这一章节的课程内容是关于DNN的评估和优化。虽然课程有2h, 但前面不少是对神经网络的简单介绍, 相信大家或多或少都了解过, 我就直接略过, 直接记录对卷积运算的优化部分。
课程主页: https://gfxcourses.stanford.edu/cs149/fall24
1 朴素的卷积运算
1 | float input[IMAGE_BATCH_SIZE][INPUT_HEIGHT][INPUT_WIDTH][INPUT_DEPTH]; // input activations |
如果不使用任何并行计算的知识, 我们的写出的代码应该和上面差不多。但上面的代码存在很多问题, 比如:
- 内存访问不连续, 如果矩阵尺寸大, 卷积核移动的过程一定伴随缓存未命中
- 内存访问方式复杂, 访问矩阵的元素是按照卷积核的尺寸和位置进行的
- 循环层数太多, 不利于并行化
2 GEMM优化
为了提高效率,许多深度学习框架将卷积操作转换为矩阵乘法(GEMM)。这种转换通常涉及到对输入数据的重新排列(im2col或im2row),使得原本需要通过多层循环完成的操作可以通过一次或几次高效的矩阵乘法来完成。
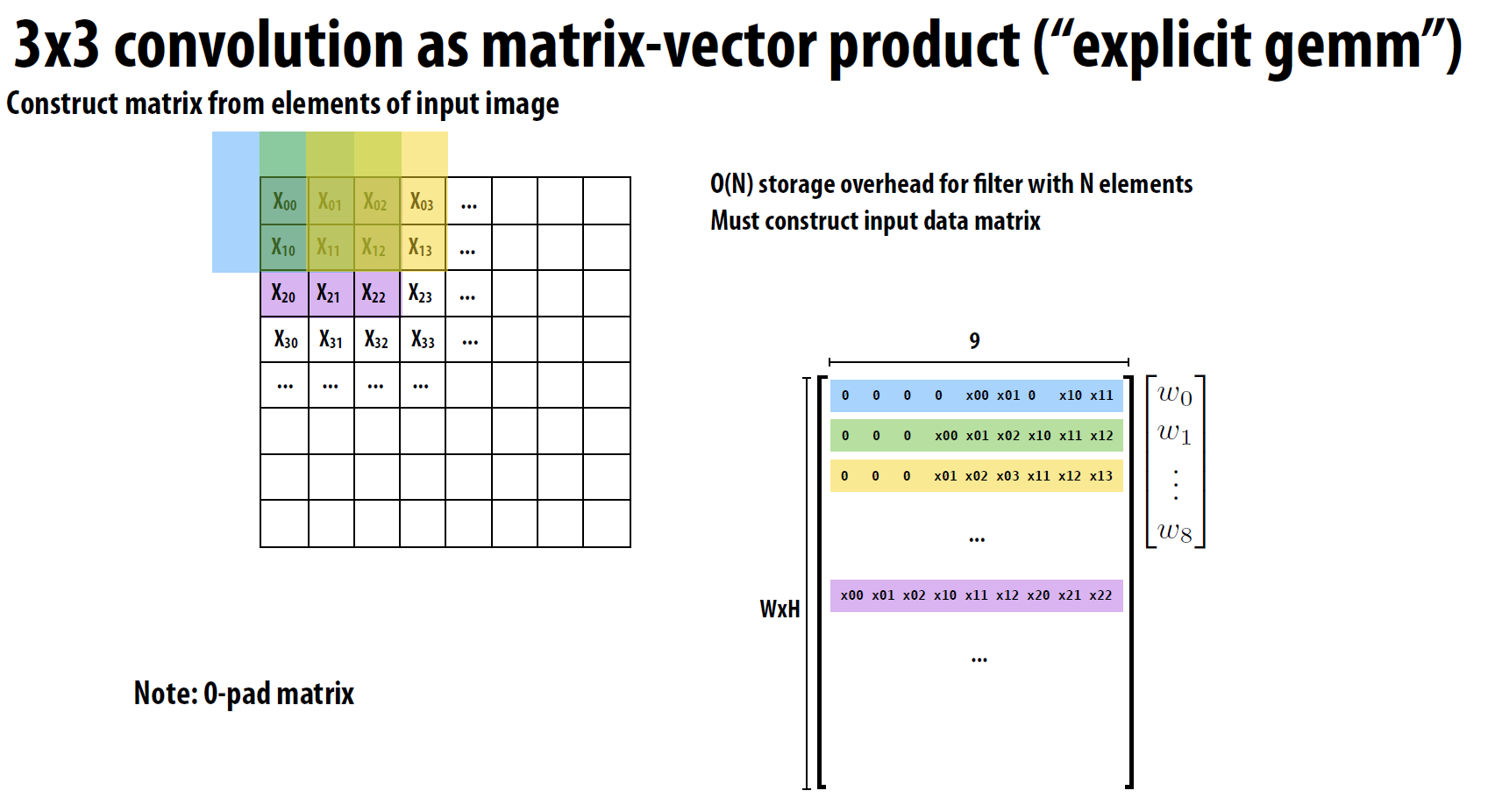
以上图单层卷积为例, GEMM的优化就是将卷积核对应的矩阵输入拉平成矩阵的一行, 边缘部分用0填充。
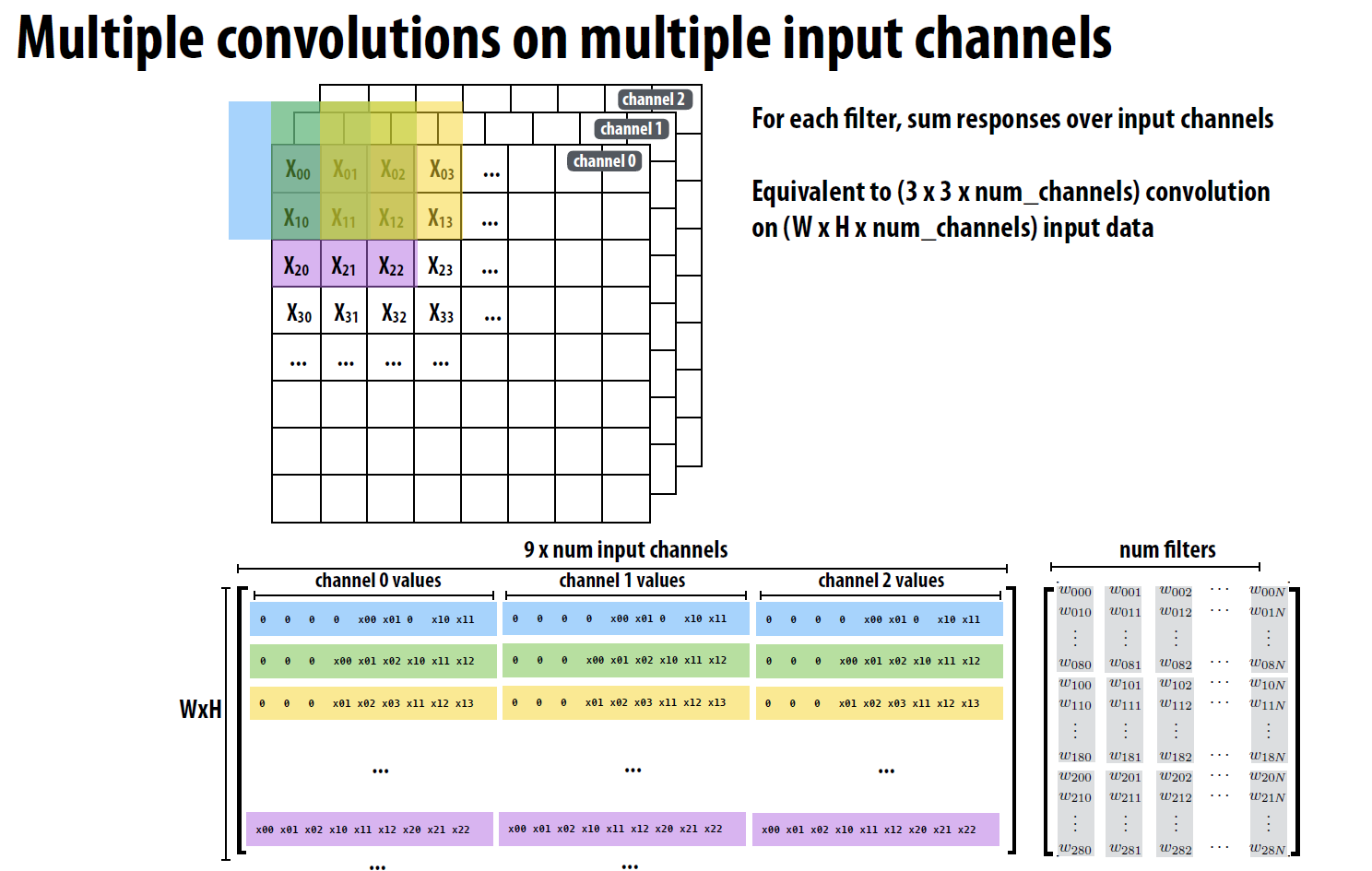
上图展示的是多通道卷积的情况, 可以看到, 这里复习以下多通道卷积的运算逻辑:
卷积核:假设我们有一个卷积核
K, 其尺寸为k x k x C, 其中C代表通道数。这个卷积核实际上是由C个k x k的二维矩阵组成的,每个矩阵对应于输入图像的一个通道。卷积计算:当这个卷积核应用于输入图像时,它会在每一个位置上分别与输入图像的各个通道进行逐元素乘法,然后将所有通道的结果相加,再加上偏置(如果有的话),最终得到一个单一的标量值。这相当于在每个位置上做了一次三维点积。
