1 多核处理器进阶知识(续上一节课)
上一节课展示了CPU的ALU运算可能会被内存的延迟拖累, 因此实际上数据加载和ALU运算是同时进行的, CPU核心其实还包括加载存储单元: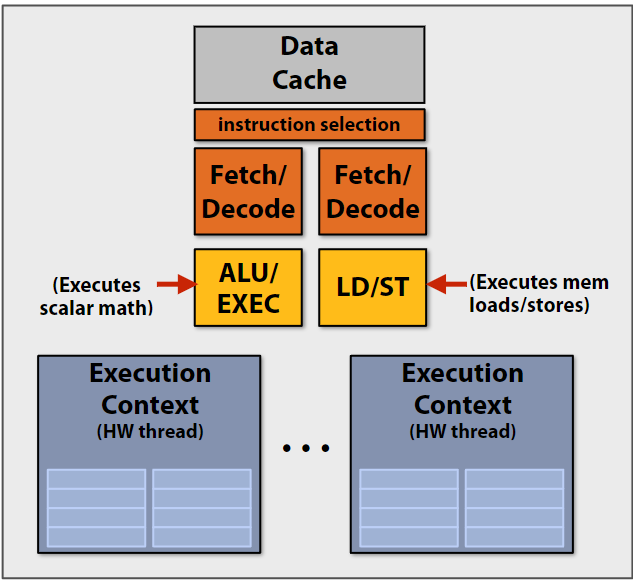
其运行流程如下图:
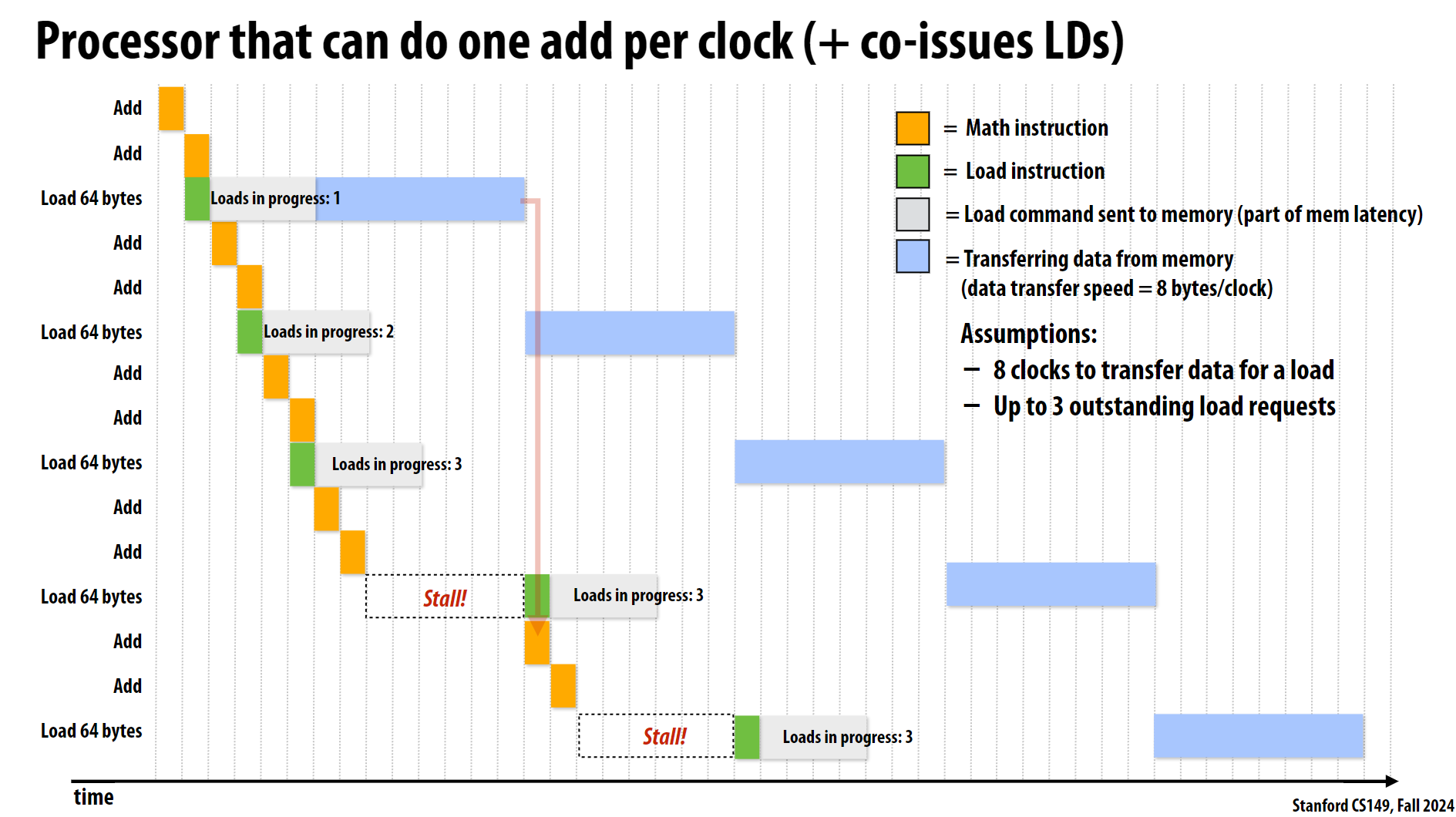
在这张图中,绿色方块表示的加载指令(Load instruction)代表的是CPU发起的加载请求。完整的加载过程是:
绿色方块(Load instruction):
- 这是CPU执行加载指令的阶段
- 表示CPU发出了一个加载请求
- 这个阶段很快,只占用一个时钟周期
灰色方块(Load command sent to memory):
- 表示加载请求已经发送到内存系统
- 这是内存延迟的一部分
蓝色方块(Transferring data from memory):
- 表示实际从内存中传输数据的过程
- 数据传输速度是8字节/时钟周期
- 需要8个时钟周期来完成64字节的传输
所以整个过程是:
1 | CPU发出加载请求(绿色)-> 请求传递到内存(灰色)-> 数据从内存传回CPU(蓝色) |
这就是为什么图中标注”Loads in progress”时会同时显示这三种颜色的方块,因为它们代表了完整的内存加载过程的不同阶段。当达到3个并发加载请求时,CPU就无法发起新的加载请求,导致出现”Stall”(停顿)状态。
另一方面, 图中显示了两次Stall情况,这是因为达到了最大并发加载请求数(3个), 这些停顿表明处理器必须等待之前的加载操作完成才能继续执行新的加载指令, 而且这里多次的内存加载操作是无法并行实现的, 每一个蓝条结束后, 下一个蓝条才能开始。但现代实际的CPU内存系统要复杂得多,而且确实支持并行数据传输。现代处理器采用以下技术来缓解这个问题:
多通道内存架构(Multi-Channel Memory):
- 提供多个并行的数据传输通道
- 每个通道都有独立的数据传输路径
- 可以同时处理多个内存请求
- 例如:双通道DDR4-3200可以达到51.2 GB/s的理论带宽
现在终于明白之前看到硬件评测节目中所说的
