1 静态调度的问题
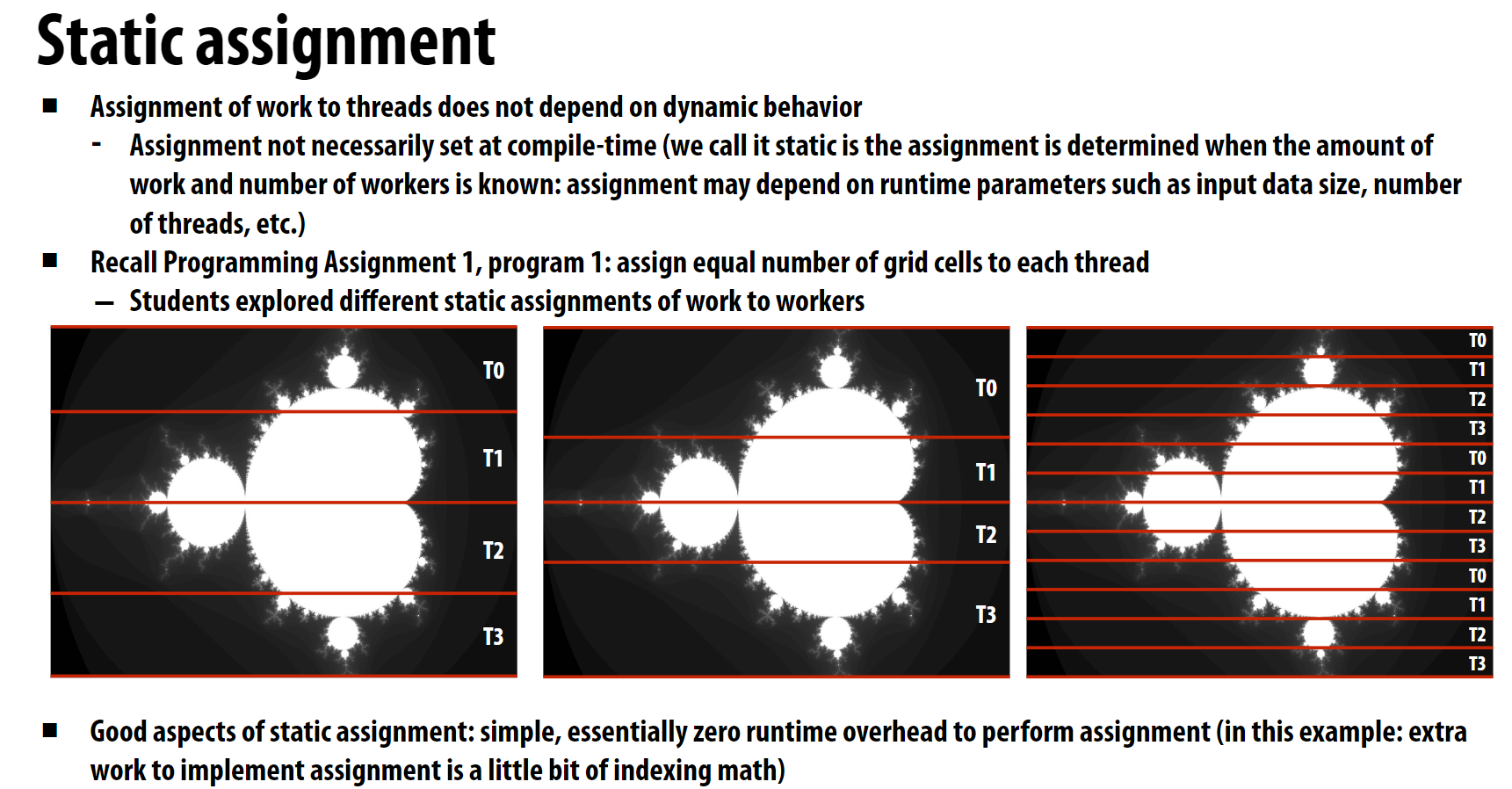
上面这张图对完成了Assignment 1的朋友们应该非常熟悉, 静态分可能导致不同的worker或线程分配到的计算任务不均匀, 从而导致计算资源浪费。最终并行计算的效果受限于最慢的线程, 导致整体计算时间增加。
我们在Assignment 1中的方案是, 依靠我们对计算任务的理解, 手动调整静态分配的策略, 使得不同线程分配到的任务尽可能均匀, 从而提高并行计算的效率。
2 动态调度
2.1 动态调度-任务队列拉取
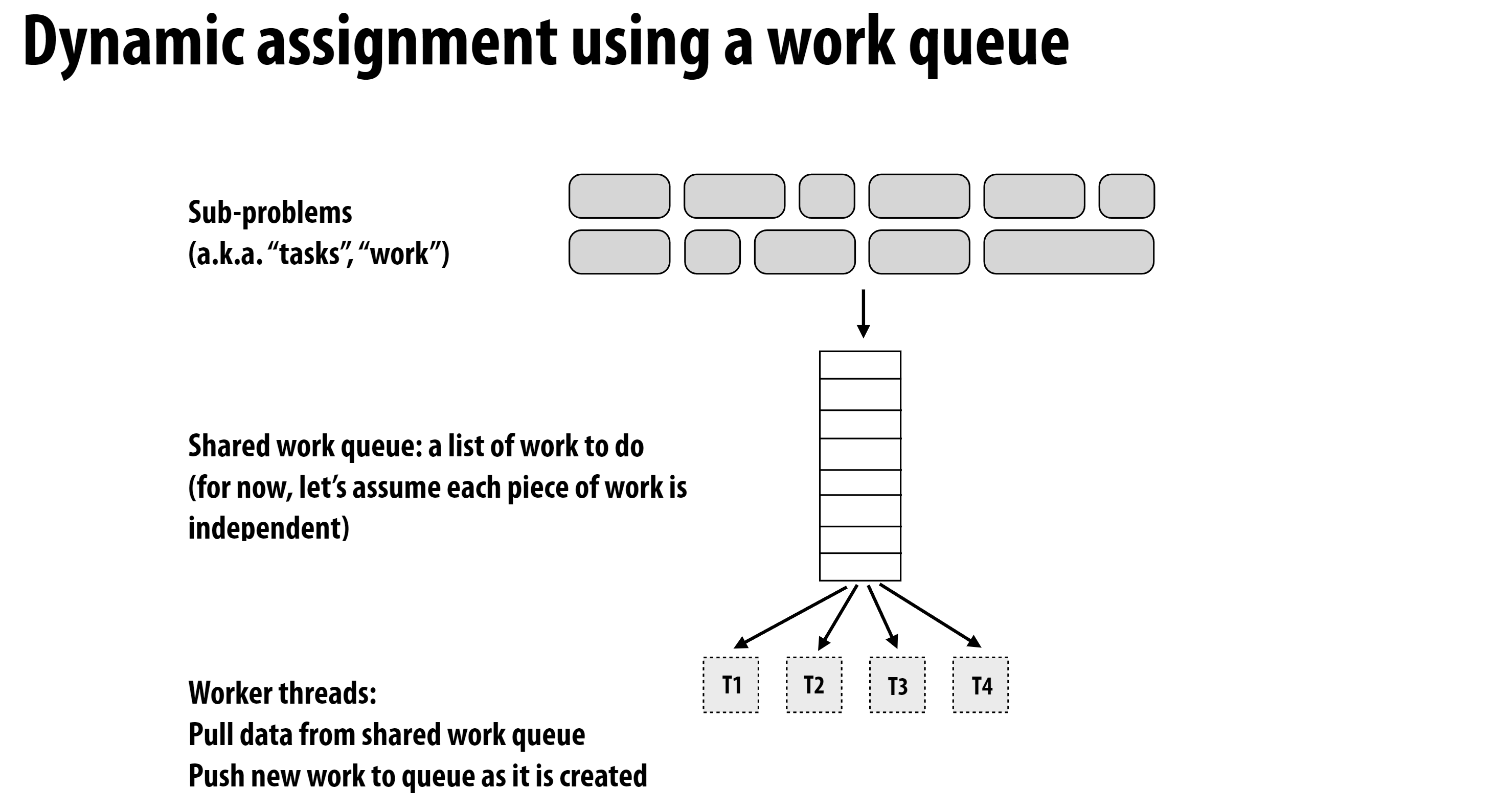
动态调度的一个经典思想就是将任务维护在一个队列中, 每个线程完成计算后从队列中取出任务进行计算。这样的好处是, 每个线程主动拉取任务这一行为就是自身计算资源空闲的表征, 因此使得计算资源在同一时间被充分利用。
其中这个队列是一个抽象的概念, 可以有多种实现方式。例如下面的函数实现了计算质数的任务:
