这一章的内容是数据并行, 实际上就是讨论很多常用的算子的数据的并行手段, 例如numpy的filter, fold算子等等,操作的数据都是数组或者序列,例如numpy的np数组、torch的tensor等等。难度不大,主要是增长见识。
课程主页:https://gfxcourses.stanford.edu/cs149/fall24
1 Map

Map的每个元素不存在依赖关系,直接分组SIMD即可, 略。
2 Fold

Fold的含义是折叠,即把一个序列折叠成一个值,例如numpy的np.sum,torch的torch.sum,torch.prod等等。通常存在一个初始值,遍历序列时进行指定的操作, 最终生成一个值。 因此Fold的每个元素的计算存在依赖关系,需要分组SIMD。
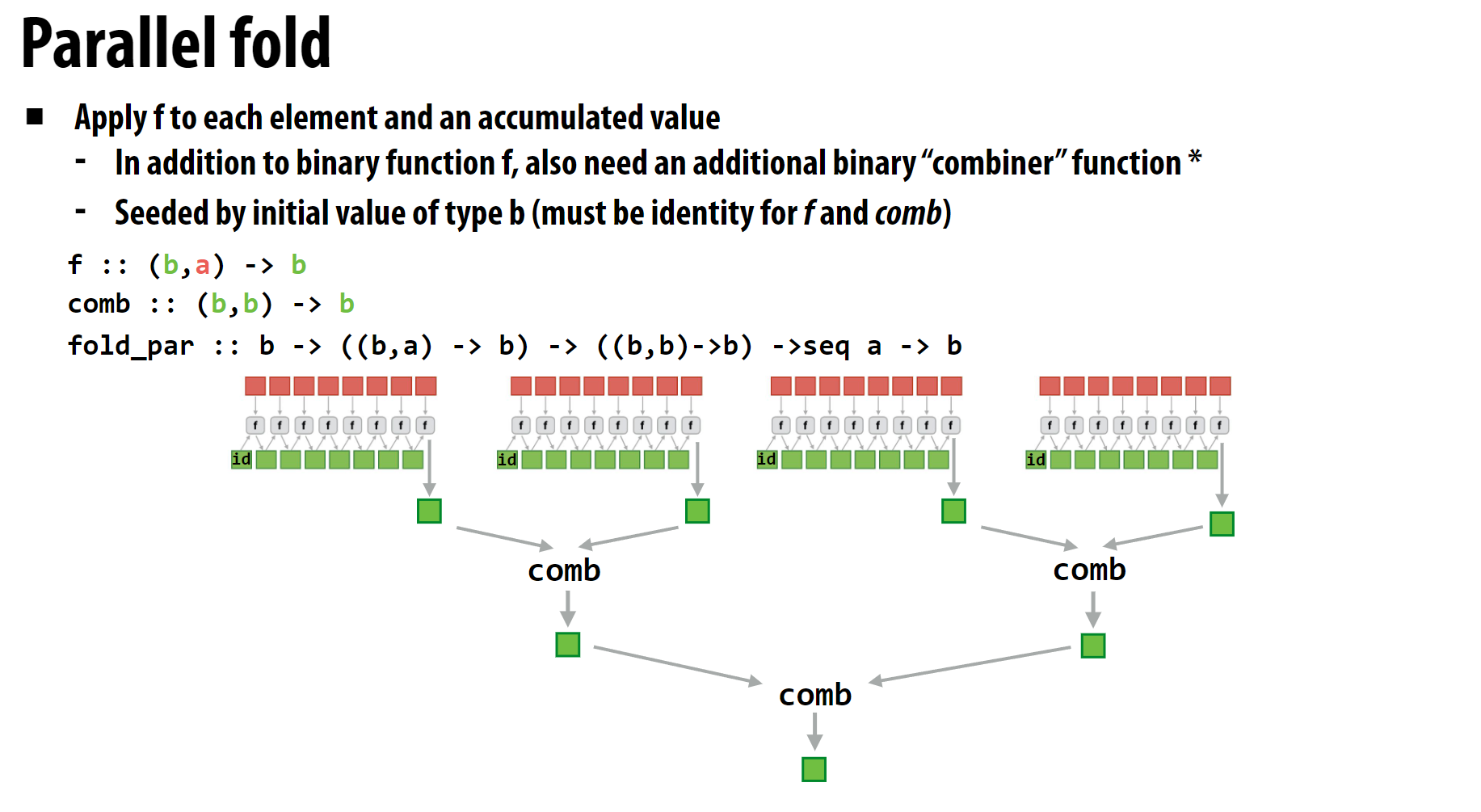
以求和为例, 这里由于每组的元素只需要记录最后的sum值, 因此不同组只需要输出一个值即可, 可以先计算初始值为0的情况下每组的sum值, 然后将各组的sum值及初始值相加, 得到最终的sum值。也很简单不多说了。
3 Scan

Scan的含义是扫描,即把一个序列扫描成一个序列,例如numpy的np.cumsum,torch的torch.cumsum等等。通常存在一个初始值,遍历序列时进行指定的操作, 最终生成一个序列。因此Scan的每个元素的计算存在依赖关系。
这里对Scan进行以下分类, 仍然以求和为例:
包含扫描 (Inclusive Scan):
