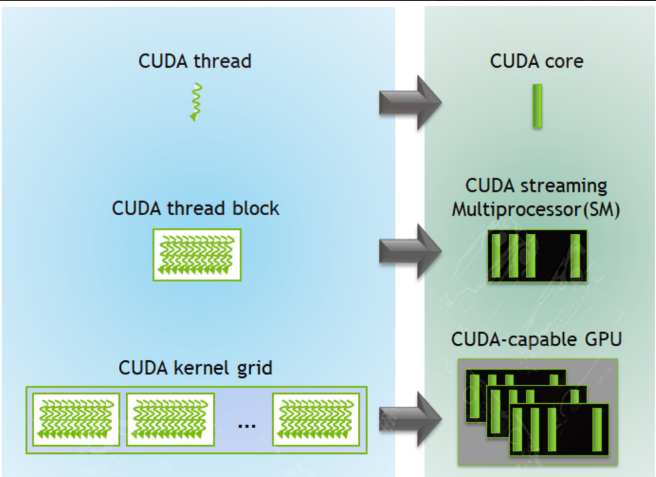
Grid是CUDA中执行的线程块的集合, Block是CUDA中执行的线程的集合, 线程Thread是CUDA中执行的最小单位。Grid由多个Block组成, Block由多个Thread组成。
需要注意的是,Thread是CUDA中执行的最小执行上下文单位,类似CPU中的SIMD中的一个计算通道。并且Thread是实际存在的硬件, 而Block和Grid是逻辑概念, 是CUDA为了方便管理线程而引入的抽象。
他们的区别和联系如下总结:
| 概念 | 描述 | 标识符 | 协作与通信 |
|---|---|---|---|
| Thread | 最基本的执行单元,独立运行代码。 | threadIdx |
无直接协作,通过全局内存通信。 |
| Block | 一组线程的集合,块内线程可通过共享内存和同步操作协作。 | blockIdx, threadIdx |
块内线程可协作,块间独立。 |
| Grid | 由多个线程块组成,所有块执行相同的内核函数。 | gridDim, blockIdx |
块间无直接协作,通过全局内存通信。 |
2.4 Warps
CUDA中, 一个warp是CUDA中执行的最小的执行调度单位, 一个warp包含32个Thread。CUDA中, 一个warp的执行是并行的, 可以同时执行32个Thread, 称为SIMD(单指令多数据: Single Instruction Multiple Thread)。
这里不对warp做过多介绍, 只需要知道warp是CUDA中执行的最小执行上下文单位, 一个warp包含32个Thread。
可能会有人产生疑惑, 不是说
Thread是CUDA中执行的最小执行上下文单位, 怎么现在又变成warp了? 这其实和CPU的SIMD很类似,GPU的warp的32个Thread就相当于CPU的SIMD的avx256的8个计算通道(假设是32位浮点数运算)。
需要注意的是, warp有对应的硬件, warp有为32个Thread对应的上下文寄存器。因此,通常进行简单的CUDA编程时, 不需要考虑这个概念, 只需要操作Grid, Block, Thread即可。
3 CUDA基础编程
3.1 基础语法汇总
有了上面的基础概念, 可以上手简单的CUDA程序了。CUDA编程可以看做C++的超集, 其在C++的基础上, 添加一些CUDA特有的语法。
这里假定读者有C/C++的基础, 直接给出总结后的语法, 这里有一些没有涉及的概念, 比如Stream, Event, Atomic Operation等, 这些概念后续章节会介绍。
| 类别 | 语法/概念 | 描述 | 示例 |
|---|---|---|---|
| 内核函数 | __global__ void kernel(...) |
定义在 GPU 上执行的函数。__global__ 表示该函数是内核函数,由 CPU 调用,GPU 执行。 |
__global__ void add(int *a, int *b, int *c) { *c = *a + *b; } |
| 主机函数 | __host__ void host_func(...) |
定义在 CPU 上执行的函数。__host__ 是默认修饰符,可省略。 |
__host__ void init(int *a, int value) { *a = value; } |
| 设备函数 | __device__ void device_func(...) |
定义在 GPU 上执行的辅助函数,只能由内核函数或其他设备函数调用。 | __device__ int square(int x) { return x * x; } |
| 调用内核 | kernel<<<grid, block>>>(...) |
从 CPU 调用内核函数。grid 和 block 分别指定网格和线程块的维度。 |
add<<<1, 1>>>(d_a, d_b, d_c); |
| 线程索引 | threadIdx.x, threadIdx.y, threadIdx.z |
当前线程在线程块中的索引。 | int idx = threadIdx.x; |
