1 简单介绍多核CPU(续上一节课)
多核CPU就是将单个CPU复制很多份, 每一份有自己的ALU、上下文寄存器、乱序单元等等: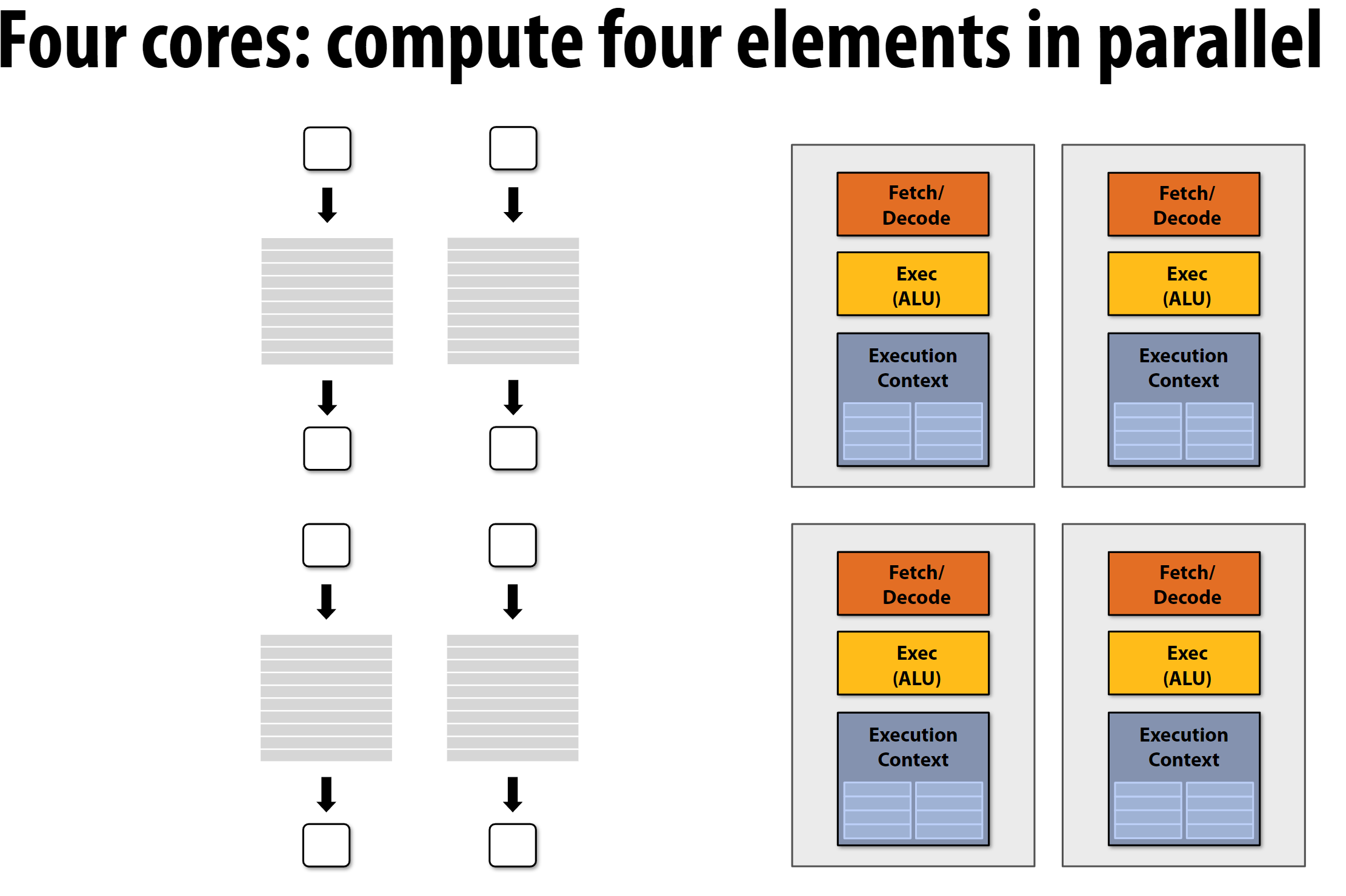
使用多核CPU进行并行计算时,简单的思路就是将不存在依赖关系的任务分配到不同的核上执行。
2 并行方案3——SIMD
SIMD是Single Instruction Multiple Data的缩写,即单指令多数据。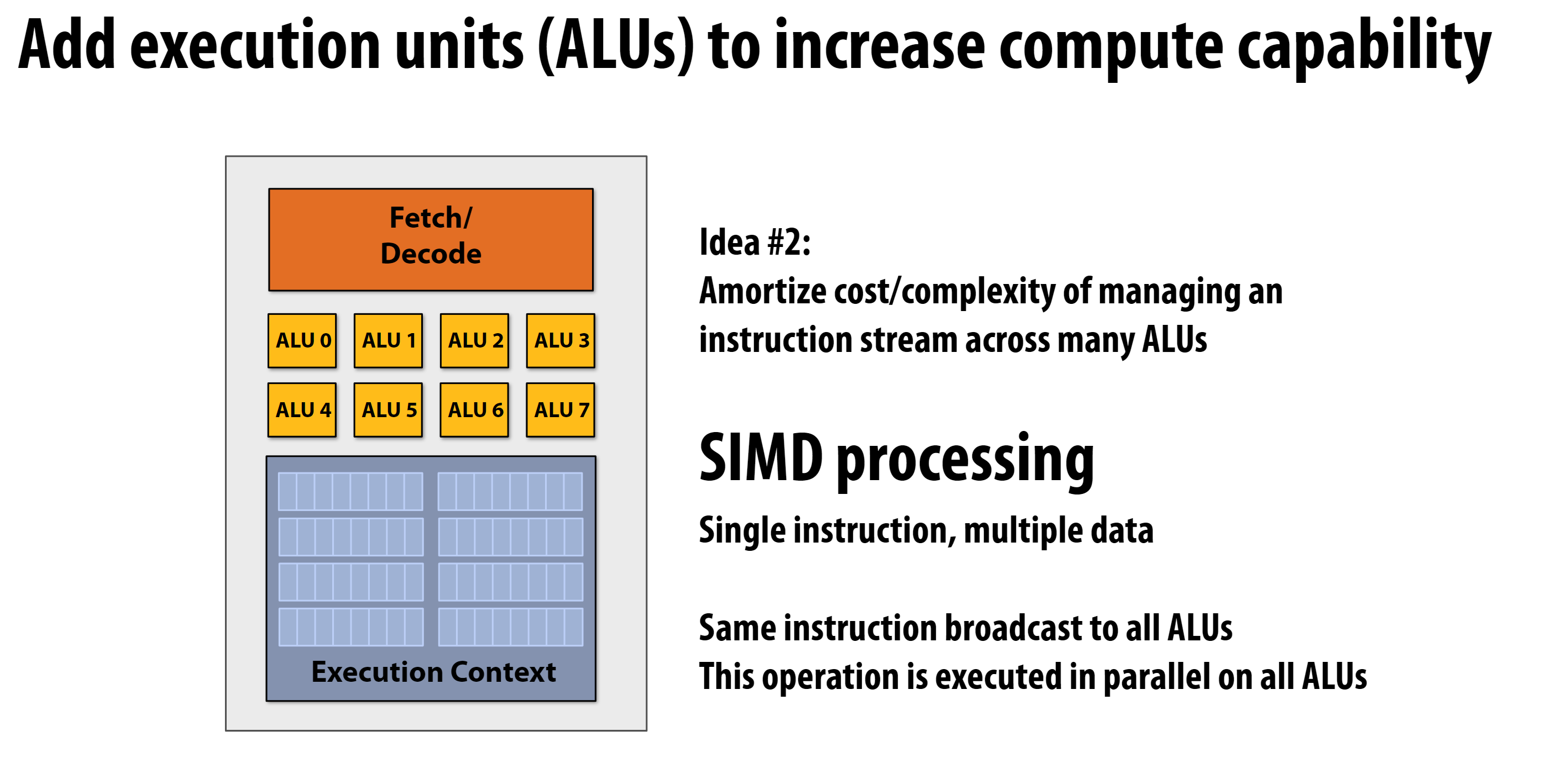
SIMD的工作原理
- 一条指令(Single Instruction)
- 多个ALU并行处理不同的数据(Multiple Data)
- 每个ALU执行相同的操作,但处理不同的数据
示例中的结构
- 8个ALU(ALU 0-7)
- 一个取指/解码单元(控制单元)
- 当执行SIMD指令时:
- 同一指令广播给所有ALU
- 每个ALU处理自己的数据部分
- 8个数据同时被处理
需要说明的是, 这多个ALU存在于同一个处理器中, 所以它们可以共享同一个取指/解码单元。
这里再对ALU和Fetch/Decode组件的关系进行补充:
指令获取和解码过程
Fetch:
- 一次获取一条SIMD指令
- 同时需要获取对应的多个数据操作数
- 通常需要较宽的数据总线支持
Decode:
- 解析SIMD指令类型
- 确定数据访问模式
- 准备数据分发给各个ALU
数据流动
1
2
3
4
5Fetch/Decode ──┬→ ALU 0 ← Data[0]
├→ ALU 1 ← Data[1]
├→ ALU 2 ← Data[2]
└→ ALU 3 ← Data[3]
...需要注意的是, 虽然Fetch/Decode是统一的控制单元, 但是实际数据获取可能需要多个周期才能完成, 这也是为什么SIMD处理器的设计需要考虑内存系统的优化。
3 实现SIMD的AVX2案例代码
SIMD这一思想对应的指令集就是我们常常在硬件评测类视频或文章中提到的AVXxxx系列指令集。AVX2是目前使用最广泛的SIMD指令集。AVX512支持的SIMD指令集的宽度更大, 但是目前还没有普及, 而且因为发热过大还在Intel最近几代CPU被移除了, 这里的案例代码也是基于AVX2的, 其支持的SIMD指令宽度为256位。
查看个人PC是否支持AVX2指令集的方法:
1 | cat /proc/cpuinfo | grep avx2 |
3.1 中常用的函数总结
3.1.1 浮点运算函数
| 函数名 | 说明 | 示例 |
|---|---|---|
| 单精度浮点运算 (float) | ||
_mm256_add_ps |
8个单精度浮点数相加 | a + b |
_mm256_sub_ps |
8个单精度浮点数相减 | a - b |