1
2input: [1, 2, 3, 4, 5]
output: [1, 3, 6, 10, 15]排除扫描 (Exclusive Scan):
1
2input: [1, 2, 3, 4, 5]
output: [0, 1, 3, 6, 10]
Exclusive会多输出一个元素, 通常是初始值,且最后一个元素会被排除。
3.1 Inclusive Scan的并行方法

包含扫描算法的目标是计算一个数组的前缀和,即每个元素是该位置之前所有元素的和。在并行计算中,这个过程可以通过多轮迭代来实现,每轮迭代中元素之间的计算是并行进行的。
这里假设序列长度是2的幂次,记录迭代次数为n, 初始化n=1, 每次迭代n增加1, 直到n=log2(N)。
- 第一次迭代: 将所有以
2^n=2分组的组内最后一个元素的值更新为组内所有元素的和。第一个计算的元素索引为2^(n-1)=1, 可以当做前一个数组长度为1, 1是索引0的下一位, 更新过程:- a1=a0+a1
- a2=a1+a2
- a3=a2+a3
- …
- an=an-1+an
- 自增
n
- 第二次迭代: 将所有以
2^n=4分组的组内最后一个元素的值更新为组内所有元素的和。第一个计算的元素索引为2^(n-1)=2, 因为上一次操作后,前两个元素的值已经更新为正确的值, 此时2 为下一个索引,更新过程:- a2=a0+a2
- a3=a1+a3
- a4=a2+a4
- …
- an=an-2+an
- 自增
n
- …
- 最后一次迭代: 将所有以
