本节课程的内容相对简单, 很多内容大家在学习C++或者Java并发编程的时候都已经接触过了, 因此本笔记将只会记录相对陌生的部分。
课程主页: https://gfxcourses.stanford.edu/cs149/fall24
1 并行编程的整体思路
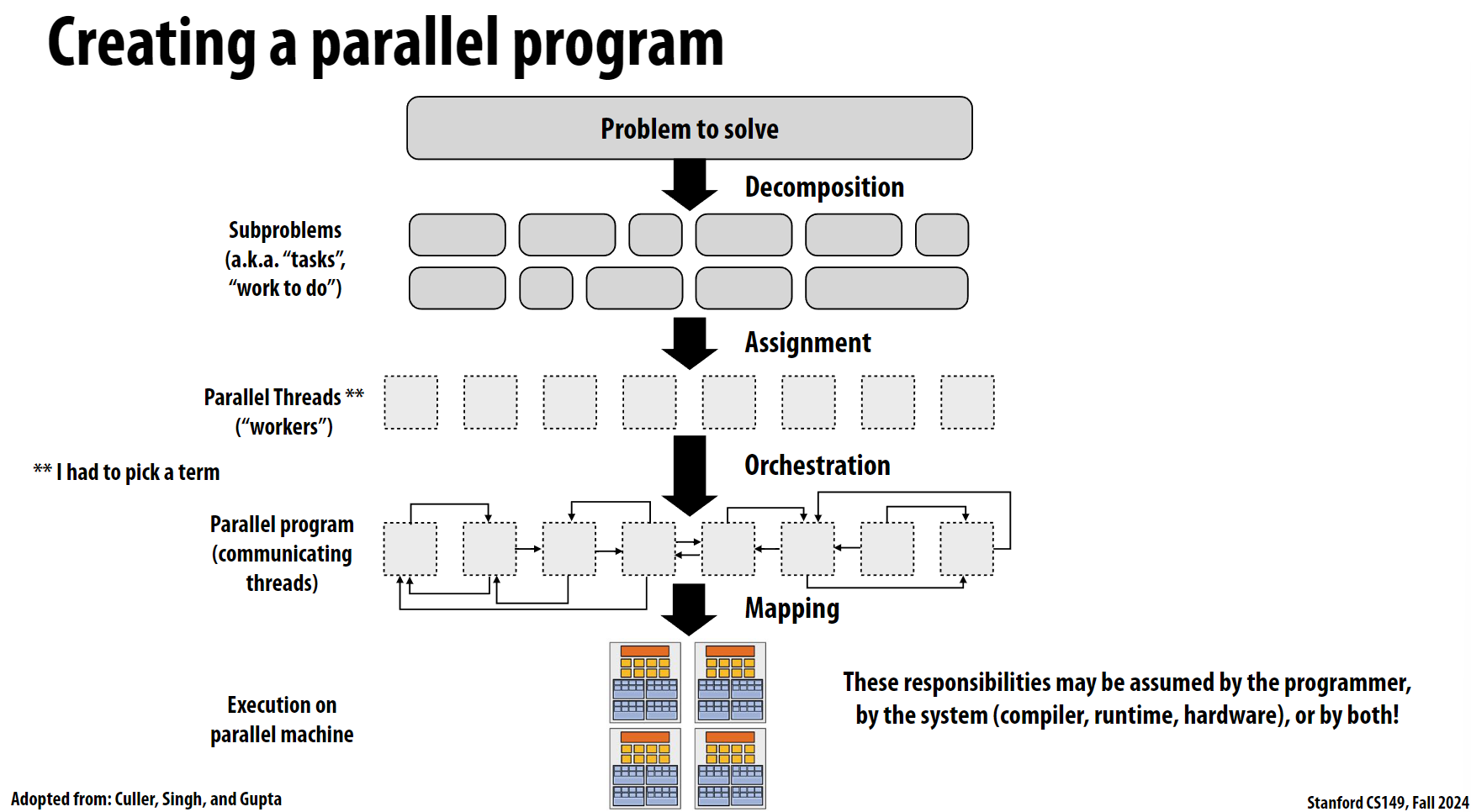
这张图展示了并行编程的整体思路, 基本上分为以下几个步骤:
问题分解(Decomposition)
- 将主要问题拆分成多个较小的子问题(Subproblems)
- 这些子问题也被称为”tasks”或”work to do”
- 分解的目标是找到可以并行处理的任务单元
任务分配(Assignment)
- 将分解后的子任务分配给并行线程(Parallel Threads)
- 这些并行线程被称为”workers”(工作者)
- 需要考虑负载均衡,确保每个线程的工作量相对均匀
任务编排(Orchestration)
- 安排线程之间的通信和协作方式
- 确定线程间的依赖关系
- 建立线程之间的数据流动路径
- 管理线程间的同步机制