_mm256_mul_ps |
8个单精度浮点数相乘 | a * b |
_mm256_div_ps |
8个单精度浮点数相除 | a / b |
| 双精度浮点运算 (double) | ||
_mm256_add_pd |
4个双精度浮点数相加 | a + b |
_mm256_sub_pd |
4个双精度浮点数相减 | a - b |
_mm256_mul_pd |
4个双精度浮点数相乘 | a * b |
_mm256_div_pd |
4个双精度浮点数相除 | a / b |
| 数据加载存储 | ||
_mm256_load_ps |
从对齐内存加载8个float | load from memory |
_mm256_load_pd |
从对齐内存加载4个double | load from memory |
_mm256_store_ps |
存储8个float到对齐内存 | store to memory |
_mm256_store_pd |
存储4个double到对齐内存 | store to memory |
| 数据类型转换 | ||
_mm256_cvtps_pd |
float转double (低4个) | float -> double |
_mm256_cvtpd_ps |
double转float (4个) | double -> float |
| 比较操作 | ||
_mm256_cmp_ps |
8个float比较 | a < b, a == b 等 |
_mm256_cmp_pd |
4个double比较 | a < b, a == b 等 |
| 其他常用操作 | ||
_mm256_sqrt_ps |
8个float平方根 | sqrt(a) |
_mm256_sqrt_pd |
4个double平方根 | sqrt(a) |
_mm256_max_ps |
8个float最大值 | max(a,b) |
_mm256_min_ps |
8个float最小值 | min(a,b) |
注意事项:
- 函数名中的
ps表示 packed single (单精度浮点) - 函数名中的
pd表示 packed double (双精度浮点) 256表示使用 256 位寄存器- 单精度运算一次处理 8 个数 (256/32=8)
- 双精度运算一次处理 4 个数 (256/64=4)
3.1.2 整型运算函数
| 函数名 | 说明 | 示例 |
|---|---|---|
| 32位整数运算 (int) | ||
_mm256_add_epi32 |
8个32位整数相加 | a + b |
_mm256_sub_epi32 |
8个32位整数相减 | a - b |
_mm256_mul_epi32 |
4个32位整数相乘(低位) | a * b |
_mm256_mullo_epi32 |