2^n=N分组的组内最后一个元素的值更新为组内所有元素的和。第一个计算的元素索引为2^(n-1)=N/2, 因为上一次操作后,前N/2个元素的值已经更新为正确的值, 此时N/2 为下一个索引,更新过程:- an=an-N/2+an
- 跳出迭代
算法总结:
- 复杂度: (O(N \log N)),其中 (N) 是数组中的元素数量。
- 跨度(Span):这里的意思是 (O(\log N)),这是并行计算的深度。
- 低效性:虽然并行算法可以显著减少计算时间,但相比顺序算法,它涉及更多的操作和同步开销,因为同样位置的元素需要多次计算。
通过这种方式,包含扫描算法能够在并行架构中高效地计算前缀和。
3.2 Exclusive Scan的并行方法

这个并行方案就更复杂了, 这里就不介绍其详细的流程, 这个看图更直观。但可以梳理其思路:
- 向上扫描阶段
- 还是以2的幂次分组, 每组内最后一个元素的值更新为组内所有元素的和, 每次迭代后自增2的幂次的指数
- 但这个过程以2的幂次分组的各个组之间是没有交叉的, 例如
a0, a1一组计算,a2, a3一组计算, 但a1, a2不会划到一组计算, 这和上一个并行方案不同 - 由于之间的分组没有交叉, 每次计算的元素只需要将自身的旧值与当前组中间的元素相加即可
- 这个阶段的最后, 中间的元素是前半部分元素的和, 最后一个元素是后半部分元素的和
- 向下扫描阶段
- 这时反向扫描, 由于最后一个元素在