1 | const int N = 1024; |
其队列就是一个整型数counter, 每个线程在完成计算后, 将counter的值加一, counter的值就是抽象的队列元素。
性能问题:
上面这个思路的新问题就在于, 从队列中拉取任务一定涉及相关同步原语的开销, 这些开销与调度的收益之间的权衡是考虑的重点:
解决方案: 增加拉取任务的粒度
在上面的计算质数的案例中, 每次拉取counter的值加一个粒度granularity的值, 而不是每次加一, 并计算[counter, counter + granularity]范围内的数。这样就可以减少锁的开销。

仍然存在的问题:
尽管worker主动拉取任务在大部分时间可以使得计算资源被充分利用, 但是在计算的最后阶段, 仍然可能存在计算资源空闲的情况, 下面的图示充分说明了这一点: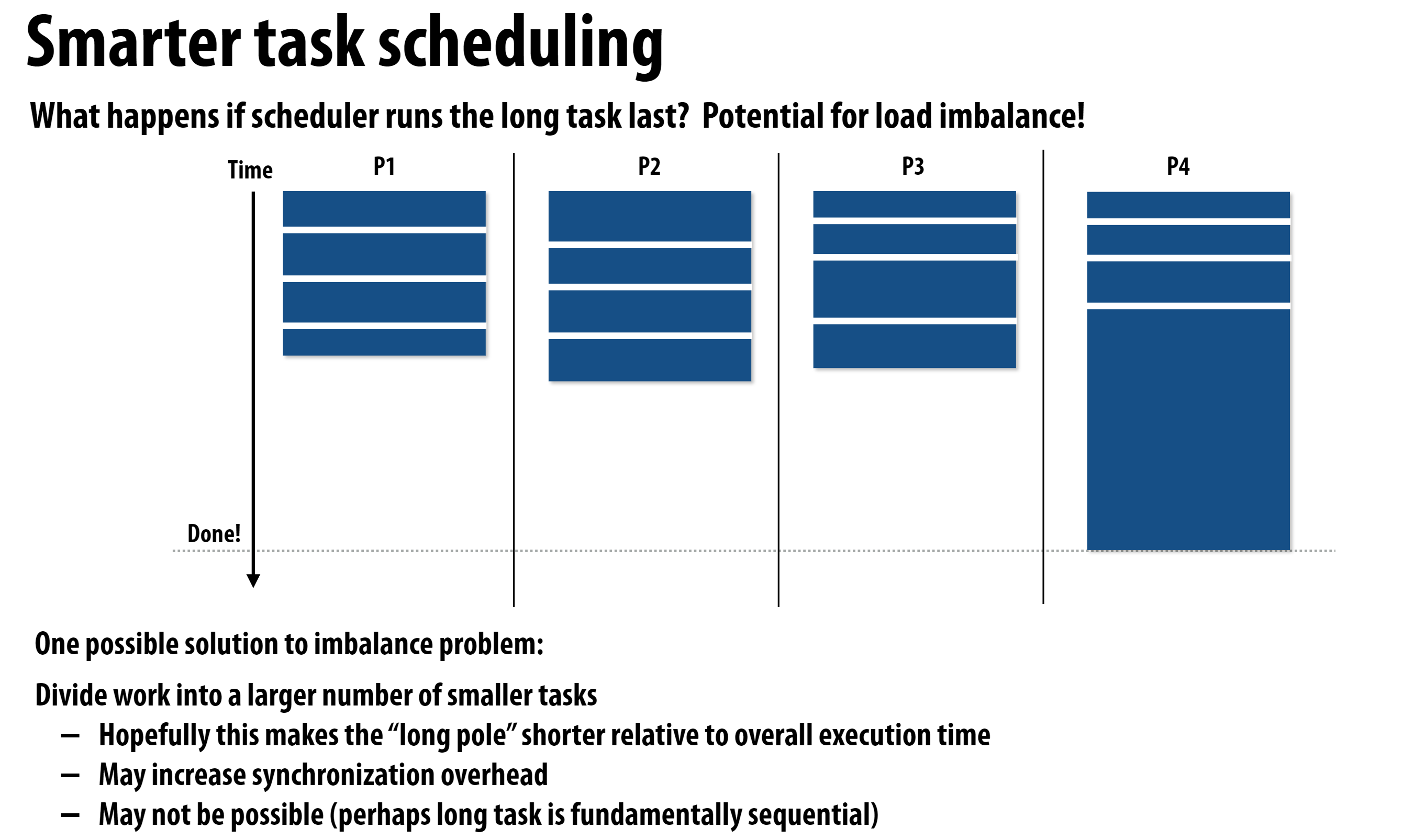
要解决这样的问题, 就需要程序员事先知道各个task的计算规模, 实现合理的调度策略。