8个32位整数相乘(截断) | a * b |
| 16位整数运算 (short) | ||
_mm256_add_epi16 |
16个16位整数相加 | a + b |
_mm256_sub_epi16 |
16个16位整数相减 | a - b |
_mm256_mullo_epi16 |
16个16位整数相乘 | a * b |
| 8位整数运算 (char) | ||
_mm256_add_epi8 |
32个8位整数相加 | a + b |
_mm256_sub_epi8 |
32个8位整数相减 | a - b |
| 数据加载存储 | ||
_mm256_load_si256 |
从对齐内存加载整数 | load from memory |
_mm256_store_si256 |
存储整数到对齐内存 | store to memory |
| 比较操作 | ||
_mm256_cmpgt_epi32 |
8个32位整数大于比较 | a > b |
_mm256_cmpeq_epi32 |
8个32位整数相等比较 | a == b |
| 位运算 | ||
_mm256_and_si256 |
按位与 | a & b |
_mm256_or_si256 |
按位或 | a | b |
_mm256_xor_si256 |
按位异或 | a ^ b |
| 移位操作 | ||
_mm256_slli_epi32 |
32位整数左移 | a << n |
_mm256_srli_epi32 |
32位整数逻辑右移 | a >> n |
_mm256_srai_epi32 |
32位整数算术右移 | a >> n |
函数名说明:
epi32表示 32 位有符号整数epi16表示 16 位有符号整数epi8表示 8 位有符号整数epu32/epu16/epu8表示无符号整数版本
一次处理的数量:
- 32位整数:8个 (256/32=8)
- 16位整数:16个 (256/16=16)
- 8位整���:32个 (256/8=32)
这些整数运算在图像处理、音频处理等需要大量整数运算的场景中特别有用。例如:
1 | // 8个32位整数同时相加的例子 |
这些函数都需要包含 <immintrin.h> 头文件才能使用。
3.2 OpenMP的并行化技术
我学习avx2的时候顺带学习了OpenMP的并行化技术, 这里也顺带总结一下。
这里阐释一下OpenMP, SIMD, AVX三者的关系和区别:
3.2.1 三种技术的定位
| 技术 | 层次 | 并行类型 | 特点 |
|---|---|---|---|
| OpenMP | 线程级 | 多线程并行 | 跨核心并行 |
| SIMD | 指令级 | 数据并行 | 单核内并行 |
| AVX | 指令级 | 数据并行 | SIMD的具体实现 |