| 块索引 | blockIdx.x, blockIdx.y, blockIdx.z |
当前线程块在网格中的索引。 | int blockId = blockIdx.x; |
| 块维度 | blockDim.x, blockDim.y, blockDim.z |
线程块的维度(每个线程块中的线程数)。 | int threadsPerBlock = blockDim.x; |
| 网格维度 | gridDim.x, gridDim.y, gridDim.z |
网格的维度(每个网格中的线程块数)。 | int blocksPerGrid = gridDim.x; |
| 全局线程索引 | int idx = blockIdx.x * blockDim.x + threadIdx.x; |
计算当前线程的全局索引,用于处理一维数据。 | int idx = blockIdx.x * blockDim.x + threadIdx.x; |
| 共享内存 | __shared__ float shared_mem[100]; |
定义线程块内共享的内存,块内所有线程可见,生命周期与块相同。 | __shared__ float temp[128]; |
| 同步线程 | __syncthreads(); |
同步线程块内的所有线程,确保所有线程都执行到此处后再继续。 | __syncthreads(); |
| 内存分配 | cudaMalloc(void **devPtr, size_t size); |
在 GPU 上分配全局内存。 | cudaMalloc((void**)&d_a, sizeof(int)); |
| 内存释放 | cudaFree(void *devPtr); |
释放 GPU 上的全局内存。 | cudaFree(d_a); |
| 内存拷贝 | cudaMemcpy(void *dst, const void *src, size_t count, cudaMemcpyKind kind); |
在主机和设备之间拷贝数据。kind 可以是 cudaMemcpyHostToDevice 或 cudaMemcpyDeviceToHost。 |
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice); |
| 错误检查 | cudaGetLastError(), cudaDeviceSynchronize() |
检查 CUDA 函数是否出错,并同步设备以确保所有任务完成。 | cudaDeviceSynchronize(); if (cudaGetLastError() != cudaSuccess) { printf("Error!\n"); } |
| 设备管理 | cudaSetDevice(int device); |
设置当前使用的 GPU 设备。 | cudaSetDevice(0); |
| 流 | cudaStream_t stream; |
定义 CUDA 流,用于并发执行多个任务。 | cudaStream_t stream; cudaStreamCreate(&stream); kernel<<<1, 1, 0, stream>>>(...); |
| 事件 | cudaEvent_t start, stop; |
定义 CUDA 事件,用于测量时间或同步任务。 | cudaEventCreate(&start); cudaEventRecord(start); cudaEventElapsedTime(&time, start, stop); |
| 原子操作 | atomicAdd(int *address, int val); |
原子操作,确保多个线程对同一内存地址的操作是原子的。 | atomicAdd(&sum, value); |
3.2 Kernel的维度
在 CUDA 编程中,Kernel 的维度是指如何组织线程(Thread)和线程块(Block)的层次结构,以便在 GPU 上执行并行任务。CUDA 使用 Grid 和 Block 的层次结构来定义线程的分布,而每个 Block 和 Grid 可以是 一维、二维或三维 的。这种灵活性使得 CUDA 能够高效地处理各种并行计算任务。