exclusive_scan本身会被排除, 将其值更新为0, 与当前组的中间元素交换 - 反向扫描, 跨度也是2的幂次, 但是是从最大的幂次开始的, 每次迭代后自减2的幂次的指数
- 每次更新的元素也与当前组的中间元素交换
- 这时反向扫描, 由于最后一个元素在
这部分需要观察图仔细理解
这个算法的复杂度就是(O(N))了, 同时大部分操作的2个元素彼此的距离都很近, 符合空间局部性的原则。
多核优化
多核可以按照下面的划分进行分组计算:
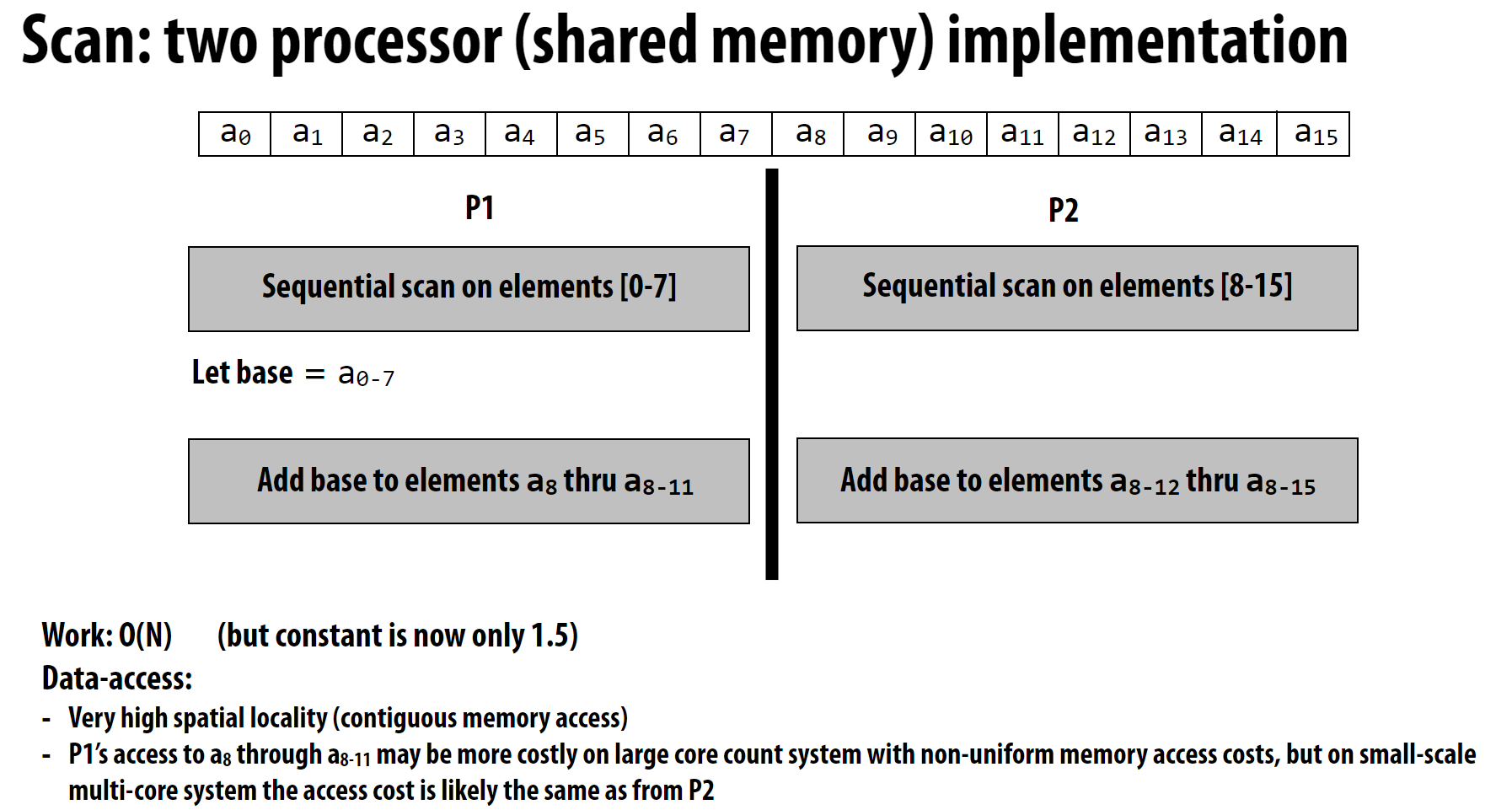
可以看到,基本上不存在跨核的数据通信,符合空间局部性的原则。
CUDA实现
这里介绍第一种复杂度为(O(N \log N))的CUDA实现
1 | __device__ int scan_warp(int *ptr, const unsigned int idx) |
这里返回最后一个元素的值, 因为这些值在别的warp中需要使用。
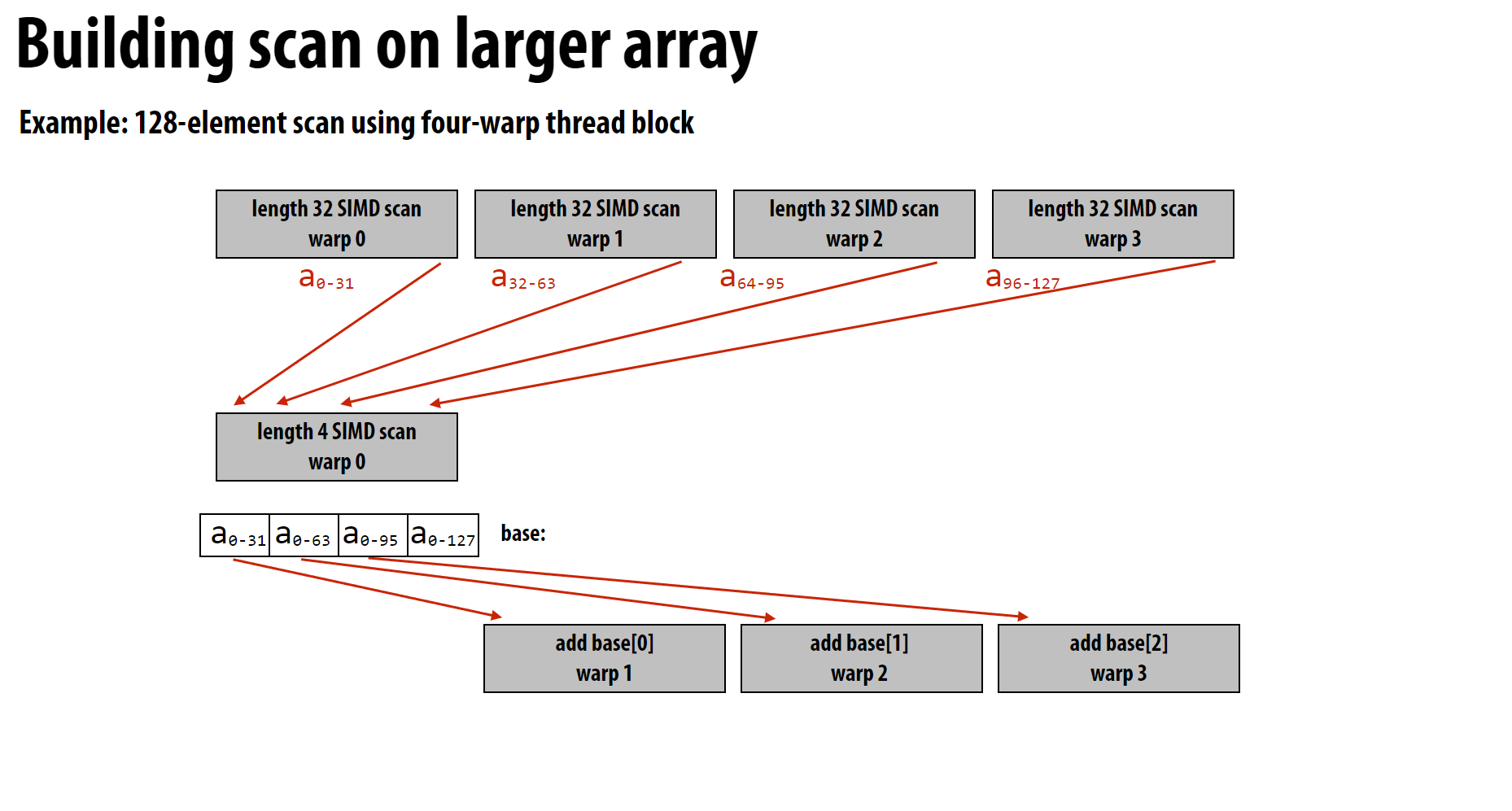
上图就展现了一个block的计算过程:
1 | __device__ void scan_block(int* ptr, const unsigned int idx) |
3.3 Segmented scan
Segmented scan是指序列内部有下一级分组的情况, 例如分组的exclusive sacn:
1 | input: [[1,2],[6],[1,2,3,4]] |
对于这种情况如何利用我们之前的并行方法呢?