3.2.2 使用说明
安装:
1 | sudo apt-get install libomp-dev |
OpenMP:
- 线程级并行化技术
- 使用多个 CPU 核心
- 主要通过
#pragma指令实现 - 适用场景:
1
2
3
4
for(int i = 0; i < 1000; i++) {
result[i] = compute(data[i]);
}
3.2.3 OpenMP关键指令说明
#pragma omp parallel
- 创建一个并行区域
- 会创建多个线程,默认为CPU核心数量
- 并行区域内的代码会被所有线程执行
- 适用场景:需要执行多个并行操作时
1
2
3
4
5
6
{
// 这里的代码会被所有线程执行
int thread_id = omp_get_thread_num(); // 获取线程ID
// ... 并行执行的代码 ...
}
#pragma omp parallel for
- 组合指令,专门用于并行化for循环
- 自动将循环迭代分配给多个线程
- 会自动处理循环的任务分配和同步
- 适用场景:单个循环的并行化
1
2
3
4
5
for(int i = 0; i < n; i++) {
// 循环的每次迭代会被自动分配给不同线程
result[i] = compute(data[i]);
}
两者的主要区别:
parallel: 创建一个通用的并行区域,区域内的代码被所有线程执行parallel for: 专门针对循环的并行化,自动进行任务分配,每个迭代只被一个线程执行
性能考虑:
parallel创建线程池的开销较大,适合包含多个并行操作的场景parallel for针对循环优化,对单个循环并行化更高效
3.2.4 AVX2和OpenMP组合使用
可以同时使用这些技术来获得最大性能:
1 |
|
3.3 案例代码
这里对官方PPT的sin函数进行了补充, 并添加了OpenMP的并行化比较:
1 |
|
编译执行:
1 | g++ -mavx2 -O3 -march=native avx.cpp -o avx |
| 编译选项 | 说明 | 具体作用 |
|---|---|---|
| -mavx2 | 启用 AVX2 指令集 | - 允许使用 AVX2 向量指令 - 支持 256 位向量运算 - 启用 mm256* 函数 |
| -O3 | 最高级别优化 | - 函数内联 - 循环优化 - 向量化 - 分支预测优化 - 更积极的指令调度 |
| -march=native | 针对本机优化 | - 自动检测 CPU 特性 - 使用 CPU 支持的所有指令集 - 生成最优化的机器码 |
结果:
1 | $ ./avx |
4. SIMD问题: 如何处理分支
当并行计算多个通道时, 可能有些通道的计算会由于不同的if判断条件导致不同的计算处理方式, 那么如何处理这种情况?

