CS的公开课鸽了好久, 打算开CS149这个新坑, 之前因为实习和秋招导致6.5840的lab4B一直没写完, 回来后发现很多思路忘了, 有时间再补吧。
课程官网: https://gfxcourses.stanford.edu/cs149/fall24
作业: https://github.com/stanford-cs149/asst1
我的实现: https://github.com/ToniXWD/CS149-asst1
这个作业主要是对既有的程序进行分析和优化,写的代码倒不是特别多
0 环境配置
我使用Wsl Ubuntu22.04作为开发环境, wsl的使用可以参考: WSL入门到入土
基于配置好的wsl, 还需要进行的配置包括
gcc,git吧啦吧啦, 这些应该不在话下了ispc的安装, 这个是intel的ispc编译器, 安装方式包括:- 从 https://ispc.github.io/downloads.html 处下载编译好的
ispc编译器, 然后解压, 将ispc路径添加到环境变量中。 - 使用
snap安装,sudo snap install ispc即可。
- 从 https://ispc.github.io/downloads.html 处下载编译好的
ppm图像查看工具, 不建议使用官方推荐的工具, 这里推荐使用feh:sudo apt install feh- 使用
feh查看ppm图像:feh <image_path>
1 多线程加速Mandelbrot set图像迭代绘制
1.1 实现多线程版本
开胃菜, 很简单, 不需要懂Mandelbrot set是什么, 只需要将操作分配到多个线程中即可:
1 | // |
这里的workerThreadStart最可能的实现是这样的:
1 | // |
1.2 && 1.3 加速效果分析
根据之前的初版代码测试, 实际上加速效果如下图, 当线程数为3时, 加速效果反而不如线程数为2时: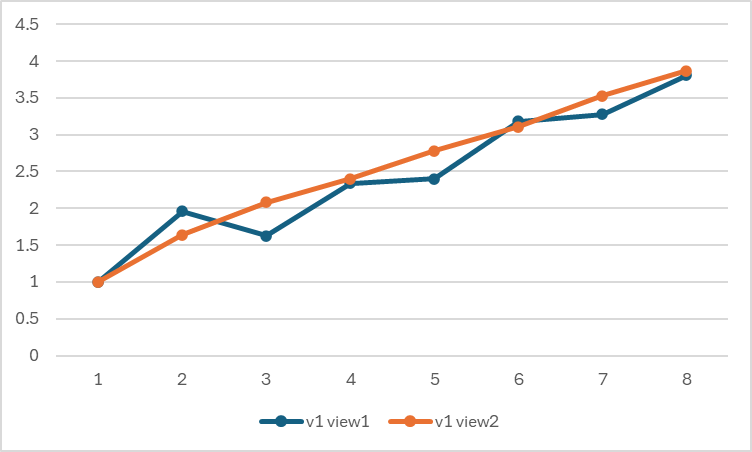
根据提示:
Hint: take a careful look at the three-thread datapoint.