输出特征图:如果我们使用了多个卷积核(比如
N个),那么每个卷积核都会产生一个这样的标量值,从而形成一个H_out x W_out的二维矩阵,即一个特征图。因此,如果有N个卷积核,我们将得到N个这样的特征图,它们一起构成一个H_out x W_out x N的三维张量,这就是卷积层的输出。输出通道数:输出的通道数等于使用的卷积核的数量
N,而不是1。每个卷积核都贡献了一个通道给输出。所以,如果你有64个卷积核,你的输出就会有64个通道。
可以看出, 多通道卷积的访问模式更复杂,计算的元素在内存中实际的分布更远, 因此, 多通道卷积的GEMM优化需要将输入的矩阵拉平成矩阵的一行, 边缘部分用0填充, 这样可以简化数据访问,同时便于并行优化,例如SIMD优化。
3 矩阵乘法分块优化
3.1 基础矩阵分块优化
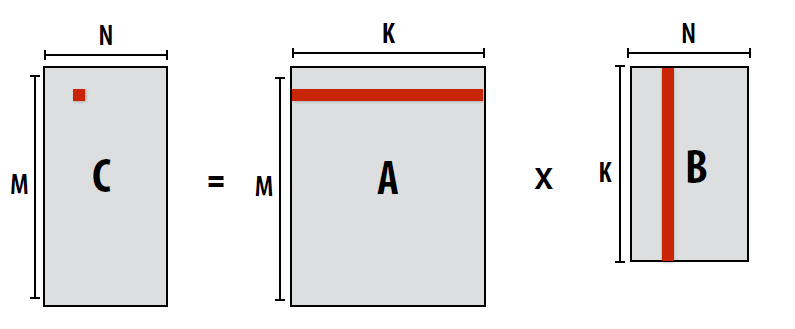
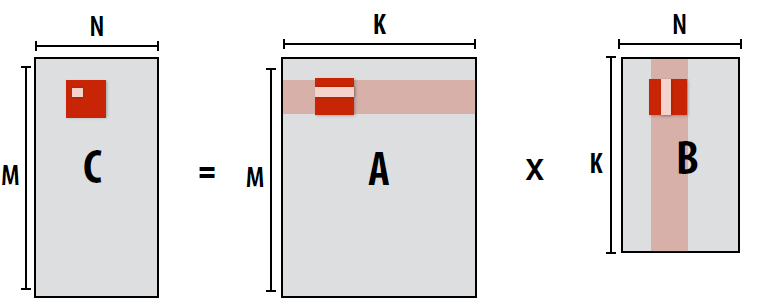