处理方式: 加上掩码滤除即可: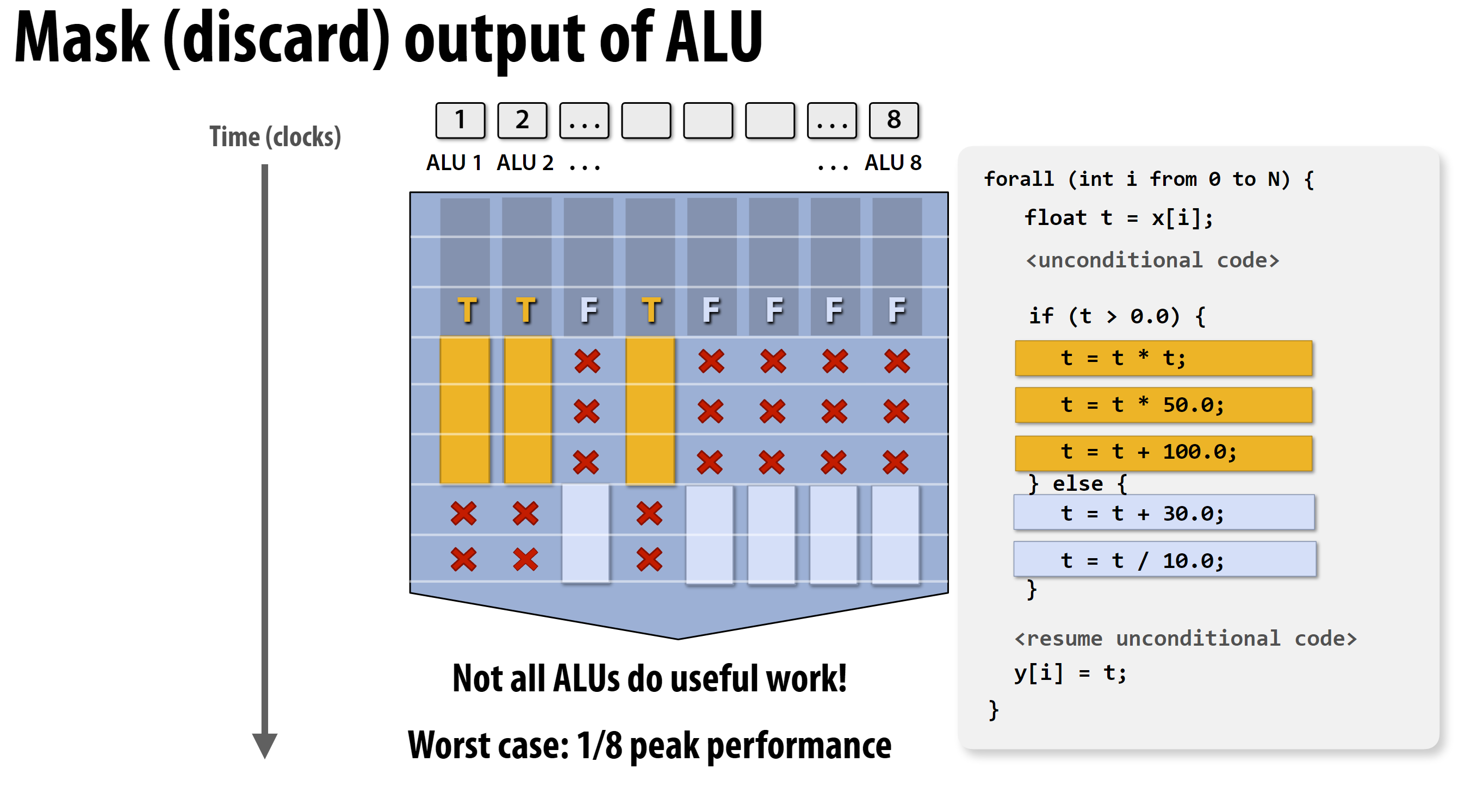
这里的处理会在第一个作业中使用到, 如果感兴趣可以看下第一个作业: https://github.com/ToniXWD/CS149-asst1
这里引入了一些新新概念:
指令流一致性(Instruction Stream Coherence)
定义:
- 同一指令序列应用于多个数据元素的程序特性
- 类似于”同步执行”的概念
重要性:
- 对SIMD处理至关重要
- 能够充分利用SIMD硬件资源
- 提高并行效率
多核心情况:
- 不要求指令流一致性
- 每个核心可以独立执行不同的指令流
- 更灵活的并行处理方式
发散执行(Divergent Execution)
定义:
- 指令流不一致的情况
- 不同数据需要执行不同的指令序列
影响:
- 降低SIMD效率
- 可能导致串行化
- 浪费硬件资源
实际应用示例
1
2
3
4
5
6
7
8
9
10
11
12// 一致性执行(好)
for(int i = 0; i < n; i++) {
result[i] = a[i] + b[i]; // 所有数据执行相同操作
}
// 发散执行(差)
for(int i = 0; i < n; i++) {
if(a[i] > 0)
result[i] = a[i] + b[i]; // 条件分支导致发散
else
result[i] = a[i] - b[i];
}
5 并行方案4——超线程技术的提出