以 t=3 为例,输出如下:
1 | $ ./mandelbrot -t 3 |
利用率不足的原因是不同线程负责的图像区域迭代的计算量不同,导致计算时间不同,出现了短板效应。3 线程中中间部分的计算时间明细大于上下两边,导致时间增加。
1.4 优化方案
因此, 解决方案就是, 每个线程计算的粒度进行细分, 从上到下按照一定间隔计算多块区域,每块区域不应该太小而导致无法利用局部性, 也不应该太大导致不同线程计算量差异过大, 这样每个线程的计算量被平均了,不会出现短板效应:
1 | // |
1.5 最大化利用率
就是将线程数量设置为cpu核心数, 这样多个线程可以实现真正的并行计算, 而减少非必要的上下文切换, 从而最大化利用率, 我自己的机器是因为我的 CPU 是 10 核 16 线程的 12600k, t=16 时,利用率为 10.51, 但当 t=32 时,利用率为 10.50,没有提升。
2 使用SIMD加速指数计算
这里的SIMD是官方提供的模拟器, 因为这样方便数据统计和调试, 因此开始这个实验前, 需要认真阅读CS149intrin.h每个函数的声明。
2.1 实现SIMD
直接给出代码吧, 有些细节要注意, 但没什么特别难的点需要解释, 每个步骤我批注了注释。
1 | void clampedExpVector(float* values, int* exponents, float* output, int N) { |
2.2 测试加速效果
| VECTOR_WIDTH | 利用率 |
|---|---|
| 2 | 85.3% |
| 4 | 81.3% |
| 8 | 79.0% |
| 16 | 77.7% |
利用率肯定是随着 VECTOR_WIDTH 增长而减少的,因为随着 VECTOR_WIDTH 增长,每次计算的元素数量增加,导致迭代次数最多的那一个元素相较于平均的差异越大,导致利用率越低。
2.3 数组求和的SIMD实现
有了之前的经验, 这里应该手到擒来吧
1 | // returns the sum of all elements in values |
3 使用ispc加速Mandelbrot set图像绘制
3.1 ispc入门
参考官方文档: https://ispc.github.io/example.html, 这里就不赘述了。
3.2 分析ispc加速效果
3.2.1 既有程序加速效果
我的结果:
1 | ./mandelbrot_ispc --tasks |
3.2.2 优化ispc代码
将task数量设置为本机最大硬件线程数,可以获得最佳利用率。
3.2.3 ispc和第一个任务重的线程任务的区别是什么?
task实际上会尽量均匀分配给硬件线程,所以当任务数量小于硬件线程数量时,随着任务数量增加,利用率会逐渐增加,当任务数量大于硬件线程数量时,反而会因为上下文切换导致利用率降低
4 牛顿迭代法实现sqrt
这个实验还挺激动的, 以前数值分析课学过牛顿迭代法, 但都是用matlab调包, 这次终于可以自己实现了, 而且还可以用ispc加速, 虽然这个实验的代码量也不多, 但确实让我对ispc有了更深的理解, 同时有一点科研的成就感, 哈哈。
4.1 实现ispc版本
结果:
1 | (base) toni@DESKTOP-59EELP2:prog4_sqrt$ ./sqrt |
4.2 ispc加速
这里的思路其实和前一个实验的思路是一样的, 就是尽量将SIMD一次计算的每个通道元素的迭代次数的差异最小化, 因此直接分析官方提供的这张图就够了: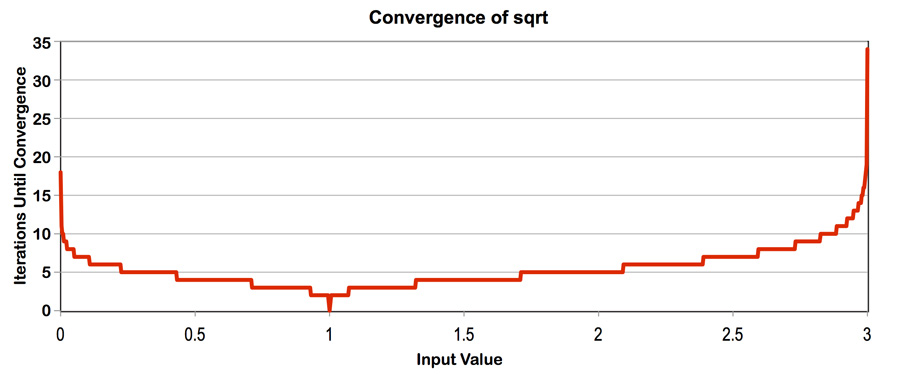
如果要加速, 就让元素尽量迭代次数相近, 这里我选择初始化在0.5-2.5之间:
1 | values[i] = .5f + 2.0f * static_cast<float>(rand()) / RAND_MAX; // Q2 |
4.3 ispc减速
思路和sqrt的加速是一样的, 就是尽量让每个通道元素的迭代次数相差更大, 这里我如下实现最大化差异:
1 | if (i % 8 == 0) { |
4.4 (附加题)使用avx2自己实现sqrt
这应该是最难的一个实验了, 需要对avx2的指令集有一定的了解, 这里我就不赘述了, 直接看代码吧, 每一行基本上都有注释:
1 |
|
x: [sign][exponent][mantissa] (原始数)
-0.0f: 1000...000 (全 0,仅符号位为 1)
~(-0.0f): 0111...111 (全 1,仅符号位为 0)
~(-0.0f) & x: 0[exponent][mantissa] (保持数值位不变,符号位强制为 0)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
这样就巧妙地将任何负数转换为对应的正数,而正数保持不变,从而实现了绝对值的计算。
*/
// 当任意一个元素的误差大于阈值时继续迭代
while (_mm256_movemask_ps(_mm256_cmp_ps(pred, threshold, _CMP_GT_OQ)) != 0) {
// _mm256_movemask_ps 是 AVX 指令集中的一个函数,用于从 256 位浮点向量中提取每个元素的符号位,并将这些符号位组合成一个 8 位的整数。
// 牛顿迭代公式:guess = (3 * guess - x * guess³) * 0.5
guess = _mm256_mul_ps(
_mm256_set1_ps(0.5f),
_mm256_sub_ps(
_mm256_mul_ps(_mm256_set1_ps(3.0f), guess),
_mm256_mul_ps(x_vec, _mm256_mul_ps(guess, _mm256_mul_ps(guess, guess)))
)
);
// 重新计算误差
pred = _mm256_sub_ps(
_mm256_mul_ps(_mm256_mul_ps(guess, guess), x_vec),
_mm256_set1_ps(1.0f)
);
pred = _mm256_andnot_ps(_mm256_set1_ps(-0.0f), pred);
}
// 计算最终结果 sqrt(x) = x * guess,并存储到输出数组
_mm256_storeu_ps(&output[i], _mm256_mul_ps(x_vec, guess));
}
// 使用标准算法处理剩余的元素(不足 8 个的部分)
for (int i = aligned_n; i < N; i++) {
float x = values[i];
float guess = initialGuess;
float error = fabs(guess * guess * x - 1.f);
while (error > kThreshold) {
guess = (3.f * guess - x * guess * guess * guess) * 0.5f;
error = fabs(guess * guess * x - 1.f);
}
output[i] = x * guess;
}
}
// 使用 AVX 指令集实现平方根计算(牛顿迭代法)
// 使用掩码,当满足阈值时不继续迭代 (这个案例其实没有必要)
// N: 数组长度
// initialGuess: 迭代初始值
// values: 输入数组,存储需要计算平方根的数
// output: 输出数组,存储计算结果
// 方程:1 / guess^2 = x
// !!!: x 不是迭代变量,guess 才是,且这里的 x 是数组的元素
// !!!: sqrt(x) = 1 / guess = x * guess
void sqrt_avx_mask(int N, float initialGuess, float *values, float *output) {
// 输入参数有效性检查
if (!values || !output || N <= 0) return;
// 设置收敛阈值
static const float kThreshold = 0.00001f;
// 计算能被 8 整除的最大长度(AVX2 可以同时处理 8 个 float)
int aligned_n = (N / 8) * 8;
// 使用 AVX 指令并行处理每 8 个元素
for (int i = 0; i < aligned_n; i += 8) {
// 将阈值广播到 256 位向量中(8 个 float)
__m256 threshold = _mm256_set1_ps(kThreshold);
// 从内存加载 8 个连续的 float 到向量寄存器
__m256 x_vec = _mm256_loadu_ps(&values[i]);
// 将初始猜测值广播到向量寄存器
__m256 guess = _mm256_set1_ps(initialGuess);
// 计算初始误差:|guess² * x - 1|
__m256 pred = _mm256_sub_ps(
_mm256_mul_ps(_mm256_mul_ps(guess, guess), x_vec),
_mm256_set1_ps(1.0f)
);
// 计算误差的绝对值
pred = _mm256_andnot_ps(_mm256_set1_ps(-0.0f), pred);
/*
1. 在浮点数的二进制表示中,最高位(符号位)为:
- 0:表示正数
- 1:表示负数
2. `-0.0f` 的二进制表示是 `1000 0000 0000 0000 0000 0000 0000 0000`
- 即只有符号位为 1,指数和尾数位都是 0
3. `_mm256_andnot_ps(a, b)` 的操作相当于 `~a & b`,即:
- 先对第一个操作数取位反(NOT)
- 然后与第二个操作数进行位与(AND)
4. 所以 `_mm256_andnot_ps(_mm256_set1_ps(-0.0f), x)` 的过程是:
x: [sign][exponent][mantissa] (原始数)
-0.0f: 1000...000 (全 0,仅符号位为 1)
~(-0.0f): 0111...111 (全 1,仅符号位为 0)
~(-0.0f) & x: 0[exponent][mantissa] (保持数值位不变,符号位强制为 0)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
这样就巧妙地将任何负数转换为对应的正数,而正数保持不变,从而实现了绝对值的计算。
*/
// 初始化掩码为全 1
__m256 mask = _mm256_cmp_ps(pred, threshold, _CMP_GT_OQ);
/*
常用的比较操作符(imm8 的值):
_CMP_EQ_OQ:相等
_CMP_LT_OQ:小于
_CMP_LE_OQ:小于或等于
_CMP_GT_OQ:大于
_CMP_GE_OQ:大于或等于
_CMP_NEQ_OQ:不等于
*/
// 当任意一个元素的误差大于阈值时继续迭代
while (_mm256_movemask_ps(mask) != 0) {
// _mm256_movemask_ps 是 AVX 指令集中的一个函数,用于从 256 位浮点向量中提取每个元素的符号位,并将这些符号位组合成一个 8 位的整数。
// 牛顿迭代公式:guess = (3 * guess - x * guess³) * 0.5
__m256 new_guess = _mm256_mul_ps(
_mm256_set1_ps(0.5f),
_mm256_sub_ps(
_mm256_mul_ps(_mm256_set1_ps(3.0f), guess),
_mm256_mul_ps(x_vec, _mm256_mul_ps(guess, _mm256_mul_ps(guess, guess)))
)
);
// 仅更新掩码为 1 的元素
guess = _mm256_blendv_ps(guess, new_guess, mask);
/*
_mm256_blendv_ps 用于根据掩码在两个 256 位浮点向量之间进行条件选择。它允许在两个向量中选择性地从一个向量复制元素到结果向量中,具体选择由掩码决定。
参数:
a:第一个 256 位浮点向量。
b:第二个 256 位浮点向量。
mask:一个 256 位浮点向量,用于控制选择。
返回值:
返回一个新的 256 位浮点向量。对于每个元素,如果 mask 中对应位置的符号位为 1,则从 b 中选择该元素;否则,从 a 中选择该元素。
*/
// 重新计算误差
pred = _mm256_sub_ps(
_mm256_mul_ps(_mm256_mul_ps(guess, guess), x_vec),
_mm256_set1_ps(1.0f)
);
pred = _mm256_andnot_ps(_mm256_set1_ps(-0.0f), pred);
// 更新掩码
mask = _mm256_cmp_ps(pred, threshold, _CMP_GT_OQ);
}
// 计算最终结果 sqrt(x) = x * guess,并存储到输出数组
_mm256_storeu_ps(&output[i], _mm256_mul_ps(x_vec, guess));
}
// 使用标准算法处理剩余的元素(不足 8 个的部分)
for (int i = aligned_n; i < N; i++) {
float x = values[i];
float guess = initialGuess;
float error = fabs(guess * guess * x - 1.f);
while (error > kThreshold) {
guess = (3.f * guess - x * guess * guess * guess) * 0.5f;
error = fabs(guess * guess * x - 1.f);
}
output[i] = x * guess;
}
}
5 BLAS中saxpy实现
这一部分都是对代码进行分析, 没有自己需要写代码的地方
5.1 分析saxpy为什么使用task`加速不明显
因为给定的数组太大了, 这是主要瓶颈是内存带宽, 而不是计算资源, 所以使用task加速不明显。
5.2 分析对内存访问次数的计算
读取和写入result需要 2 次内存访问,而读取X和Y各需要 1 次内存访问,所以总内存访问次数为 4N。
5.3 (附加题)优化方案
尴尬, 这道题没做出来…
6 k-means优化
这道题的数据文件没有开源, 所以没法做…