映射(Mapping)
- 将并行程序映射到实际的硬件资源上
- 决定如何在并行计算机上分配和执行任务
- 考虑硬件架构的特点和限制
2 任务分配
2.1 静态分配
这里就不详细介绍了, 之前ispc那节课和Assignment 1都已经体会过了。
2.2 动态分配
回顾之前ispc中的task和worker, 每个worker在完成了当前的task后, 会从队列中取出一个新的task。
3 案例-1-PDE
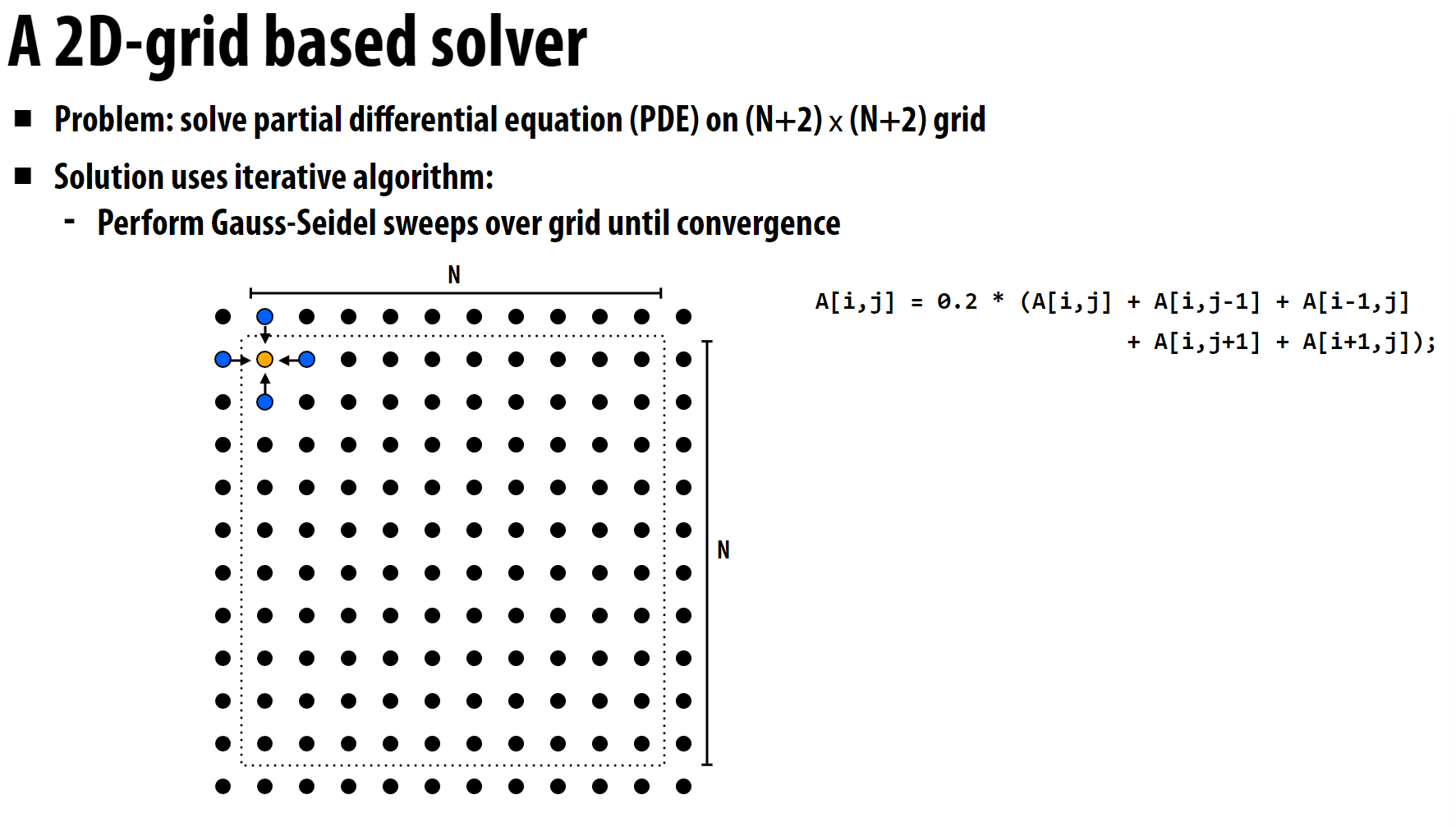
这里每个像素点都依赖周围像素点, 由于存在相互依赖, 因此很难进行任务分解。这里的任务分解采用了一些近似:

每一轮迭代中, 每个像素点都依赖周围像素点, 因此每个像素点都作为一个task, 可以指定:
- 奇数轮迭代只计算偶数行、奇数列的像素点
- 偶数轮迭代只计算奇数行、偶数列的像素点
结果像这样: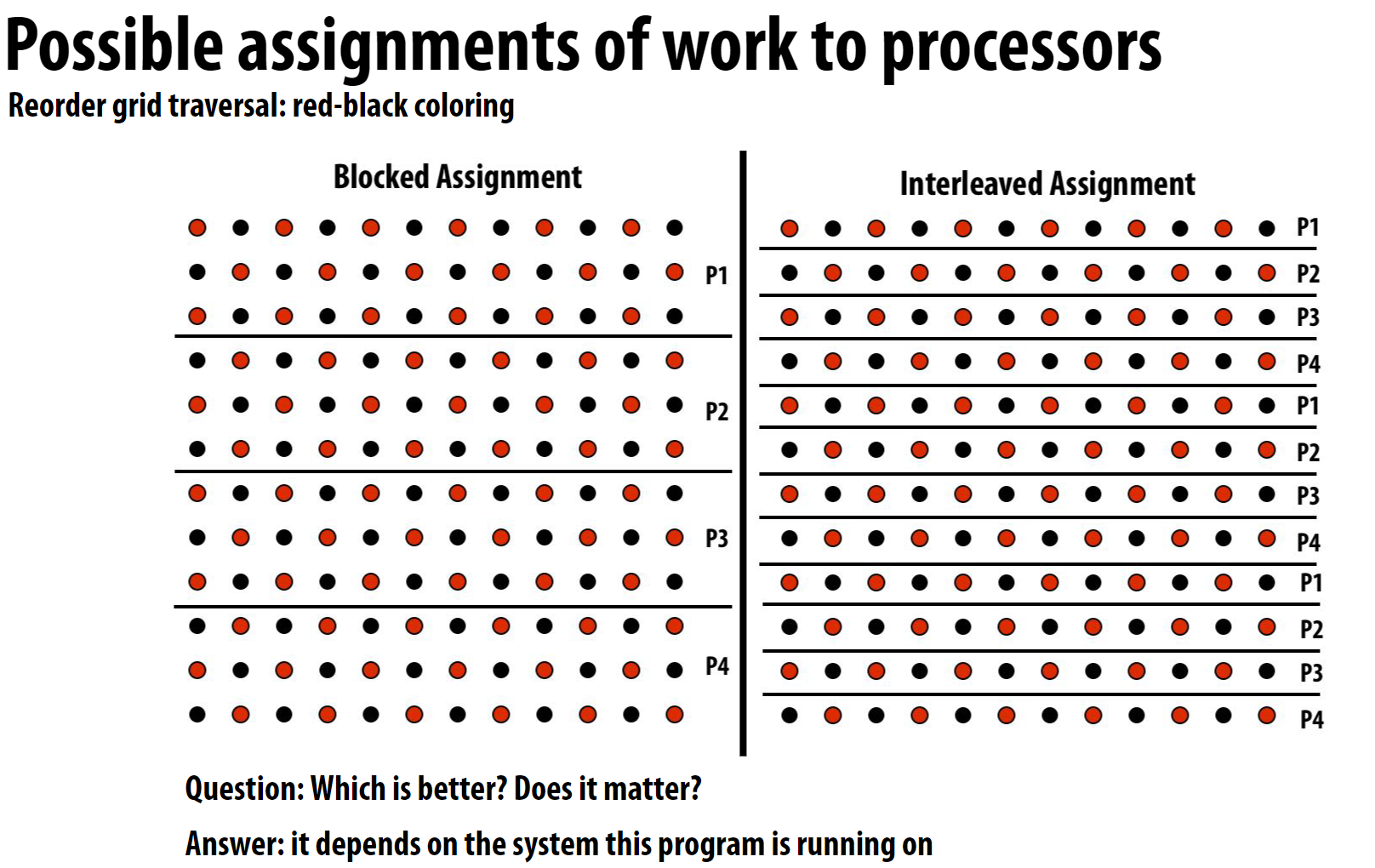
这样的近似解虽然不精确, 但是速度快, 而且可以并行处理,且满足常规情况下的精度要求。
3 SPMD的思想
SPMD是”Single Program Multiple Data”(单程序多数据)的缩写,这是并行计算中一种常见的编程范式。
基本概念
- 同一个程序在多个处理器上并行执行
- 每个处理器执行相同的代码
- 但是处理不同的数据集
工作方式
- 所有处理器运行相同的程序副本
- 每个处理器可以访问不同的数据
- 通过处理器的ID号来区分不同的任务
优势
- 编程模型简单直观
- 易于实现负载均衡
- 代码维护成本较低
实现示例:
1 | // MPI程序示例 |
SPMD是MPI(消息传递接口)等并行计算框架中最常用的编程模式之一。它使得并行程序的开发变得更加简单和标准化。
4 任务通信方式——地址空间共享
4.1 锁
如果采用动态的任务分配的话, 那么每个worker之间需要进行通信, 地址空间共享是其中一种通信方式。
但因为多个worker会同时访问共享的内存地址, 因此需要引入Lock等同步机制来避免竞争。
4.2 屏障
如果计算被分为不同阶段, 那么每个阶段结束时可能需要进行同步, 这种同步方式称为屏障(Barrier)。
5 小节
感觉这节课没讲啥干货, 就不总结了…