即使我们使用GEMM优化, 对于大尺度的矩阵来说,还有一个问题没有解决, 先看一个常规的矩阵乘法实现:
1 | float A[M][K]; |
这段代码的缺点显而易见:
- 缺乏局部性的利用, 运算一个C中的元素需要访问整行A和整列B
- 计算C中下一个元素时, 上一个元素的缓存数据基本上都失效了
为了解决这个问题, 我们可以将矩阵分块, 将矩阵分成多个小块, 每个小块的运算可以并行化, 这样可以提高计算效率。
1 | float A[M][K]; |
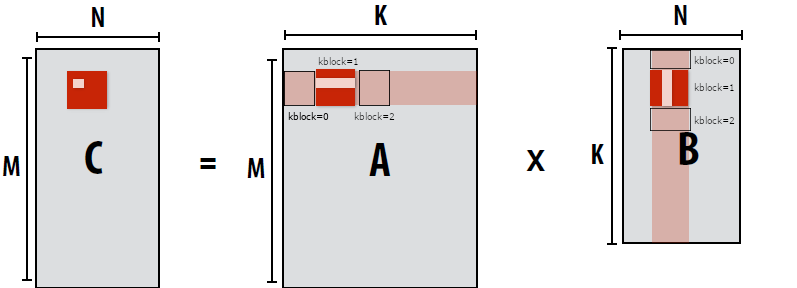
此时我们以块为单位进行计算, jblock和iblock是块的索引, j和i是块内的索引, kblock是计算C中的块所需要A和B矩阵中快内的索引。
这里尤其需要注意一下 kblock, 我在图中对kblock的索引进行了标注, 可以看到, 在计算C中的块时, 需要访问A和B矩阵中对应的块, 因此, kblock的索引需要从0开始, 到K结束。