Grid 和 Block 的层次结构
- Grid:一个 Grid 包含多个线程块(Block)。
- Block:一个 Block 包含多个线程(Thread)。
- Thread:最基本的执行单元。
Kernel 的维度通过定义 Grid 和 Block 的大小和形状来确定。CUDA 支持以下维度的 Grid 和 Block:
- 一维(1D)
- 二维(2D)
- 三维(3D)
定义 Grid 和 Block 的维度
在调用 Kernel 时,需要通过 <<<>>> 语法指定 Grid 和 Block 的维度。CUDA 提供了以下数据类型来定义维度:
- **
dim3**:用于定义 Grid 和 Block 的维度,支持 1D、2D 和 3D。- 如果只指定一个值,则默认为 1D。
- 如果指定两个值,则为 2D。
- 如果指定三个值,则为 3D。
示例
1 | // 1D Grid 和 1D Block |
线程索引的计算
在 Kernel 中,可以通过以下内置变量获取当前线程的索引:
- **
threadIdx**:当前线程在 Block 中的索引(threadIdx.x,threadIdx.y,threadIdx.z)。 - **
blockIdx**:当前 Block 在 Grid 中的索引(blockIdx.x,blockIdx.y,blockIdx.z)。 - **
blockDim**:Block 的维度(blockDim.x,blockDim.y,blockDim.z)。 - **
gridDim**:Grid 的维度(gridDim.x,gridDim.y,gridDim.z)。
全局线程索引的计算
- 1D Grid 和 1D Block:
1
int idx = blockIdx.x * blockDim.x + threadIdx.x;
- 2D Grid 和 2D Block:
1
2
3int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int idx = y * gridDim.x * blockDim.x + x; - 3D Grid 和 3D Block:
1
2
3
4int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int z = blockIdx.z * blockDim.z + threadIdx.z;
int idx = z * (gridDim.y * blockDim.y) * (gridDim.x * blockDim.x) + y * (gridDim.x * blockDim.x) + x;
3.3 内存管理
3.3.1. CUDA 内存模型
CUDA 内存模型包括以下几种主要内存类型:
| 内存类型 | 描述 | 作用域 | 生命周期 |
|---|---|---|---|
| 全局内存 (Global Memory) | GPU 的主要内存,所有线程都可以访问,速度较慢。 | 所有线程和主机 | 由程序员显式管理 |
| 共享内存 (Shared Memory) | 线程块内的共享内存,块内线程可访问,速度较快。 | 线程块内 | 线程块执行期间 |
| 寄存器 (Registers) | 每个线程的私有内存,速度最快,容量有限。 | 单个线程 | 线程执行期间 |
| 常量内存 (Constant Memory) | 只读内存,适合存储常量数据,访问速度快。 | 所有线程和主机 | 由程序员显式管理 |
| 纹理内存 (Texture Memory) | 专为图像处理优化的只读内存,支持缓存和插值。 | 所有线程 | 由程序员显式管理 |
| 本地内存 (Local Memory) | 当寄存器不足时,线程的私有数据会存储在本地内存中,速度较慢。 | 单个线程 | 线程执行期间 |
3.3.2. 内存管理函数
CUDA 提供了一系列函数来管理设备内存和主机-设备之间的数据传输, 这些函数在cuda_runtime.h头文件中定义, 且非常类似C语言的malloc和free和string.h中的函数。
3.3.2.1 设备内存分配与释放