2.2 动态调度-Steal Task
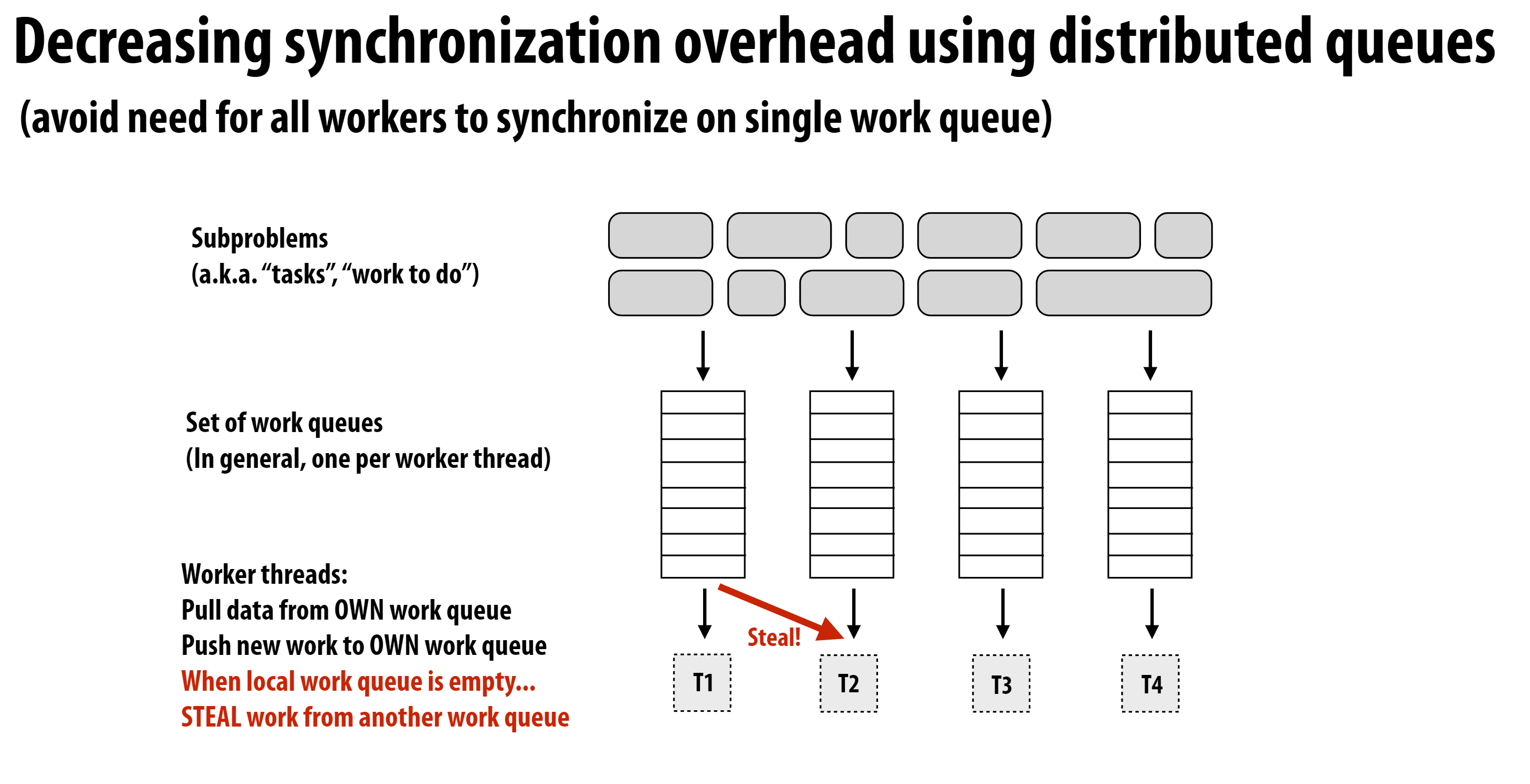
上面的PPT展示了Steal Task的思想, 每个worker或线程拥有自己的任务队列, 而不再是所有的worker或线程共享一个任务队列, 当一个worker或线程完成自己的队列的所有任务后, 可以从其他worker或线程的任务队列中窃取任务。
问题: 如果task有依赖关系呢?
解决方法: 当依赖关系全部满足前, 不能将task加入到worker或线程的任务队列中, 且一个task被完成后, 需要向调度器发送消息, 调度器将更新依赖关系进行xindetask的分配。
3 Cilk 拓展并行编程模型
3.1 基础概念
Cilk 是一种并行编程语言的扩展,最初是为 C 语言设计的。它旨在简化多核处理器上的并行程序开发。Cilk 提供了几个关键字来支持并行编程,其中 cilk_spawn 和 cilk_sync 是两个核心概念。
cilk_spawn