3.2 矩阵分块的SIMD优化
有了之前矩阵分块的优化, 我们就可以将矩阵分块, 每个小块的运算可以并行化, 这样可以提高计算效率, 一个典型的SIMD优化的思路是:

这里的思路就是, A中的某一行的一个元素, 会与B中的某一行的多个元素相乘, 结果会累加到C中的对应行的不同列中, 这样就可以利用SIMD指令进行优化, 一次性将B中的行数据加载到寄存器中, 然后与A中的的这个元素乘法运算, 最后将结果累加到C中的对应行中。
3.3 局部性优化
由于B中的元素是按照列进行访问的, 但内存中是以行作为连续的空间存储的, 因此可以将B进行转置, 这样B中的元素就是按照行进行访问的, 这样就可以利用内存的连续性进行优化。
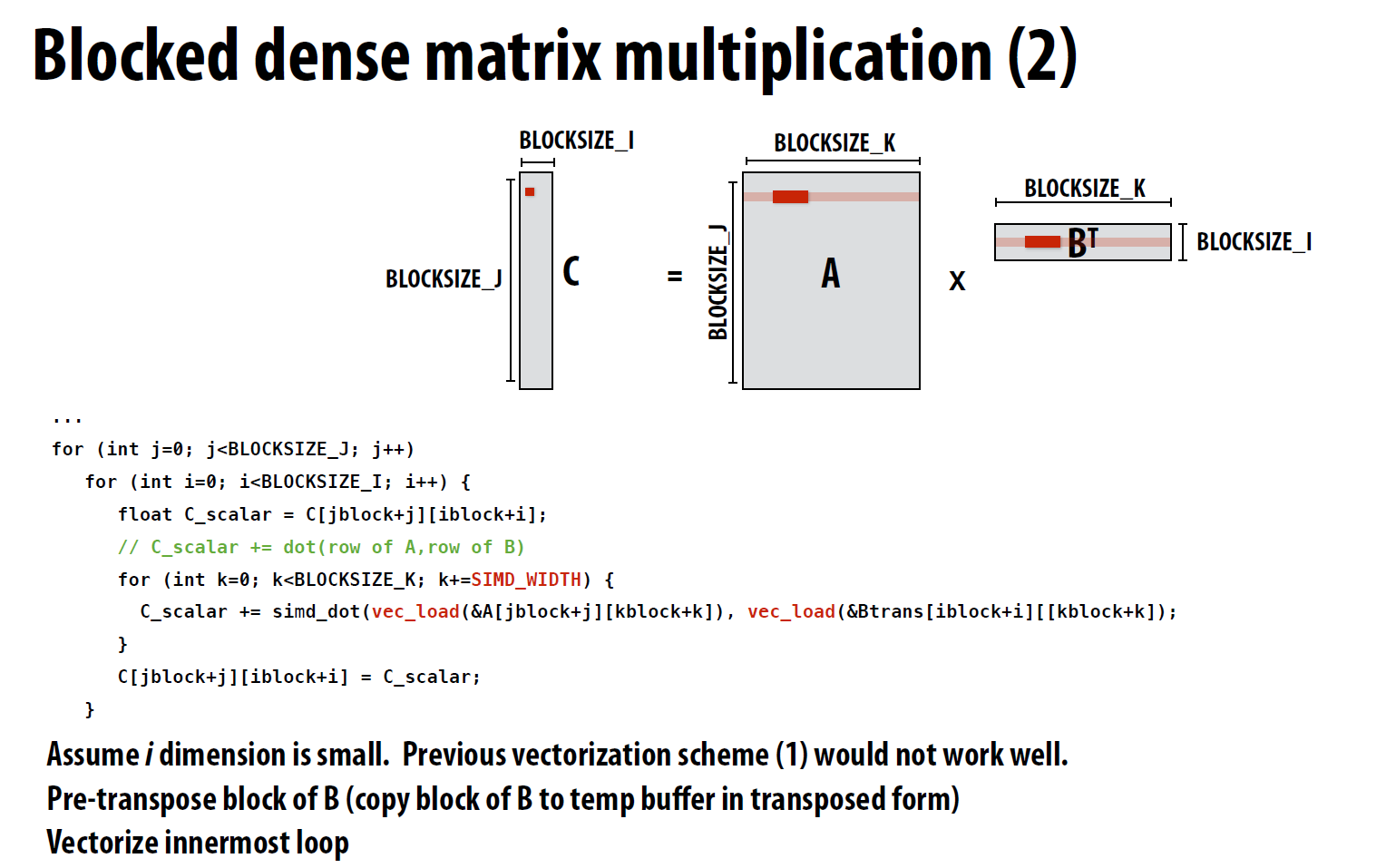
转置后仍然可以使用SIMD优化:

5 内存带宽优化
5.1 逻辑上的GEMM