| 函数 | 描述 | 示例 |
|---|---|---|
cudaMalloc(void **devPtr, size_t size) |
在设备上分配全局内存。 | cudaMalloc((void**)&d_a, sizeof(float) * N); |
cudaFree(void *devPtr) |
释放设备上的全局内存。 | cudaFree(d_a); |
3.3.2.2 主机-设备数据传输
| 函数 | 描述 | 示例 |
|---|---|---|
cudaMemcpy(void *dst, const void *src, size_t count, cudaMemcpyKind kind) |
在主机和设备之间拷贝数据。kind 指定传输方向。 |
cudaMemcpy(d_a, h_a, sizeof(float) * N, cudaMemcpyHostToDevice); |
cudaMemcpyHostToDevice |
从主机内存拷贝数据到设备内存。 | |
cudaMemcpyDeviceToHost |
从设备内存拷贝数据到主机内存。 | |
cudaMemcpyDeviceToDevice |
在设备内存之间拷贝数据。 |
3.3.2.3 内存初始化
| 函数 | 描述 | 示例 |
|---|---|---|
cudaMemset(void *devPtr, int value, size_t count) |
将设备内存初始化为指定值。 | cudaMemset(d_a, 0, sizeof(float) * N); |
3.5 代码示例
下面是一个经典的矩阵计算的CUDA实现:
1 |
|
这里简单展示一下举证计算的网格维度划分, 这2行代码实现维度划分:
1 | dim3 blockDim(2, 2); // 每个 Block 有 2x2 个线程 |
矩阵计算的维度以矩阵C的维度进行, C的维度本来是(M, K) = (4, 2), 而每个网格划分后的分布如下: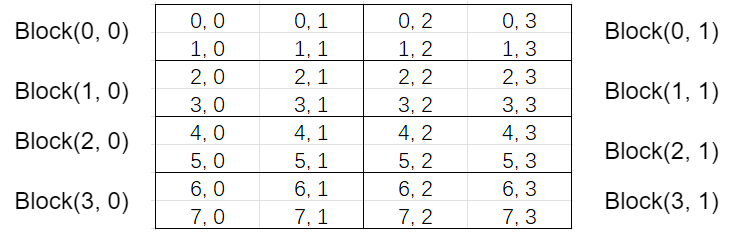
例如Block(0,1)中的0就表示blockIdx.y, 1就表示blockIdx.x, Block(0,1)中的坐标(1,2)对应的threadIdx.x=0, threadIdx.y=1
因此, kernel中的这两行:
1 | auto row = blockIdx.y * blockDim.y + threadIdx.y; |
就是计算原始的行列(逻辑上的行和列, 因为数据本质是一维数组)
4 线程安全与同步
4.1 线程同步与屏障
类似C++, CUDA中也有线程同步的概念, 这里的同步也类似Go的WaitGroup。
| 函数 | 作用域 | 描述 | 使用场景 |
|---|---|---|---|
cudaDeviceSynchronize() |
设备级别 | 阻塞主机线程,直到设备上所有任务完成。 | 用于确保主机代码在设备任务完成后继续执行。 |
__syncthreads() |
线程块级别 | 同步线程块内的所有线程,确保所有线程都执行到此处后再继续。 | 用于线程块内的线程协作,例如共享内存操作后同步。 |
__syncwarp() |
Warp 级别 | 同步 Warp 内的所有线程(32 个线程),确保 Warp 内的线程执行到此处后再继续。 | 用于 Warp 内的线程协作,例如 Warp 级别的操作后同步。 |
__threadfence() |
线程块级别 | 确保之前的所有内存操作可见 | 避免由于内存访问乱序导致的竞态条件或数据不一致问题。 |
__threadfence_block() |
线程块级别 | 与 __threadfence() 相同,但更明确地表示作用范围是线程块内。 | 用于线程块内的线程协作,例如共享内存操作后同步。 |
__threadfence_system() |
设备级别 | 确保内存操作对整个系统(包括 GPU 和 CPU)可见。 | 用于整个设备内的线程协作,例如共享内存操作后同步。 |
warp相关的同步函数较少涉及, 这里就不介绍了
sync类函数和fence类函数的区别是什么?