双通道和四通道内存是什么了。内存控制器优化(其实不算对通道传输的优化, 是调度的优化):
- 多个内存控制器并行工作
- 智能调度算法重排内存请求
- 合并相邻的内存请求
- 优化页面访问策略
新型内存技术:
- HBM(高带宽内存):提供更多并行传输通道,具体是将多个DRAM芯片垂直堆叠,每层都有独立的内存控制器,所有层可以并行工作
- GDDR(图形双倍数据率内存):更高的传输带宽,DDR内存的特殊变体,专为图形处理优化
- 3D堆叠内存:缩短传输距离,提高并行度
注:多层级缓存系统虽然也是内存系统的一部分,但它主要解决的是访问延迟问题,而不是内存传输的串行化问题。我们这里讨论的重点是如何实现多个内存传输请求的并行处理。
举例:
1 | AMD Ryzen 处理器: |
2 ISPC
2.1 课程介绍的代码说明
课程的第二部分是介绍ISPC, 根据官方的定义:
ispc 是 C 编程语言变体的编译器,具有单程序、多数据编程的扩展。在SPMD模型下,程序员编写的程序通常看起来是一个常规的串行程序,但执行模型实际上是多个程序实例在硬件上并行执行。
课程以sinx的计算为例, 展示了如何使用ISPC编写并行程序:

需要注意的是, PPT中的函数实际上无法运行(可能类似伪代码吧), 这里我进行了更改:
1 | // sinx_ispc.ispc |
主函数:
1 |
|
ispc函数用export标识, 调用它就创建了一个gang。在 ISPC 中,gang 是一个非常重要的概念。 每个 gang 包含多个程序实例(program instances),数量由 programCount 决定:
- 在现代 CPU 上,通常
programCount是:- SSE: 4 个实例
- AVX: 8 个实例
- AVX-512: 16 个实例
在我们的代码中:
1 | export void ispc_sinx( |
执行流程:
1 | Gang 执行示例 (假设使用 AVX 指令集,programCount=8): |
示意图如下: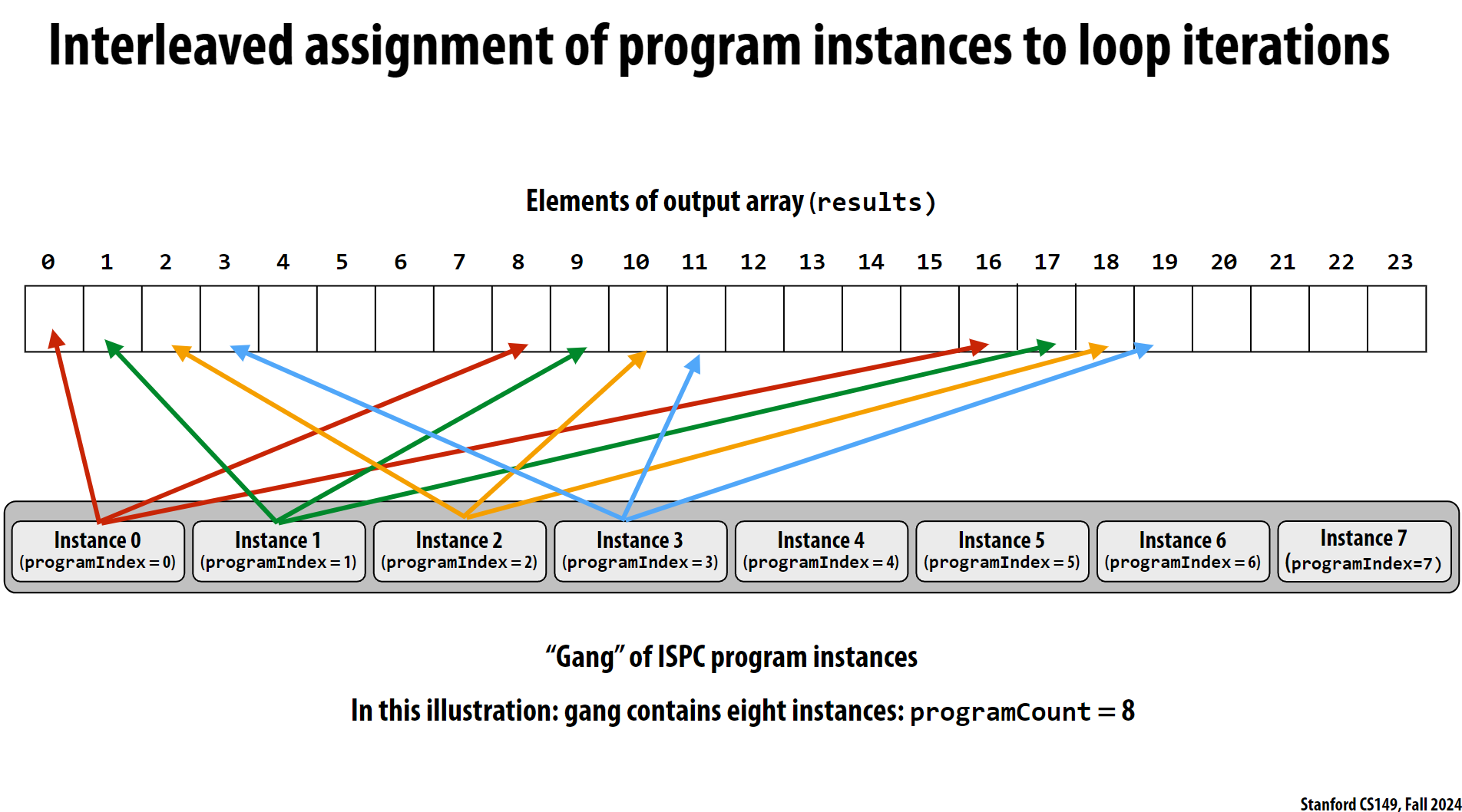
重要特点:
- 所有实例并行执行相同的代码
uniform变量在所有实例中共享同一个值- 非
uniform变量每个实例可以有不同的值 programIndex用于区分不同实例programCount是gang中实例的数量
2.2 ispc的实际使用
课程没有具体介绍ispc的实际使用, 只是展示了如何编写ispc代码, 以及ispc代码的执行流程。这里我进行补全:
- 安装
ispc- 使用
snap安装:1
sudo snap install ispc
- 官方下载: https://github.com/ispc/ispc
- 使用
- 编译
ispc代码- 使用
ispc编译器编译ispc代码:1
ispc sinx_ispc.ispc -o sinx_ispc.o -h sinx_ispc.h # 生成.o文件和.h文件
- 使用
- 编译主函数:
1
g++ -o sinx_ispc sinx_ispc.o main.cpp # 生成可执行文件
我将官方案例整理成了一个小demo项目, 其层次结构为:
1 | $ tree . |
main.cpp是主函数, sinx_ispc.ispc是ispc代码, Makefile是makefile文件。前二者参考之前的代码, makefile文件展示了如何编译和运行这个项目和ispc的使用:
1 | ispc: sinx_ispc.ispc |
编译和运行:
1 | $ make |
2.3 ISPC的实现原理
ISPC 的 gang 就是基于 SIMD 实现的,programCount 直接对应 SIMD 的通道数。
SIMD 对应关系:
1
2
3
4指令集 SIMD 寄存器宽度 programCount
SSE 128-bit 4 (4个32位float)
AVX 256-bit 8 (8个32位float)
AVX-512 512-bit 16 (16个32位float)实际执行示例:
1
float value = x[idx]; // 加载操作
会被编译成类似这样的 SIMD 指令(以 AVX 为例):
1
vmovups ymm0, [rax + idx] // 一次性加载8个float到YMM寄存器
ISPC 的优势:
- 自动向量化: 把你写的标量代码自动转换为 SIMD 指令
- 抽象硬件细节: 不需要直接编写 SIMD 汇编或内联函数
- 可移植性: 同样的代码可以针对不同的 SIMD 指令集编译
编译选项影响:
1
2
3
4# 指定目标架构
ispc --target=sse2 # programCount = 4
ispc --target=avx # programCount = 8
ispc --target=avx512 # programCount = 16
这就是为什么在代码中:
1 | for (uniform int i=0; i<N; i+=programCount) { |
每次循环实际上是在执行一个 SIMD 指令,同时处理 programCount 个数据。
2.4 ispc的进阶使用
2.4.1 使用ispc的foreach
之前的代码中, 我们使用programCount和programIndex来控制并行执行的实例数和索引, 实际上ispc还提供了一个更方便的变量foreach, 它可以直接遍历所有实例并自动处理programCount和programIndex:
1 | export void ispc_sinx( |
2.4.2 使用ispc的task
之前的并行都只是基于单核的SIMD并行, 实际上ispc还支持多核的并行, 通过task来实现:
1 | // main.cpp |
1 | // sinx_ispc.ispc |
这里的launch关键字用于启动多个任务, 每个任务执行ispc_sinx_single函数。numTasks是任务的数量, 每个任务执行N/numTasks个元素的计算。在task函数中, 有下面几个预设变量:
taskCount: 任务的数量taskIndex: 当前任务的索引
这里因为使用了
ISPC的任务系统(task system),还需要链接必要的运行时库。ISPC 的任务系统需要一些运行时支持函数(如 ISPCAlloc、ISPCLaunch、ISPCSync)。这里可以直接使用Assignment 1中提供的task.cpp文件
这里task可以类比一个线程, ispc会尽量将task均匀分配到所有CPU核心上, 并行执行。
这里的makefile也要进行修改, 添加task.cpp文件:
1 | CXXFLAGS=-O3 -Wall -fPIC -ffp-contract=off |