cilk_spawn 关键字用于指示编译器一个函数调用可以异步执行。这意味着当调用带有 cilk_spawn 的函数时,主调函数不会等待被调函数完成,而是继续执行后续代码。这允许程序在多个核心上并行执行任务,从而可能提高性能。
例如:
1 | void foo() { |
在这个例子中,bar() 函数中的 foo() 调用会被立即返回,而 foo() 的实际执行则可能在另一个核心上进行。
cilk_sync
cilk_sync 关键字用于确保所有由 cilk_spawn 派生的任务都已完成。它使得程序可以在继续执行之后的代码之前等待所有子任务的完成。这在需要收集并处理所有并行任务的结果时非常有用。
例如:
1 | int task1(), task2(); |
在这个例子中,main() 函数会启动两个异步任务 task1() 和 task2(),然后使用 cilk_sync 确保这两个任务都已经完成。只有当这两个任务都完成后,final_result 才会被正确计算出来。
3.2 和线程模型的区别
cilk_spawn 和 cilk_sync 是 Cilk 并行编程模型中的关键机制,它们与传统的线程创建(如 POSIX 线程 pthread_create)和线程同步(如 pthread_join)在使用方法上非常相似, 但他们有如下区别:
2. 主要区别
| 方面 | pthread | cilk(Cilk Plus) |
|---|---|---|
| 抽象层次 | 低级(线程级别) | 高级(任务级别) |
| 开发难度 | 需要手动管理线程创建、同步等,难度较高 | 自动管理并行任务,使用简单 |
| 性能优化 | 由开发者控制线程分配和负载平衡,优化空间大但需经验 | 底层由运行时自动优化线程和任务调度,用户无需关心细节 |
| 任务分解方式 | 开发者需手动分解任务 | 通过 cilk_spawn 等简单标记分解任务 |
| 硬件利用率 | 开发者负责显式分配线程 | 自动分配资源和负载均衡,充分利用多核 CPU |
| 应用场景 | 高性能计算中需要精细控制的并行场景 | 面向数据并行或计算密集型的任务,例如科学计算 |