sync类函数:用于线程同步,确保所有线程到达同步点后再继续执行,适用于线程块内的协作操作。fence类函数:用于内存栅栏,确保内存操作的顺序性和可见性,适用于线程间通信和多 GPU 协同计算。
4.2 原子操作
熟悉C++的朋友们肯定知道原子操作是什么, 这里我就只给出整理好的语法说明:
整数原子操作
以下原子操作适用于 int 类型的数据。
| 函数 | 描述 | 返回值 | 示例 |
|---|---|---|---|
atomicAdd(int* address, int val) |
原子地将 val 加到 address 指向的值,并返回旧值。 |
旧值 | int old = atomicAdd(&sum, 1); |
atomicSub(int* address, int val) |
原子地从 address 指向的值中减去 val,并返回旧值。 |
旧值 | int old = atomicSub(&sum, 1); |
atomicExch(int* address, int val) |
原子地将 address 指向的值替换为 val,并返回旧值。 |
旧值 | int old = atomicExch(&var, 10); |
atomicMax(int* address, int val) |
原子地将 address 指向的值设置为 max(old_value, val),并返回旧值。 |
旧值 | int old = atomicMax(&max_val, new_val); |
atomicMin(int* address, int val) |
原子地将 address 指向的值设置为 min(old_value, val),并返回旧值。 |
旧值 | int old = atomicMin(&min_val, new_val); |
atomicAnd(int* address, int val) |
原子地对 address 指向的值和 val 进行按位与操作,并返回旧值。 |
旧值 | int old = atomicAnd(&var, mask); |
atomicOr(int* address, int val) |
原子地对 address 指向的值和 val 进行按位或操作,并返回旧值。 |
旧值 | int old = atomicOr(&var, mask); |
atomicXor(int* address, int val) |
原子地对 address 指向的值和 val 进行按位异或操作,并返回旧值。 |
旧值 | int old = atomicXor(&var, mask); |
atomicCAS(int* address, int compare, int val) |
原子地比较 address 指向的值与 compare,如果相等,则替换为 val,并返回旧值。 |
旧值 | int old = atomicCAS(&var, expected, new_val); |
浮点数原子操作
以下原子操作适用于 float 和 double 类型的数据。
| 函数 | 描述 | 返回值 | 示例 |
|---|---|---|---|
atomicAdd(float* address, float val) |
原子地将 val 加到 address 指向的值,并返回旧值。支持从 CUDA 2.0 开始。 |
旧值 | float old = atomicAdd(&sum, 1.0f); |
atomicAdd(double* address, double val) |
原子地将 val 加到 address 指向的值,并返回旧值。支持从 CUDA Compute Capability 6.0 开始。 |
旧值 | double old = atomicAdd(&sum, 1.0); |
4.3 代码示例
以下是一个简单的 CUDA 程序,演示了 线程同步 的使用场景。该程序使用共享内存(Shared Memory)和 __syncthreads() 来实现线程块内的协作计算。
程序功能
- 每个线程块计算其内部线程的局部和,并将结果存储到共享内存中。
- 使用
__syncthreads()确保所有线程完成共享内存的写入后,再进行后续计算。 - 最后,将每个线程块的计算结果累加到全局内存中。
代码实现
1 |
|
这里的__syncthreads有2次使用:
- 第一次使用是完成共享内存的初始化
- 第二次使用是等待当前
block的所有线程完成, 然后继续执行下一个循环, 因为下一个循环的shared_data依赖于不同索引处的值
5 Stream
5.1 Stream 的基本概念
在 CUDA 中,Stream 是一种用于管理并发执行的机制。通过使用 Stream,可以将多个任务(如 Kernel 执行、内存拷贝等)分配到不同的流中,从而实现任务之间的并行执行。Stream 的主要作用是提高 GPU 的利用率,特别是在需要执行多个独立任务时。
- Stream:一个
Stream是一个任务队列,其中的任务按顺序执行。不同Stream中的任务可以并发执行。 - 默认 Stream:如果没有显式创建
Stream,所有任务都会在默认Stream中执行,任务之间是串行的。 - 非默认 Stream:通过显式创建