可以先给每组开始的索引做一个标记:
1 | input: [[1,2,3],[4,5,6,7,8]] |
过程如下:
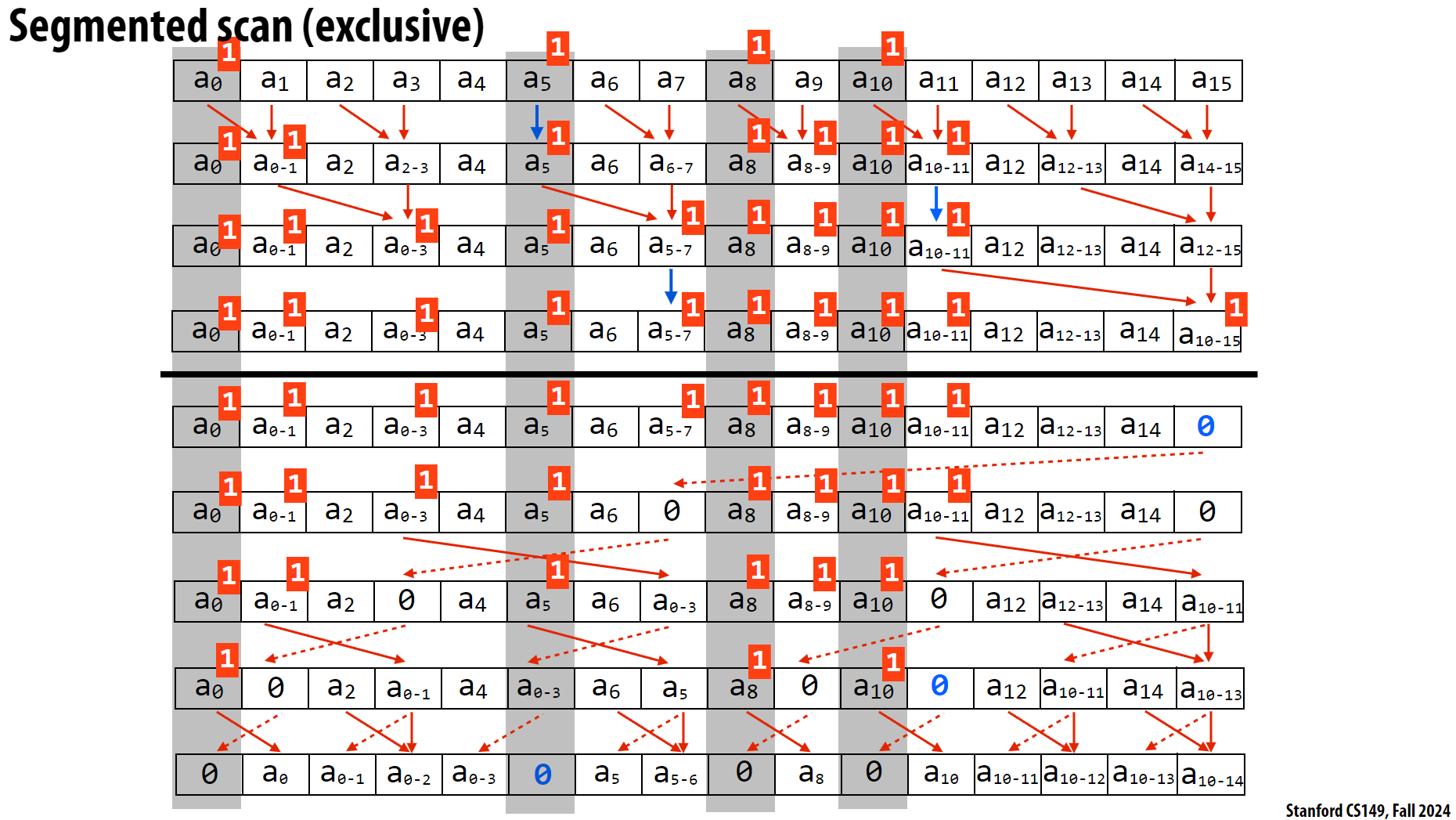
这个算法的要点包括:
- 正向扫描的变化
- 只有
flag为0的元素(这里的flag对应的是后一个操作元素)需要参与计算 - 只要操作的元素中有
flag为1的, 每次运算后将当前元素的flag更新为1
- 只有
- 反向扫描的变化
- 考虑
flag- 中间元素的下一个元素对应的原始
flag(不考虑正向扫描过程中的调整)为1:- 交换后, 将后面的元素置为0
- 中间元素的
flag为1(考虑正向扫描过程中的调整)- 仅仅交换
- 其他情况
- 交换后, 后面的元素设置为二者之和
- 中间元素的下一个元素对应的原始
- 考虑
这里的过程非常绕, 结合图仔细看, 也可以看
PPT中的伪代码
4 稀疏矩阵乘法
4.1 稀疏矩阵的表示

这里使用分组表示, 每行记录非0元素的列索引, 同时记录拉平成一维数组后每行起始非0元素的索引。
1 | values = [ [3,1], [2], [4], ..., [2,6,8] ] |
直接运用之前实现的map和inclusive_scan即可完成计算:

4 Gather/Scatter
gather和scatter是两个非常常用的操作, 分别对应index和input的映射关系, 也就是根据索引选择元素进行输出:
1 | # gather(index, input, output) |
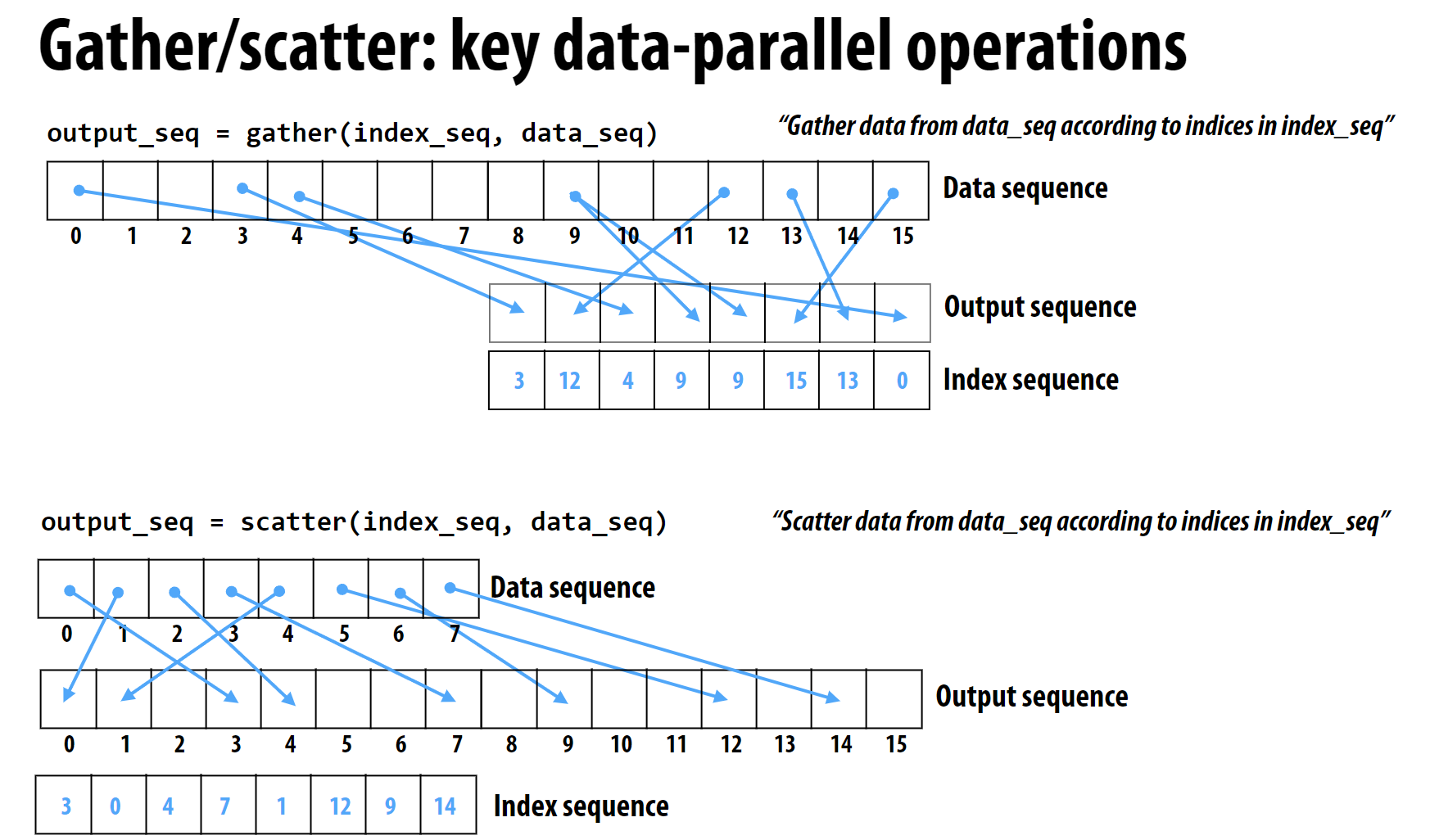
GPU通常直接在硬件层面支持
gather操作, 因此效率很高
课程后面直接是一个具体的N-body问题的案例, 有些复杂不方便梳理, 建议直接去看视频或者PPT。