换句话说, cilk_spawn创建的任务与线程不一定是1:1的关系, 当cilk_spawn创建的任务数量远大于线程时, 编译器会负责将其分配到数量更少的线程上执行, 并实现调度。
3.3 cilk并行模型的调度
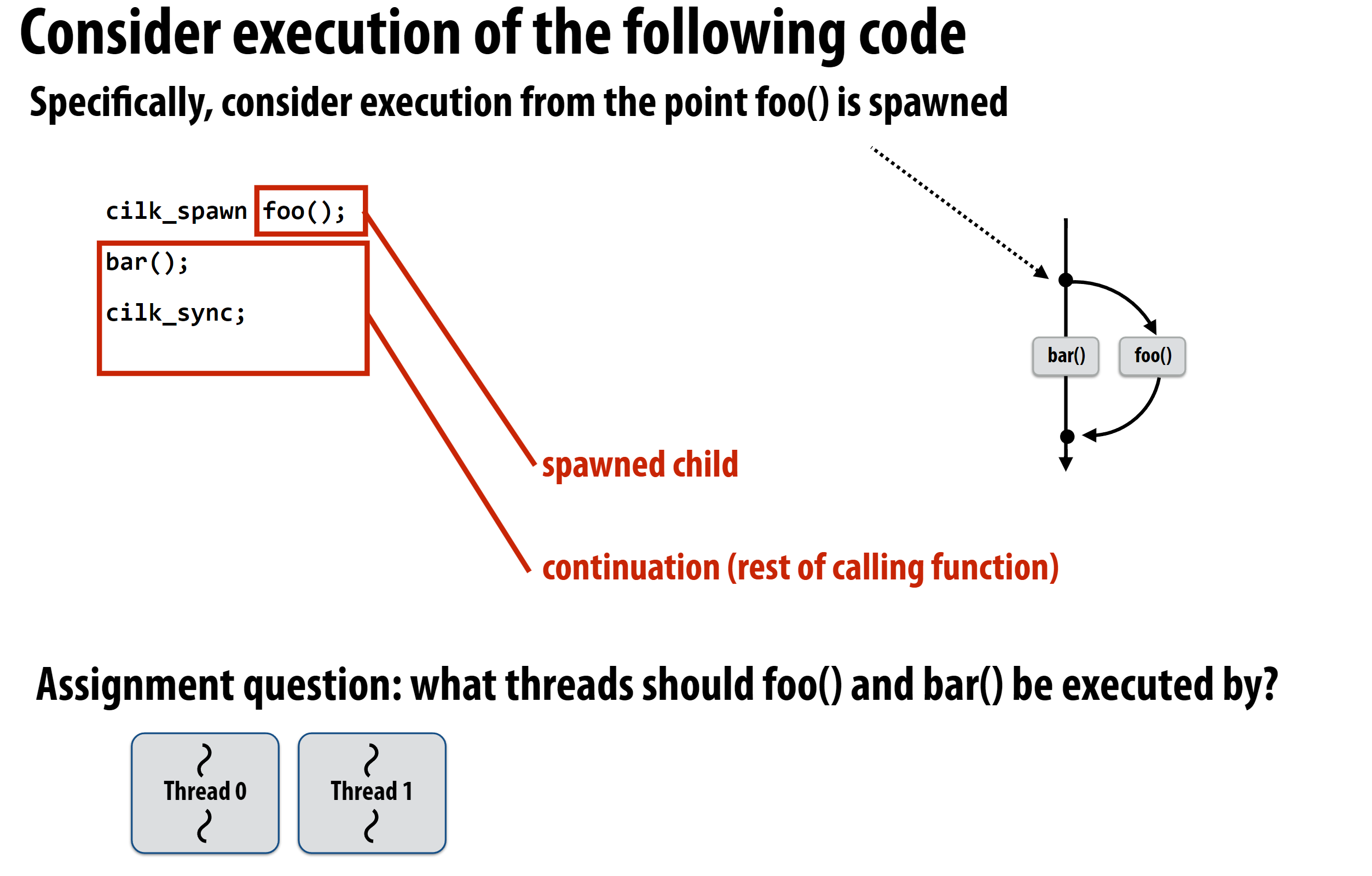
这里统一术语:
cilk_spawn创建的任务称为childcilk_spawn的调用者继续执行的任务称为continuation
有如下的调度策略选择:
先执行child, continuation被其他线程窃取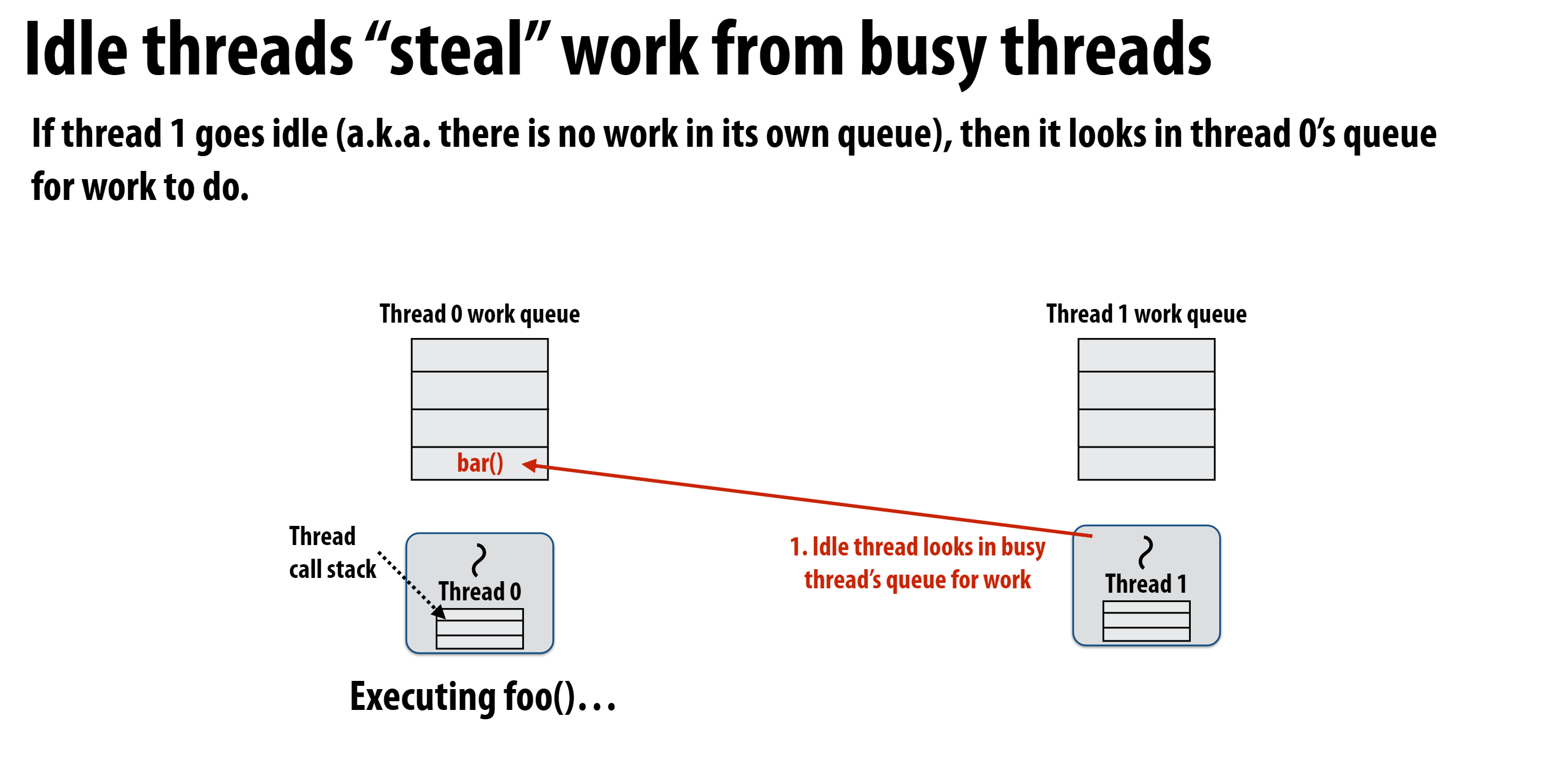
先执行continuation, child被其他线程窃取
与上一个情况相反, 不截图阐释了
共同特征:
无论先执行哪一个任务, 都需要将另一个任务放到自己的任务队列中, 这个任务也许会被其他线程窃取, 也许会在稍后被自己继续执行。
考虑下面的场景:

主线程在for循环中不断创建child任务, 并在循环后执行cilk_sync等待其完成。
如果采用先执行continuation的调度策略, 则所有的任务会先被放在自己的任务队列中, 直到for循环结束。
如果只有一个线程, 不会发生窃取, 则执行的顺序与移除了cilk_xxx的串行执行是不同的。
如果采用先执行child, continuation被其他线程窃取的调度策略, 则cilk_spawn创建的child任务会立即执行, 而continuation会放在自己的任务队列中等待其他线程窃取:

这种情况下, 执行的顺序与移除了cilk_xxx的串行执行是相同的。
另一方面, 让我看一下task被窃取的情况, 被窃取的task所属的线程像迭代器一样将下一个要执行的task放在自己的任务队列中以供其他线程窃取:

3.4 窃取调度进阶——quick-sort
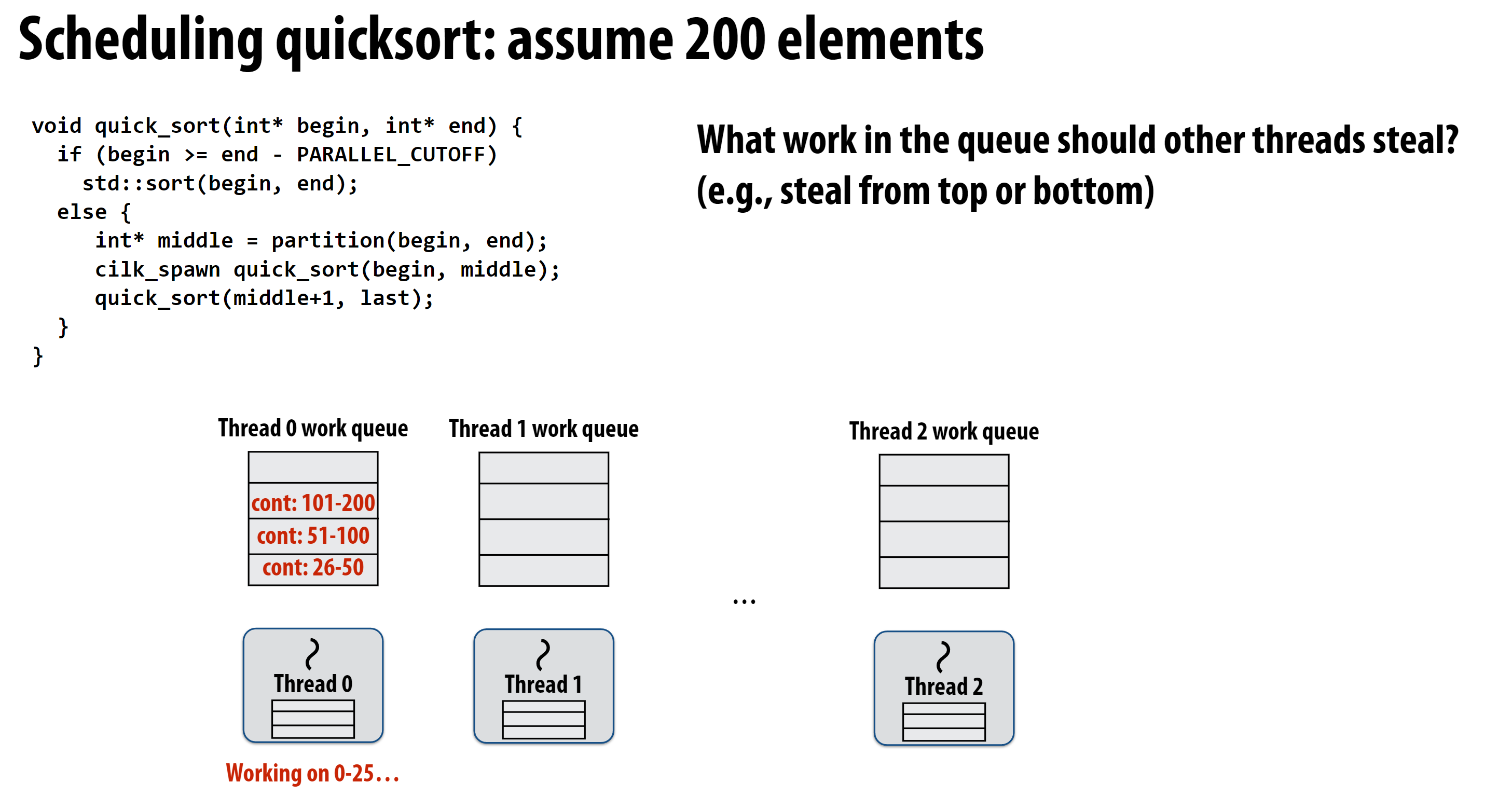
上图是采用窃取调度策略的quick-sort的并行执行过程, 随着任务的执行, 每个task的计算量越来越小, 因此其他线程窃取任务时面临如下的选择:
- 窃取队列头部的大计算量的
task - 窃取队列尾部的小计算量的
task
最佳方案:
其他线程窃取task时从顶部窃取大计算量的task, 而被窃取线程从尾部不断插入新的小计算量的task。这样的目的是符号整个计算流程的趋势, task的计算量越来越小, 选择大计算量的task更接近被窃取线程当前的计算量, 从而平衡不同线程的计算量。
3.5 窃取调度进阶——sync的实现
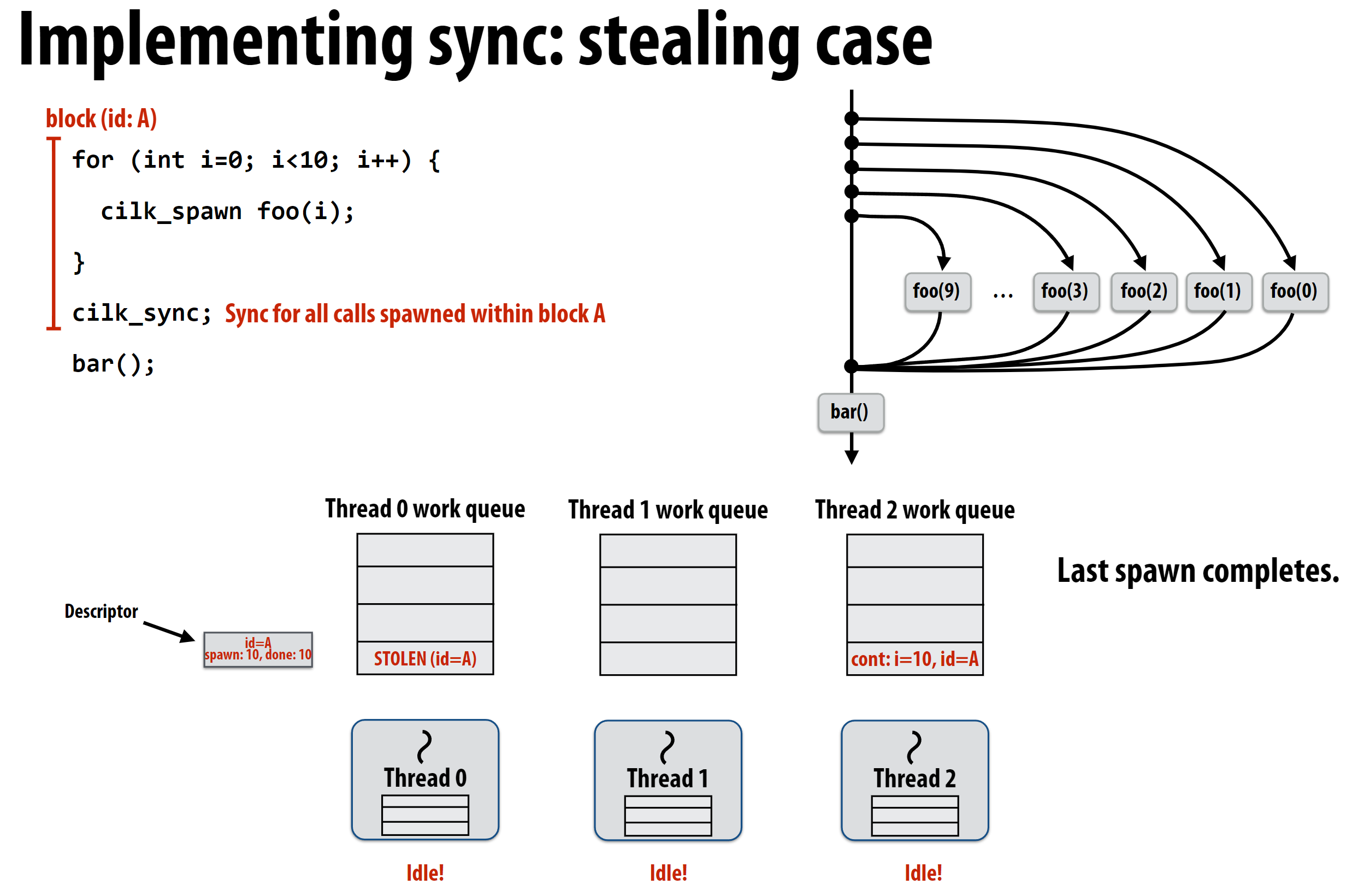
sync的实现在之前的窃取思想上添加了一个修改描述符(descriptor)的步骤, 从而使得调度器可以知道哪些task被窃取, 哪些task被窃取线程执行。每次窃取任务意味着当前任务完成, 同时这次窃取任务也会拿到一个新的窃取任务, 因此可以不断更新描述符中被窃取的task总数量和被窃取的task中已完成的数量, 直到二者相等, 则意味着sync不必等待, 可以继续执行。