Stream,可以将任务分配到不同的Stream中,从而实现并发执行。
Stream 的使用场景
- 并发 Kernel 执行:在多个
Stream中启动不同的Kernel,实现Kernel的并发执行。 - 并发内存拷贝和 Kernel 执行:在一个
Stream中执行Kernel,同时在另一个Stream中执行内存拷贝,实现计算和数据传输的重叠。 - 多任务流水线:将多个任务分配到不同的
Stream中,形成流水线,提高整体吞吐量。
5.2. Stream 的基本操作
创建和销毁 Stream
- 创建 Stream:
1
2cudaStream_t stream;
cudaStreamCreate(&stream); - 创建 Stream 并设置优先级:这里的
1
2
3
4int leastPriority, greatestPriority;
cudaDeviceGetStreamPriorityRange(&leastPriority, &greatestPriority);
cudaStreamCreateWithPriority(&stream1, cudaStreamNonBlocking, leastPriority);
cudaStreamCreateWithPriority(&stream2, cudaStreamNonBlocking, greatestPriority);flag设置为cudaStreamNonBlocking表示非阻塞, 否则设置为0即可 - 销毁 Stream:
1
cudaStreamDestroy(stream);
在 Stream 中执行任务
启动 Kernel:
1
kernel<<<gridDim, blockDim, 0, stream>>>(...);
其中
stream是指定的 Stream。异步内存拷贝:
1
cudaMemcpyAsync(dst, src, size, cudaMemcpyHostToDevice, stream);
其中
stream是指定的 Stream。在CUDA编程中,将 使用Stream的Kernel和cudaMemcpyAsync结合使用的主要目的是实现计算与数据传输的重叠,从而最大化 GPU 的利用率和整体性能。这种结合使用的场景在需要频繁进行数据传输和计算的应用程序中非常常见,例如深度学习训练、科学计算和大规模数据处理等。
同步 Stream
同步单个 Stream:
1
cudaStreamSynchronize(stream);
等待指定 Stream 中的所有任务完成。
同步所有 Stream:
1
cudaDeviceSynchronize();
等待所有 Stream 中的任务完成。
5.3 Events
Events 是 CUDA 中用于同步和计时的高级机制。通过创建和使用 Events,可以精确地跟踪和控制任务的执行时间,从而优化性能和调试。Events 通常与 Stream 结合使用,用于同步和计时,并创建依赖关系。
以下面的代码为例(摘选自cuda-course):
1 | cudaEvent_t start, stop; |
上面的代码展示了如何使用 Events 来同步和计时。
- 同步:使用
cudaEventRecord标记了start和stop事件, 然后使用cudaEventSynchronize等待stop事件完成 - 计时:使用
cudaEventElapsedTime计算start和stop事件之间的时间差, 单位为毫秒
5.4 CallBack
Callback 是 CUDA 中用于在任务完成时执行回调函数的高级机制。通过创建和使用 Callback,可以实现任务完成后的自定义操作,例如日志记录、错误处理等。Callback 通常与 Stream 结合使用,用于在任务完成后执行特定的操作。其使用方式如下:
1 | cudaStreamAddCallback(stream, callback, data, flags); |
这里的callback是一个函数指针, data是传递给回调函数的参数, flags是回调函数的标志, 通常设置为0。
5.5 代码示例
下面的代码同样摘选自cuda-course
1 |
|
- 这段代码首先使用
cudaStreamCreateWithPriority创建的优先级不同的Stream,stream2的优先级最高,stream1的优先级最低 - 然后使用
cudaEventCreate创建了一个Event, 并使用cudaEventRecord在stream1中记录了这个事件, 需要注意的是, 由于stream1先启动了kernel1, 当记录这个Event时的含义是kernel1已经完成 - 接着使用
cudaStreamWaitEvent在stream2中等待这个事件完成, 也就是kernel1完成后stream1通过记录Event来通知stream2 - 最后使用
cudaStreamAddCallback在stream2中添加了一个回调函数, 当stream2中的任务完成时, 会调用这个回调函数 - 这段代码的目的是实现
stream1和stream2的并发执行, 并使用Event来同步stream2和stream1