GEMM是将卷积核中的元素拉平成矩阵的一行, 边缘部分用0填充, 然后与输入矩阵进行矩阵乘法运算, 但是如果矩阵特别大, 且运算的次数特别多, 构造一个这样的全新矩阵陷入很满意必要, 因此可以直接在逻辑上构造一个用于计算的矩阵, 但访问矩阵元素时, 按照卷积核的尺寸和位置到原始矩阵中进行访问。

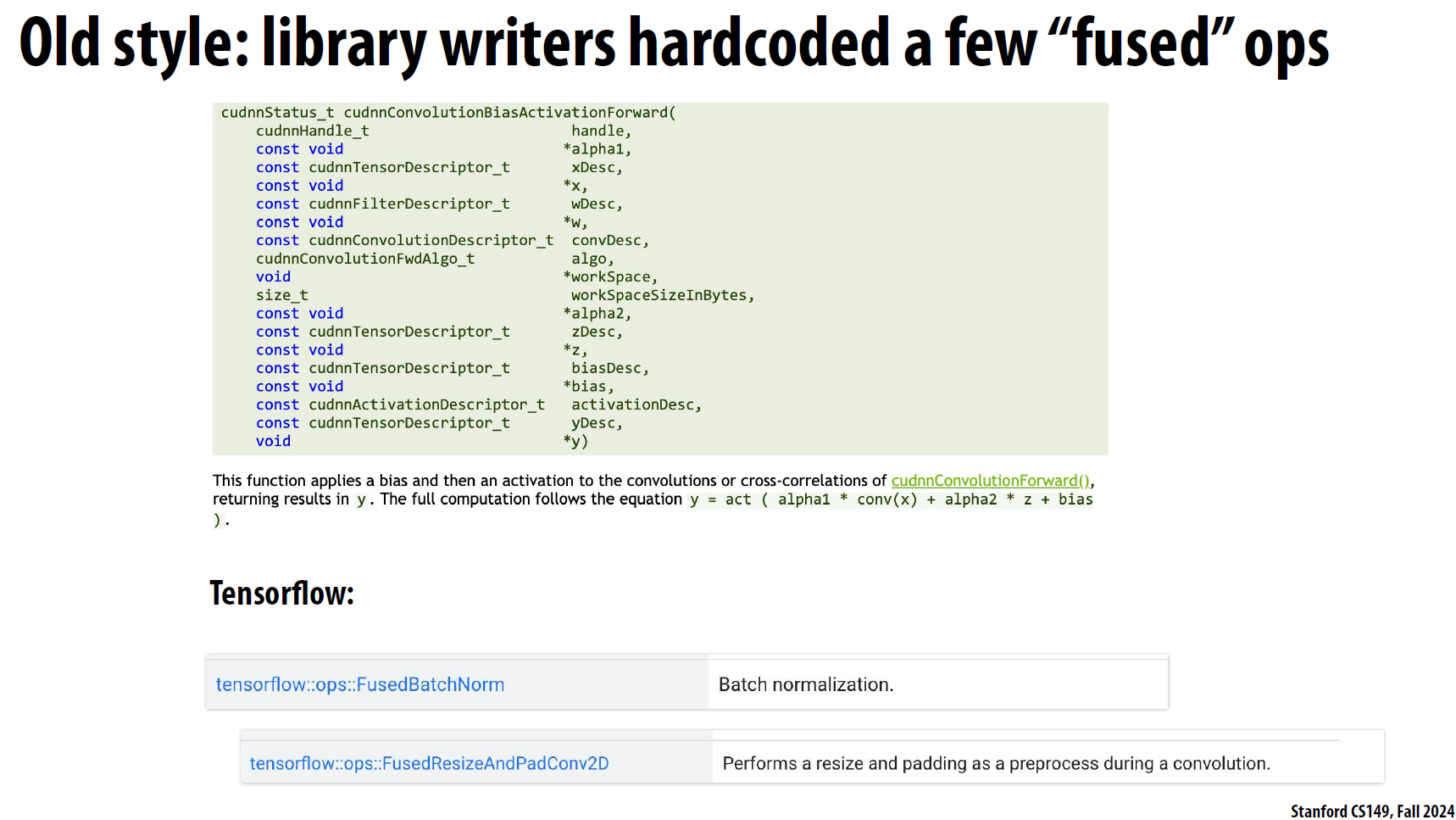
5.2 算子合并
深度学习中, 计算的特征层不断地通过连接的layer作为下一个结构的输入, 最经典的组合包括:
1 | Conv2d + BatchNorm + ReLU |
深度学习框架中有很多算子, 比如BatchNorm, ReLU, LayerNorm等, 这些算子并不涉及复杂的矩阵运算, 并且基本上都可以在原始矩阵中完成原位操作。但是对于过大的矩阵,访问整个矩阵的每个元素本身就是比较耗时的操作,因此,将这些算子合并到类似Conv2d的算子中,可以减少内存访问的次数,提高计算效率。

我们常用的pytorch或tensorflow中, 提供了非常的多的算子合并的api: