这节课的内容非常多, 包括GPU的组成和CUDA编程入门与实现原理, 但理解了之后会对GPU的架构和CUDA编程有更深入的理解。部分内容是我结合PPT和网上资料整理的自己的个人理解, 如果理解有误, 欢迎指正。
课程主页: https://gfxcourses.stanford.edu/cs149/fall24
1 图形学和GPU简介
这里的介绍只是大体上让大家知道显卡和图形学的工作内容, 而不涉及更专业的知识。
1.1 网格划分
通常一个3D模型会划分为多个三角形(称为三角形网格), 每个三角形可以表示为三个顶点。这种划分方式是现代计算机图形学中最基础和常用的几何表示方法。
在游戏场景中, 显卡的主要渲染流程是: 在指定的摄像机位置下, 通过几何变换将3D空间中的三角形网格投影到2D屏幕空间, 确定这些三角形覆盖了屏幕上的哪些像素。然后对每个被覆盖的像素点进行着色计算, 考虑材质、光照、纹理等各种参数来决定最终的颜色。这个过程通常称为光栅化(Rasterization)。
下图给定了一个简单的计算案例, 说明了计算中涉及的参数:
- 贴图(myTexture)
- 光源方向(LightDir)
- 像素的法线向量(norm)
- 像素的坐标(uv)
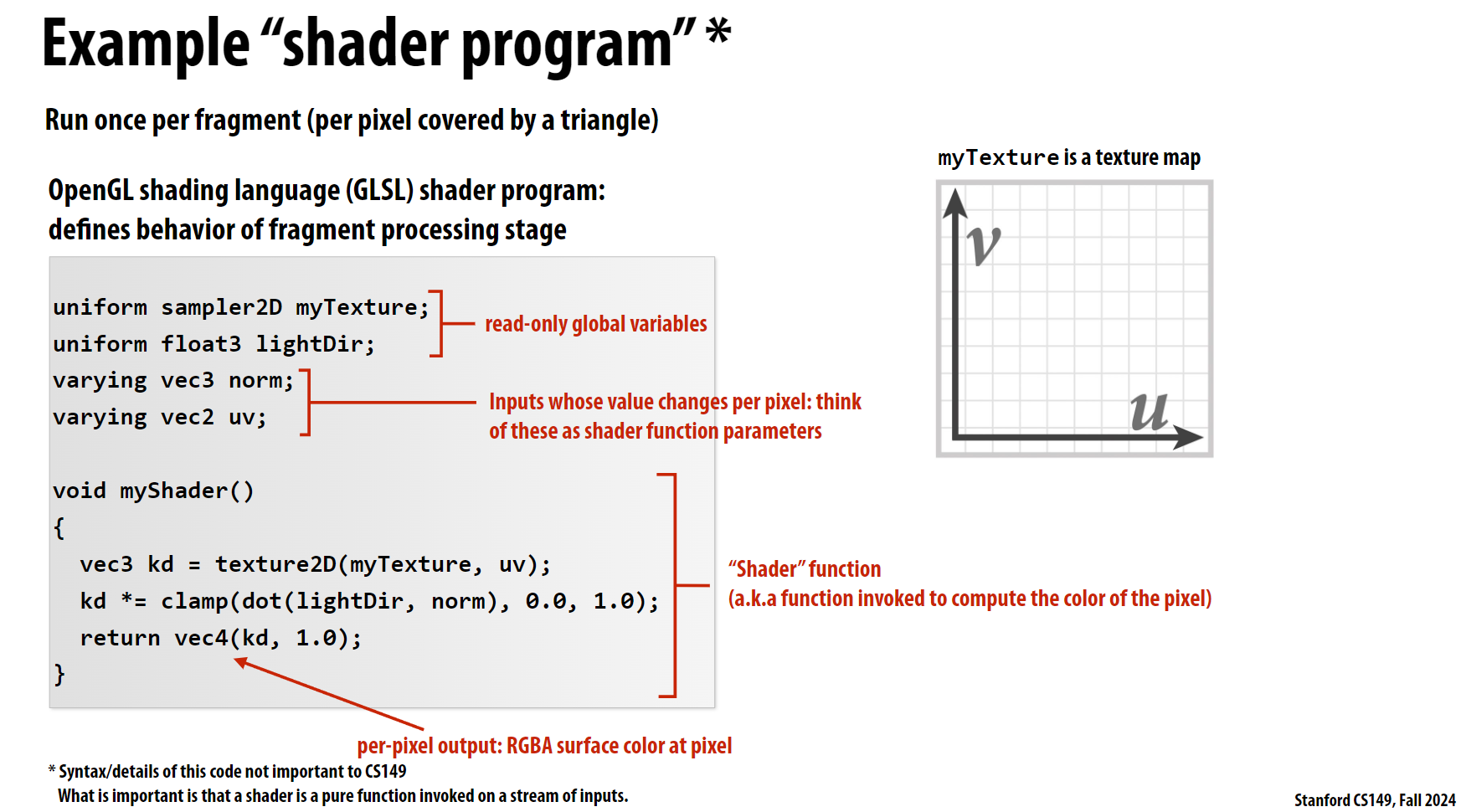
这个案例中, 每个像素点都需要计算一次光照, 且每个像素点之间是独立的, 因此非常适合并行计算。而我们之前学习的CPU进行并行计算时, 核心数乘上SIMD的通道数最多也就是几百这个数量级, 远远小于屏幕的像素点数量。而GPU的架构就是为了并行计算而设计的, 其核心数和SIMD的通道数远远大于CPU, 因此GPU非常适合进行光栅化计算。
2 GPU架构
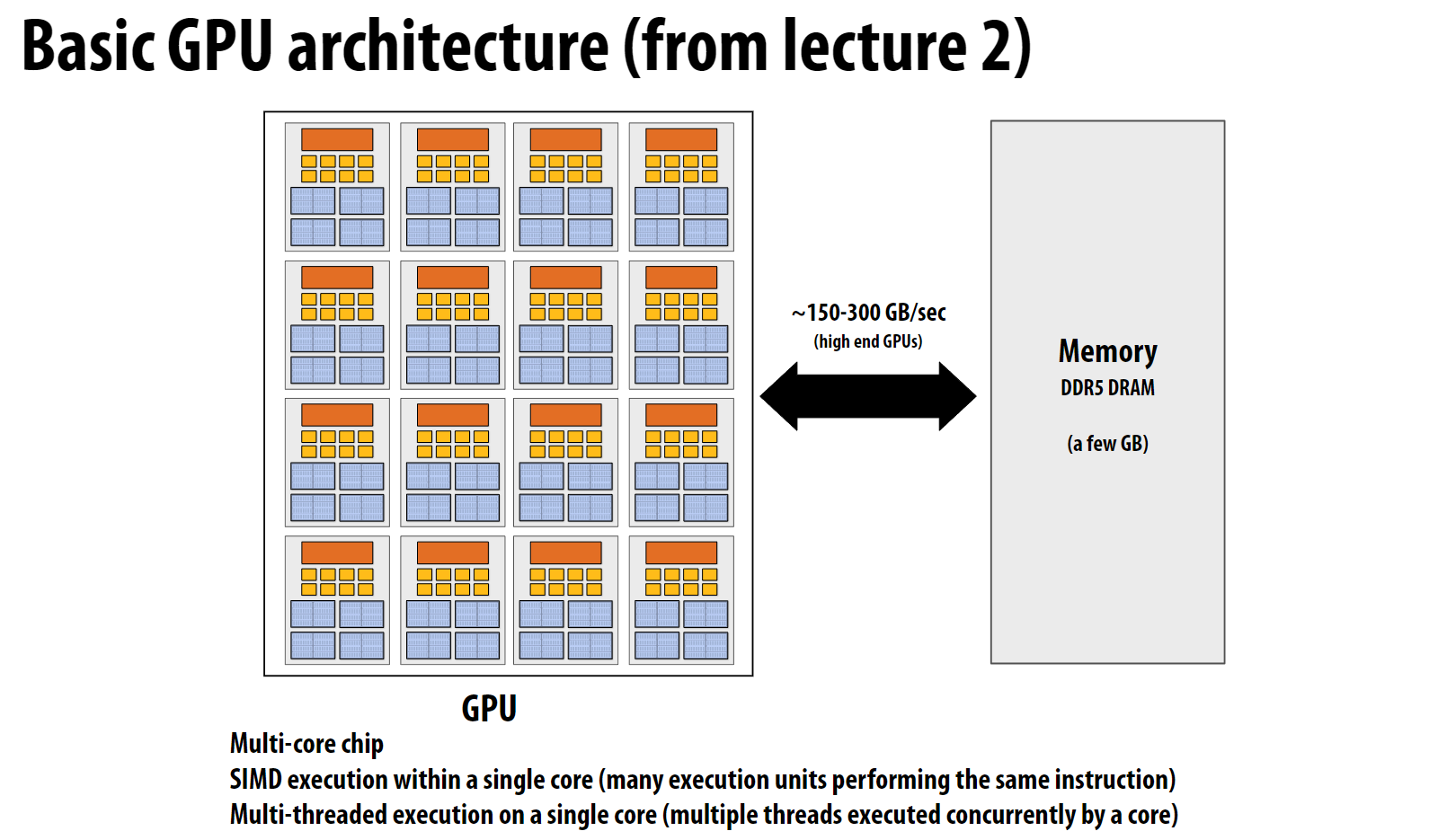
如果你对下面的内容看得一脸懵逼, 请不要担心, 后面会详细介绍, 这里只是先让大家有个印象。我在这里用之前课程中的
SIMD的概念来类比GPU的架构, 如果你忘记了SIMD的概念, 请参考Stanford-CS149-并行计算-Lec02-笔记-多核&&超线程&&SIMD。
上面这幅图是GPU的简要架构, 每个GPU核心(官方称为SM单元)包含非常多的执行单元, 采用SIMD方式执行指令。
- SM单元:全称是
Streaming Multiprocessors, 是GPU的主要计算单元, 类似于CPU的一个核心。每个SM包含多个执行单元,可以同时处理多个线程。 - Warp:GPU中的基本执行单位。通常由32个
CUDA线程组成(好比SIMD中一次加载的8个32位浮点数的集合),这些线程以SIMD方式执行相同的指令。每个Warp中的32个CUDA线程拥有对应的上下文寄存器。 - Grid:是CUDA程序的最高层次组织单位,由多个
Block组成的二维或三维数组。一个kernel启动时会创建一个Grid,Grid中的Block可以分配到不同的SM上并行执行。 - Block:
CUDA线程的集合,是GPU编程中的一个逻辑概念。一个Block中的线程会被分配到同一个SM上执行,但Block本身不直接对应硬件资源。 - CUDA线程:最小的执行单位。需要注意的是,GPU实际上是以Warp为单位调度和执行线程的,而不是单独执行每个线程。
3 CUDA编程
3.1 基础程序结构
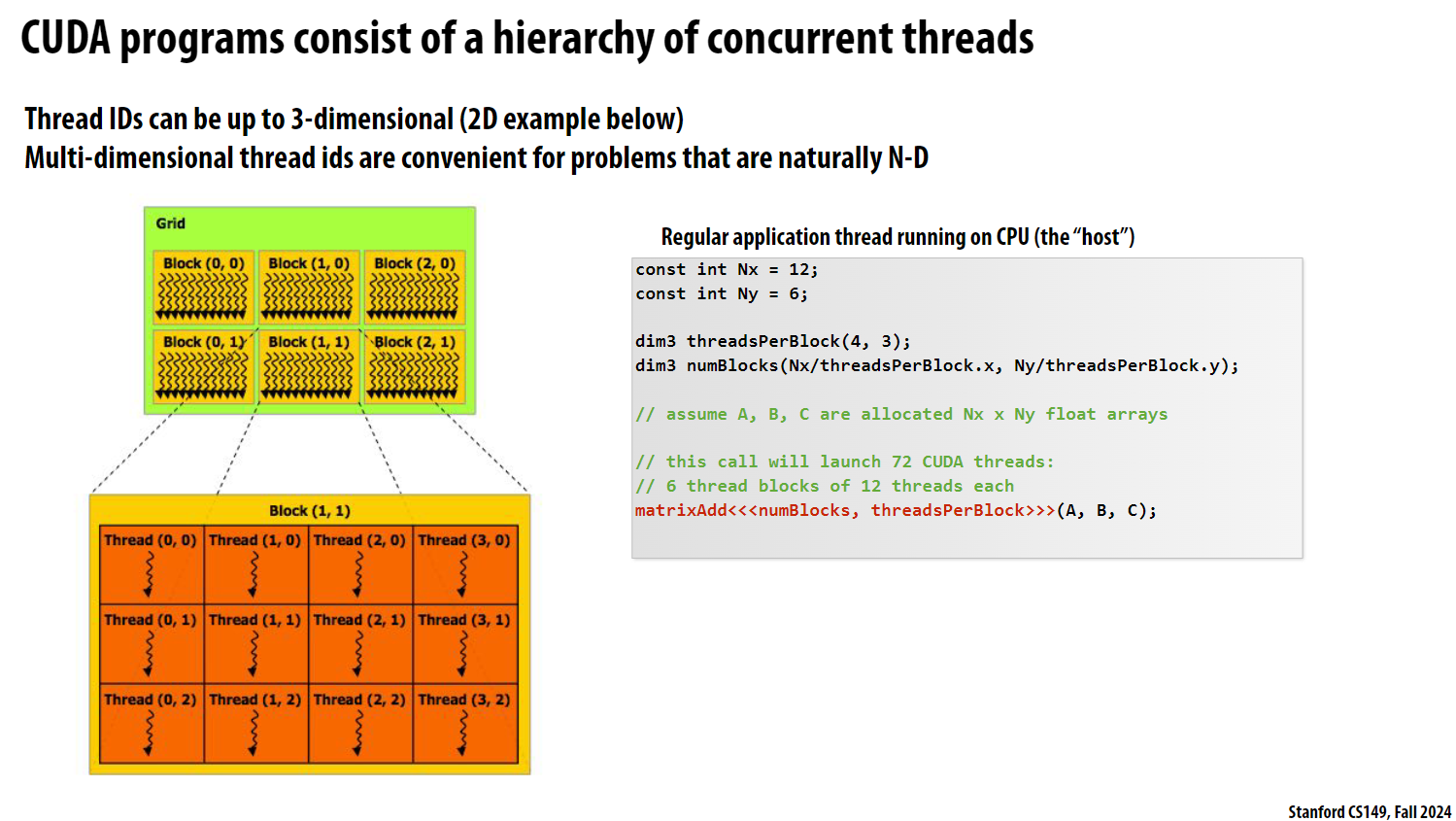
上图介绍了CUDA程序的基本结构。主要包括以下几个要点:
- CUDA程序采用层次化的线程组织结构:
Grid(网格) ->Block(块) ->Thread(线程)。其中Grid和Block都可以是最多3维的(下图给出了2D的例子)。这种多维结构对于处理图像处理、矩阵运算等自然呈N维的问题很方便。 - 图中展示了一个2D的
Block网格(Grid),每个Block中又包含2D排列的CUDA线程。这种层次化的网格结构便于任务的并行化和数据的映射。 - 代码片段演示了如何启动72个
CUDA线程,将其组织成6个Block(每个Block包含12个线程)。这是通过调用kernel函数matrixAdd完成的,该函数接受3个输入数组(A、B、C),并在GPU上并行执行计算。 - 核心要点是CUDA程序通过这种层次化的线程组织结构来实现高效的并行计算。多维的
Grid/Block/Thread结构提供了一种直观的方式,将问题自然地映射到GPU架构上。
接下来看matrixAdd函数:
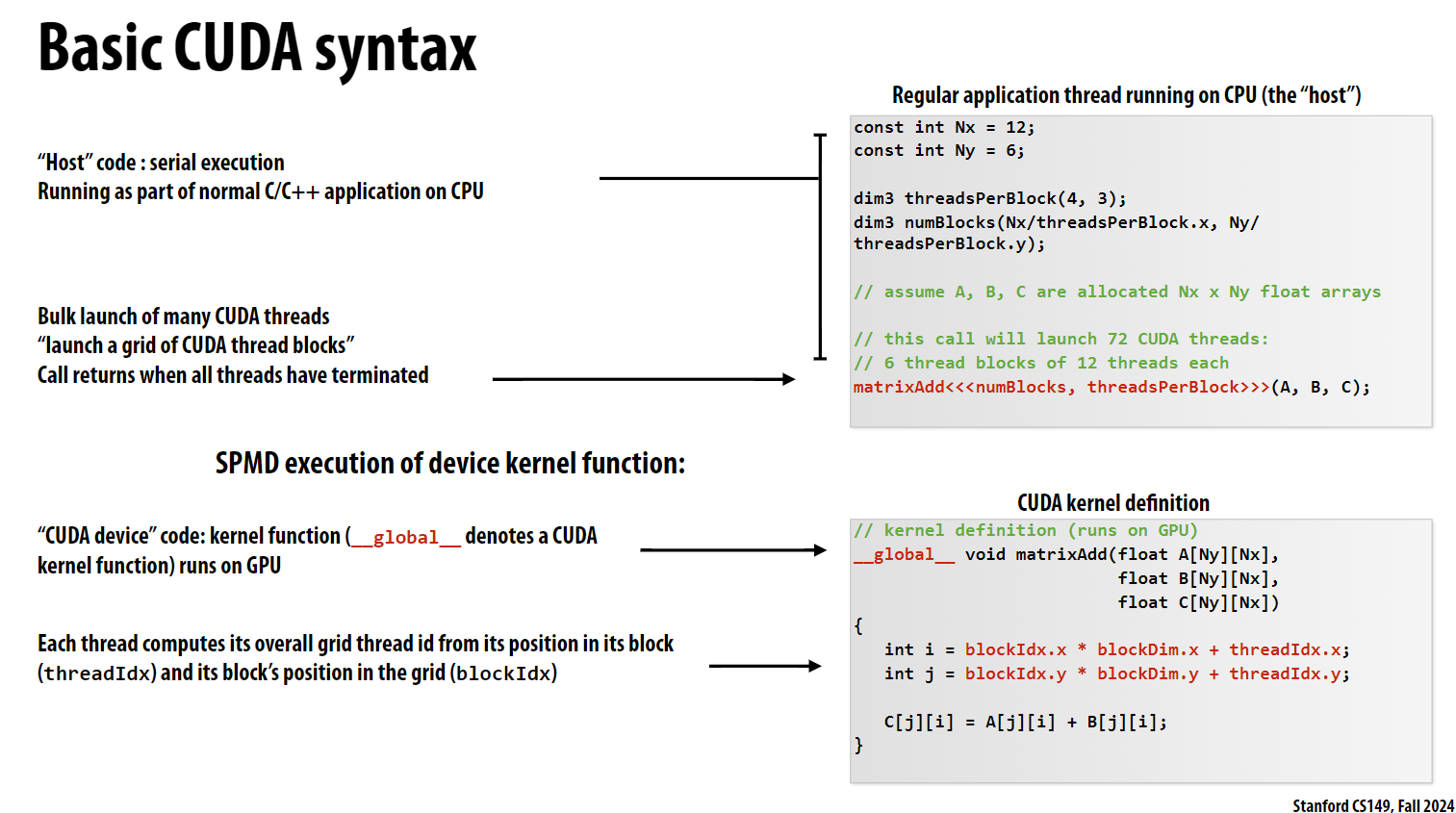
- 批量启动大量CUDA线程: 调用
matrixAdd会在GPU上启动一个网格结构的线程,并等待所有线程执行完毕后返回。 - SPMD执行 - “Single Program, Multiple Data”的缩写。这表示每个CUDA线程都执行相同的内核代码,但使用不同的数据。线程ID可用于确定每个线程应该处理哪些数据。
- CUDA内核定义 CUDA内核使用
__global__修饰符定义,表示该函数在GPU上执行。内核函数可以访问特殊的内存区域,如全局内存中的数组A、B、C。 - 线程ID计算 - 每个CUDA线程根据自己在块中的位置(threadIdx)和块在网格中的位置(blockIdx)计算出自己的全局线程ID。这使得每个线程都能访问对应的数据元素。
- 预定义变量:
blockIdx是一个内置的3D向量变量(blockIdx.x, blockIdx.y, blockIdx.z),用来表示当前线程所在的块在整个网格中的位置。blockDim也是一个3D向量变量(blockDim.x, blockDim.y, blockDim.z),用来表示当前块中的线程数量。
这里再来看CUDA内部函数之间的调用案例:

这里的double_value函数用__device__关键字修饰, 表示该函数只能在GPU设备上运行, 且不能从主机(CPU)代码中直接访问, 只能在GPU内核函数中使用。
3.2 内存模型
CUDA的内存通常与CPU的内存分开, 申请方式如下:
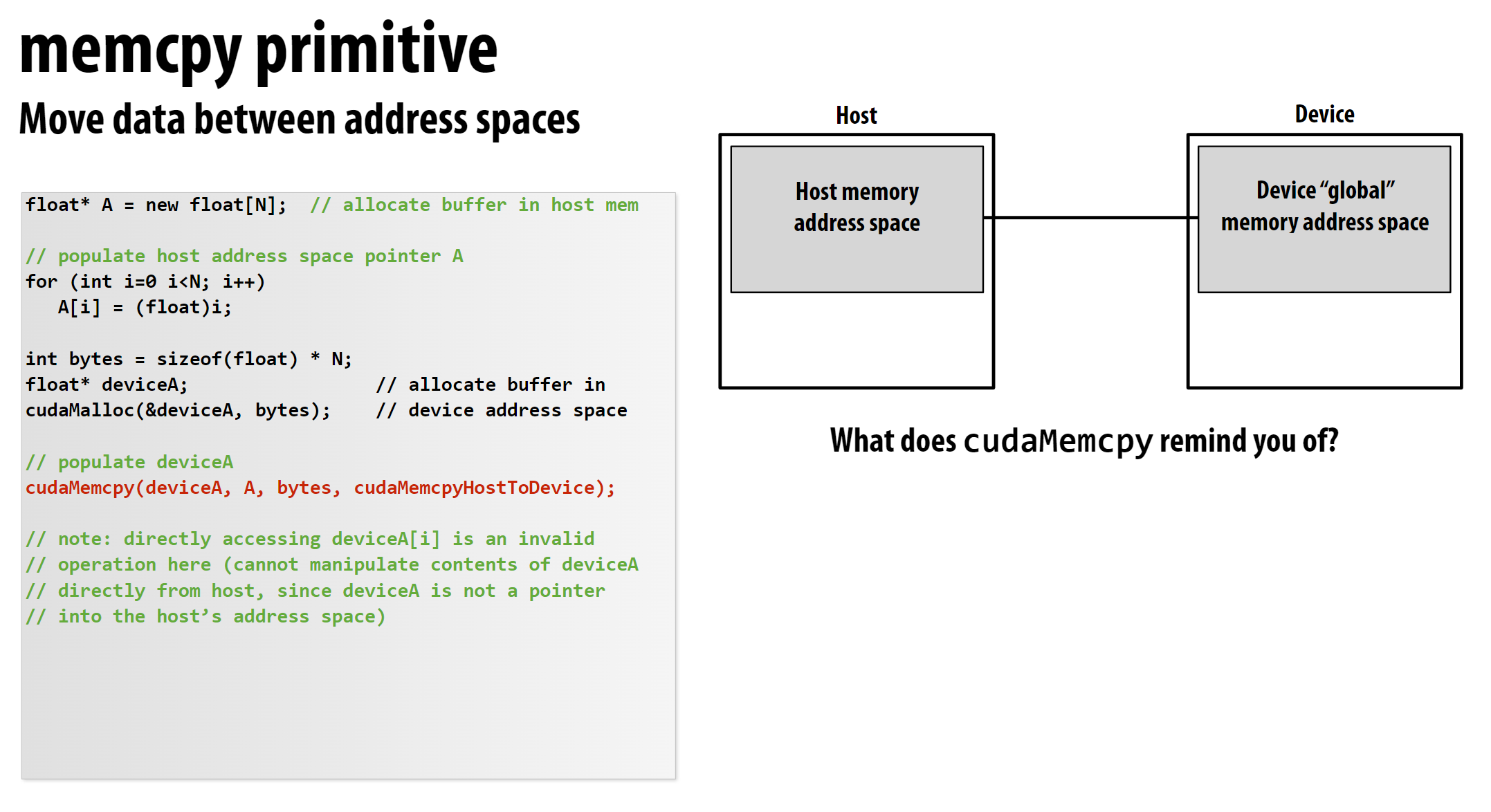
CUDA的内存模型如图所示: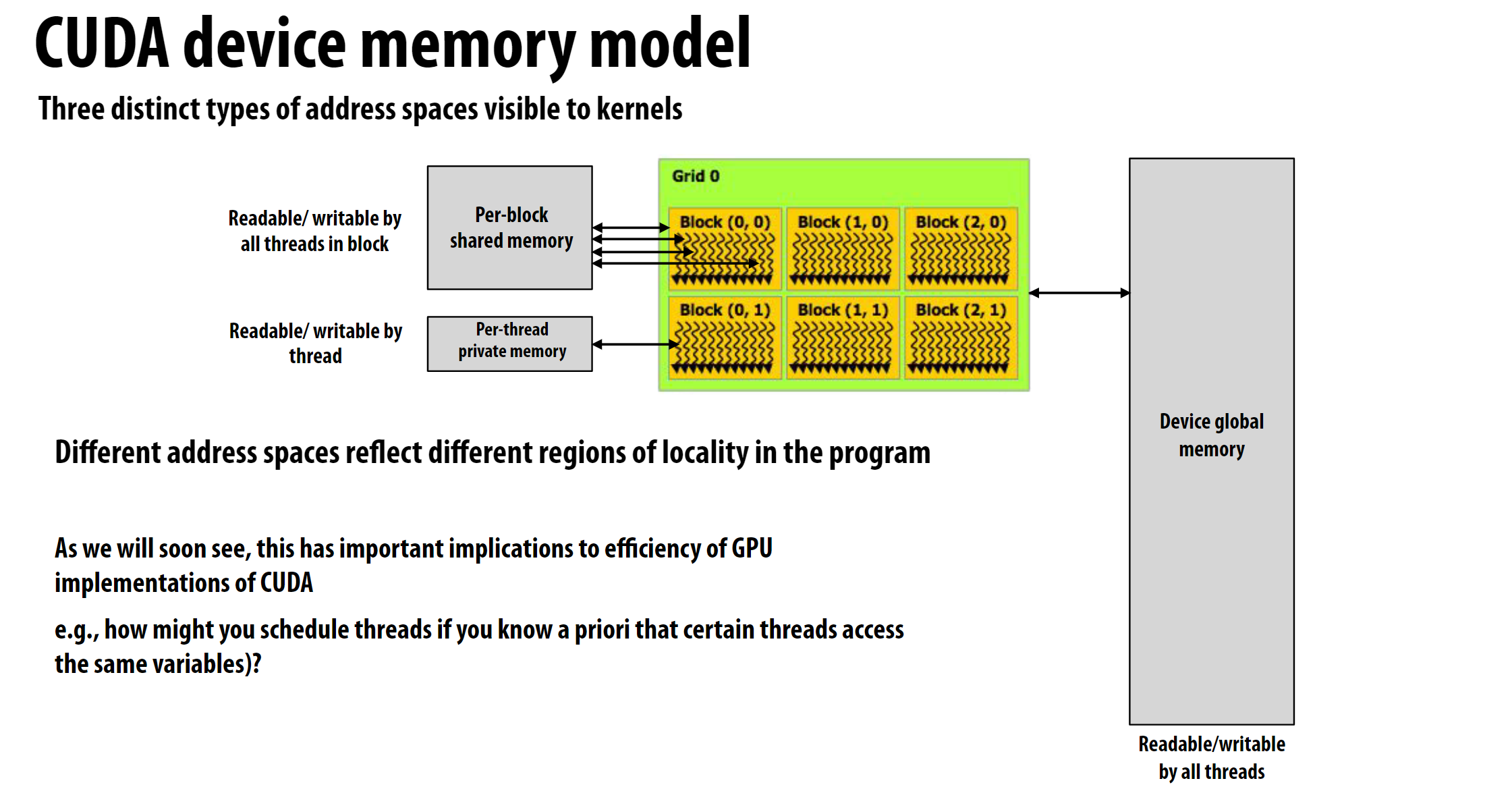
CUDA有三种不同类型的地址空间:
- 每个块内所有线程可读写的块内共享内存
- 每个线程私有的线程私有内存
- 整个设备全局可访问的设备全局内存
3.2.1 CUDA内存局部性的优化方案
以一维卷积为例:
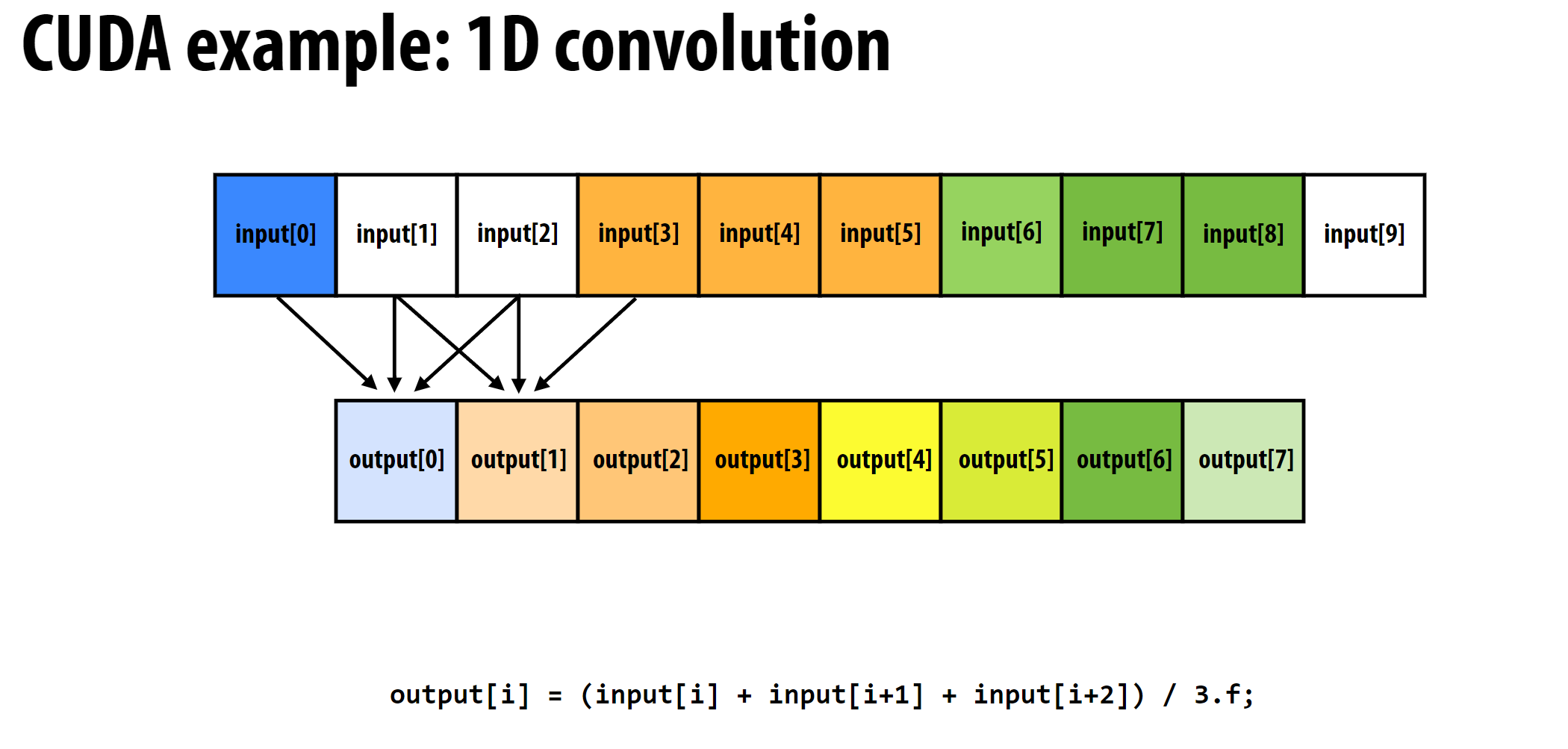
常规的程序设计如下:

问题在于每个CUDA线程都是在全局内存中读取数据, 而全局内存的读取速度远远低于块内共享内存的读取速度。
优化方案如下:

__shared__关键字修饰的变量存储在块内共享内存中, 因此可以大大提高访问速度。__syncthreads()函数用于同步块内所有线程, 确保所有线程都完成共享内存的写入操作后再进行后续操作。
CUDA也支持原子操作, 这里不再赘述。
4 CUDA在硬件上的调度和执行
4.1 CUDA在硬件上的调度
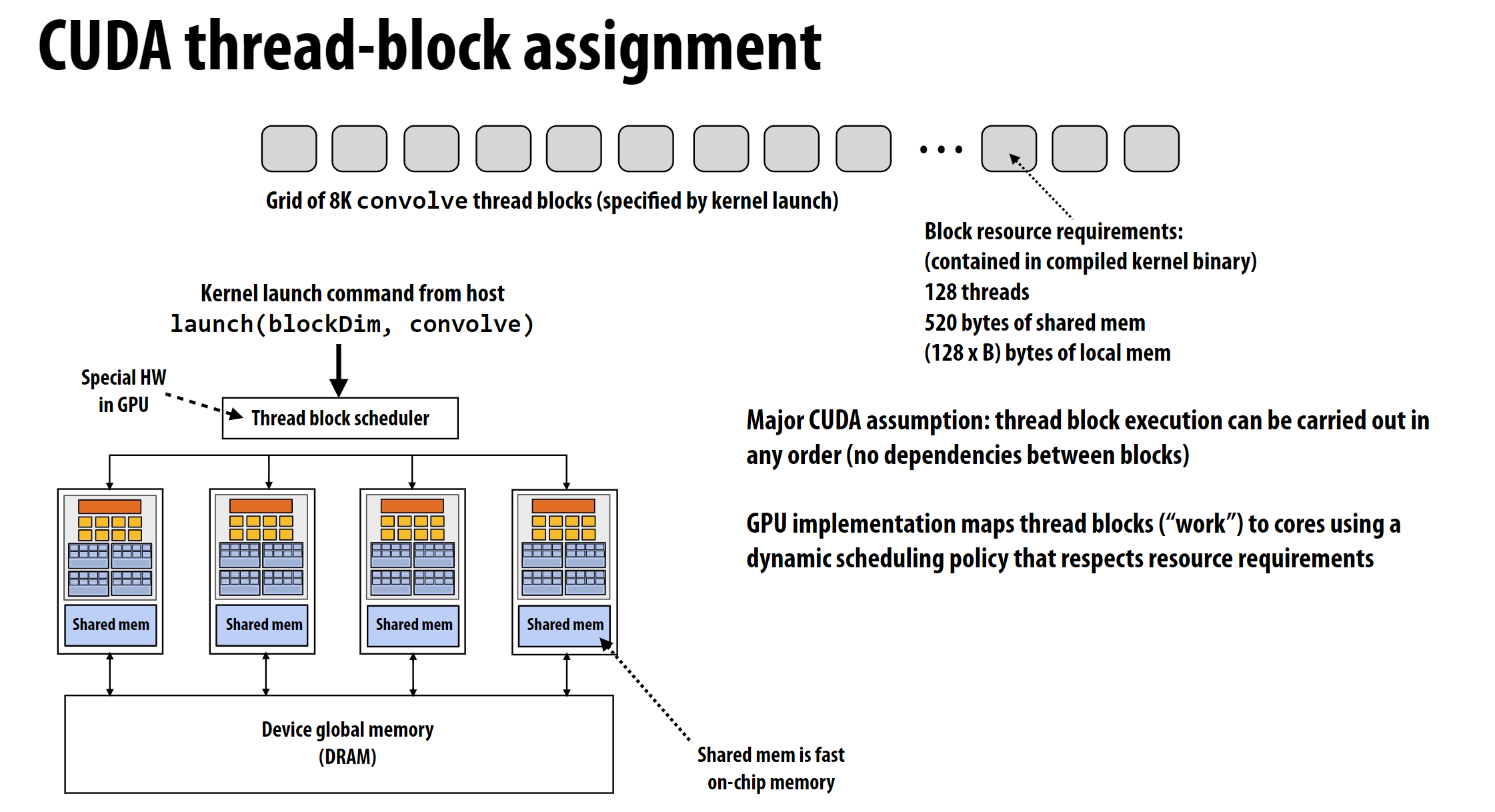
上图展示了CUDA在硬件上的调度方式的一种可能的实现。每个block会被分配到不同的SM(图中的Core)上执行, 每个SM包含多个Warp。图中右下角蓝色方块中每一个由粗实线分隔的方块表示一个Warp。
这里引出了Warp这个概念, 结合下图进行阐释:

Warp简单说就是寄存器的集合, 同时也是调度执行的单位。如图中右下角所示, 横排0-31表示32个CUDA线程的序号, 每一列的R0-R31表示每个CUDA线程上下文的32个寄存器。
这里需要说明的是, 一个
Warp中的32个CUDA线程在执行时, 是同时执行的, 因此一个Warp中的32个CUDA线程的执行速度是相同的。换句话说, 一个SM单元加载数据是以Warp为单位进行的, 因此一个Warp中所有CUDA线程的执行速度是相同的。
这里的
sub-core可以理解为SM单元中的计算模块, 例如tensor core这些都可以看成是sub-core。
block与Warp的关系:
之前说过了, block是CUDA编程中的一个逻辑概念, 一个block中的线程会被分配到同一个SM单元上执行, 但block本身不直接对应硬件资源。一个block中的线程会被组织成一个或多个Warp。例如256个线程的block会被组织成8个Warp。
这里可以与CPU的SIMD进行类比:
- CPU的
SIMD是以线程为单位, 一个线程中的32个SIMD通道是同时执行的。 - GPU的
Warp是以Warp为单位, 一个Warp中的32个(假设是32*8的情况)CUDA线程是同时执行的。 - GPU在实际
Warp这个调度单位上还多了一个block的概念, 一个block中的多个CUDA线程会被分配到不同的Warp, 进而被sub-core调度执行 - 如果
Block的CUDA线程数量超过一个SM的容量,CUDA运行时会拒绝执行该内核,这是不被允许的。相反, 此时应该增加block的数量,block是允许跨SM调度执行的。 - 图中的每个
sub-core将以Warp为单位, 交错调度执行。
4.2 CUDA在硬件上的执行
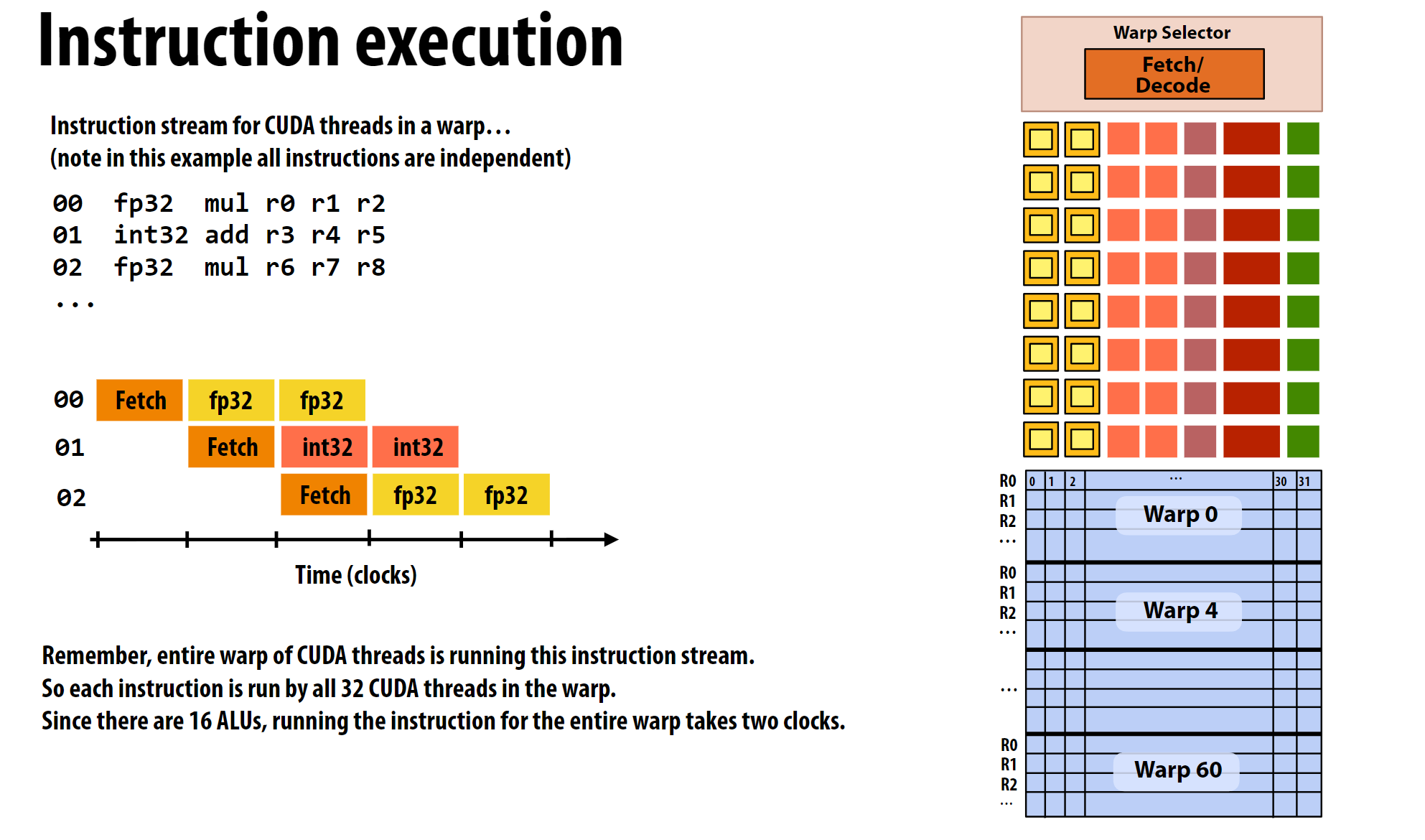
上图是V100的执行示意, 其和CPU类似, 也包含Fetch、Decode过程和数据加载的过程。指的注意的是,这里的ALU只有16个, 因此一个Warp的32个CUDA线程需要2个clock才能完成计算。
4.3 更完整的GPU架构
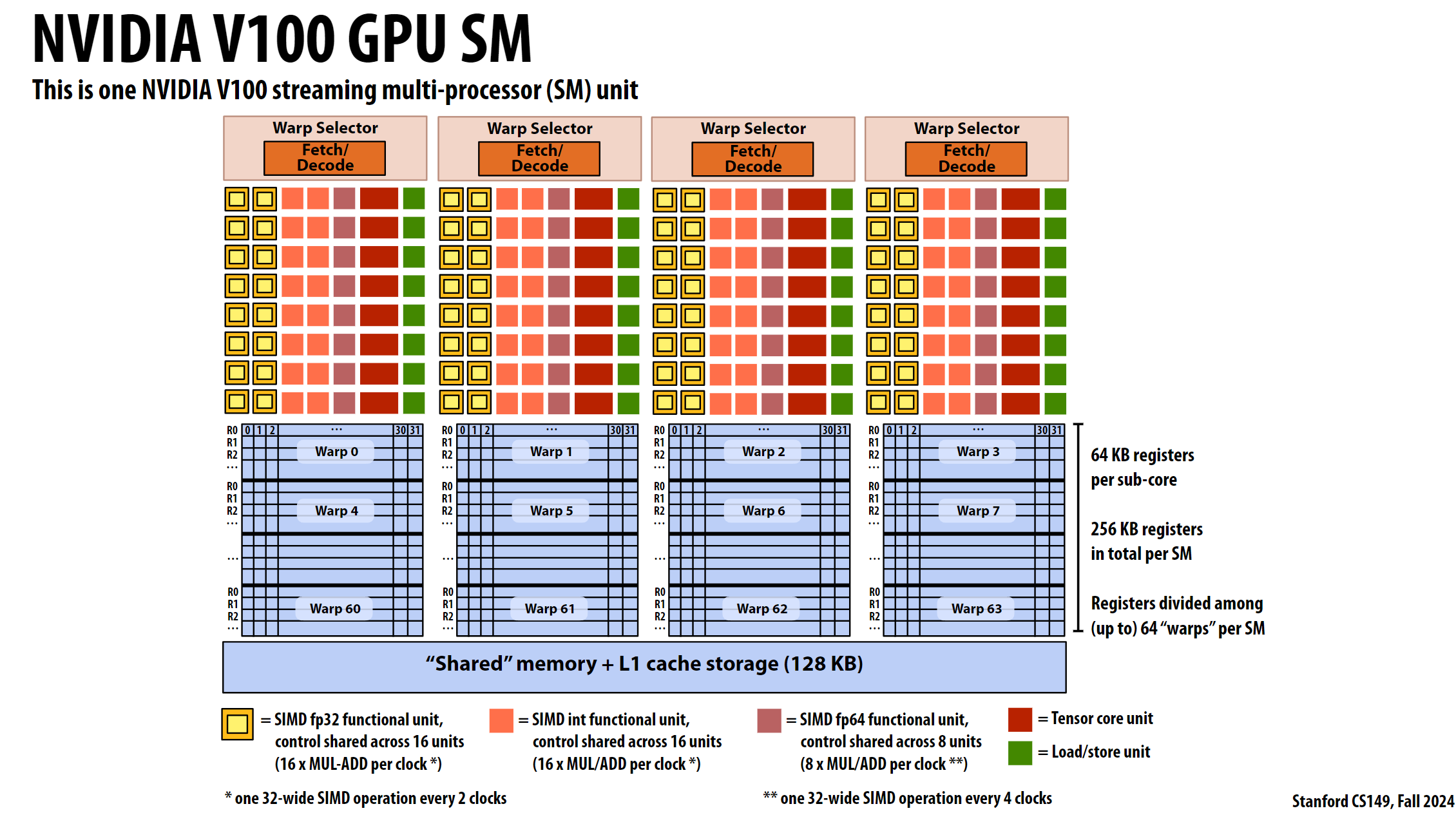
上图展示了V100的4个SM单元, 架构梳理如下
Warp选择器
- Warp Selector: 每个
SM包含多个Warp选择器,每个Warp选择器负责选择和调度Warp。 - Fetch/Decode: 每个
Warp选择器包含Fetch/Decode单元,负责获取和解码指令。
功能单元
- SIMD fp32 functional unit: 黄色方框表示SIMD浮点32位功能单元,控制共享在16个单元之间,每时钟周期执行16次MUL-ADD操作。
- SIMD int functional unit: 橙色方框表示SIMD整数功能单元,控制共享在16个单元之间,每时钟周期执行16次MUL-ADD操作。
- SIMD fp64 functional unit: 紫色方框表示SIMD浮点64位功能单元,控制共享在8个单元之间,每时钟周期执行8次MUL-ADD操作。
- Tensor core unit: 红色方框表示Tensor核心单元,用于深度学习中的矩阵运算。
- Load/store unit: 绿色方框表示Load/store单元,负责数据的加载和存储操作。
Warp
- 之前详细说过, 略
共享内存和L1缓存
- “Shared” memory + L1 cache storage (128 KB): 每个
SM包含128 KB的共享内存和L1缓存存储。
时钟周期操作
- one 32-wide SIMD operation every 2 clocks: 每两个时钟周期执行一次32位宽的SIMD操作。
- one 32-wide SIMD operation every 4 clocks: 每四个时钟周期执行一次64位宽的SIMD操作。
完整的V100:

根据之前的学习, 感受到了老黄的强大了吧, 对核弹的理解又加深了没?
4.4 kernel的执行
这部分PPT有点长, 但有了前文的介绍已经很好理解了, 这里就不再赘述了, 可以去看PPT。
5 总结
这节课的容量非常大,因为GPU以前上计算机组成的没讲过, 所以这节课的内容理解起来有点难度, 不过这部分内容的理解很重要, 因为作业会涉及……