实际CPU运行时, 由于缓存不命中, 会导致CPU的Stall, 因为CPU太快, 而需要等待慢速的L3 Cache加载数据。
这看起来是一个无解的问题,因为CPU的速度不存在能够与之匹敌的缓存。为了解决这个问题,Intel提出了超线程(Hyper-Threading)技术:
核心思路:
- 在一个物理核心中维护多个(通常是2个)线程的执行上下文
- 每个线程都有自己独立的寄存器组和程序计数器
- 共享核心的执行单元、缓存和其他硬件资源
工作原理:
- 当一个线程因缓存未命中而停顿时
- CPU可以快速切换到另一个线程继续执行
- 切换开销很小,因为硬件维护了完整的线程状态
优势:
- 提高CPU利用率
- 隐藏内存访问延迟
- 不需要完整的上下文切换(与操作系统级线程切换相比)
限制:
- 线程间共享物理核心的资源
- 如果两个线程都需要相同的执行资源,性能提升有限
- 不是所有工作负载都能从超线程中受益
6 小结: 目前学习的3中并行技术
6.1 超标量执行(Superscalar)
- 定义:在指令流中利用指令级并行性(ILP)
- 特点:
- 在同一核心内并行处理来自同一指令流的不同指令
- 并行性由硬件在执行过程中自动发现
- 实现:
- 动态指令调度
- 乱序执行
- 分支预测
6.2 SIMD(单指令多数据)
- 定义:多个ALU由同一指令控制(在核心内)
- 优势:
- 对数据并行工作负载高效
- 在多个ALU上分摊控制成本
- 实现方式:
- 显式SIMD:由编译器完成向量化
- 隐式SIMD:由硬件在运行时完成向量化
6.3 多核心(Multi-core)
- 定义:使用多个处理核心
- 提供:线程级并行性(Thread-level Parallelism)
- 特点:
- 每个核心可以同时执行完全不同的指令流
- 通过软件创建线程来向硬件暴露并行性
- 实现:
- 通过线程API创建和管理线程
- 每个核心独立执行不同的线程
6.4 超线程技术
- 定义:在加载数据时,单核执行另一个不需要IO的控制流
- 优势:
- 提高ALU利用率
- 实现方式:
- 在CPU单核内创建多个上下文寄存器
6.5 补充: GPU的结构
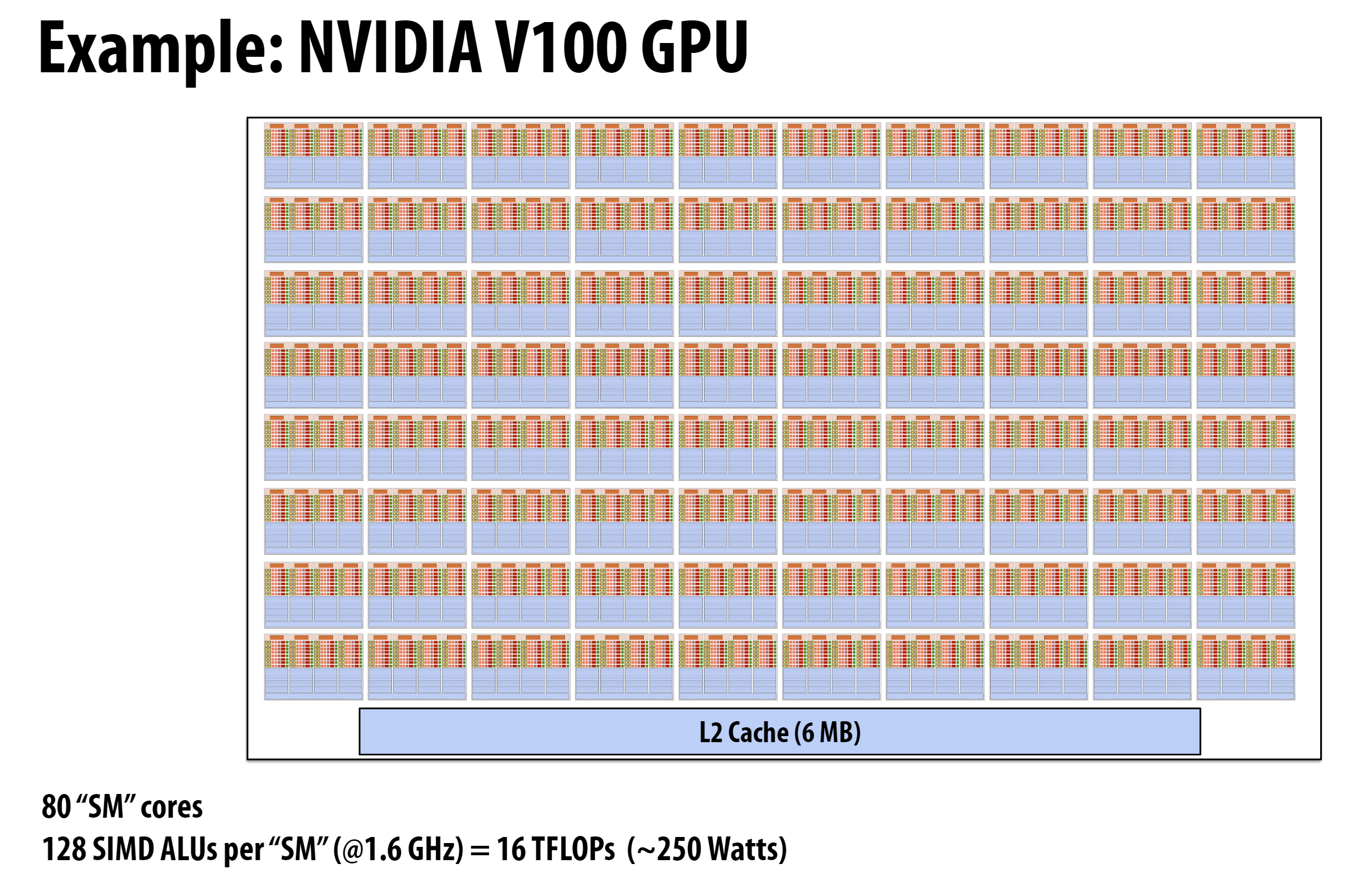
GPU的主要结构可以与CPU进行如下类比:
SM (Streaming Multiprocessor)
- 类比CPU的一个核心
- 是GPU的主要计算单元
- 4090有80个SM单元
CUDA Core
- 类比CPU中的SIMD ALU
- 每个SM有128个CUDA Core
- 专门用于并行执行相同指令的不同数据
- 与CPU的SIMD ALU类似,都是用于数据并行处理
层级关系
1
2
3
4
5
6
7
8
9GPU ─┬→ SM 0 (类比CPU核心) ─┬→ CUDA Core 0 (类比SIMD ALU)
│ ├→ CUDA Core 1
│ └→ ... (共128个)
│
├→ SM 1 ─┬→ CUDA Core 0
│ ├→ CUDA Core 1
│ └→ ...
│
└→ ... (共80个SM)主要区别
- CPU的SIMD ALU通常一次处理4-8个数据
- GPU的CUDA Core数量更多,可以同时处理更多数据
- GPU更适合大规模数据并行计算