1 简化的处理器模型分析
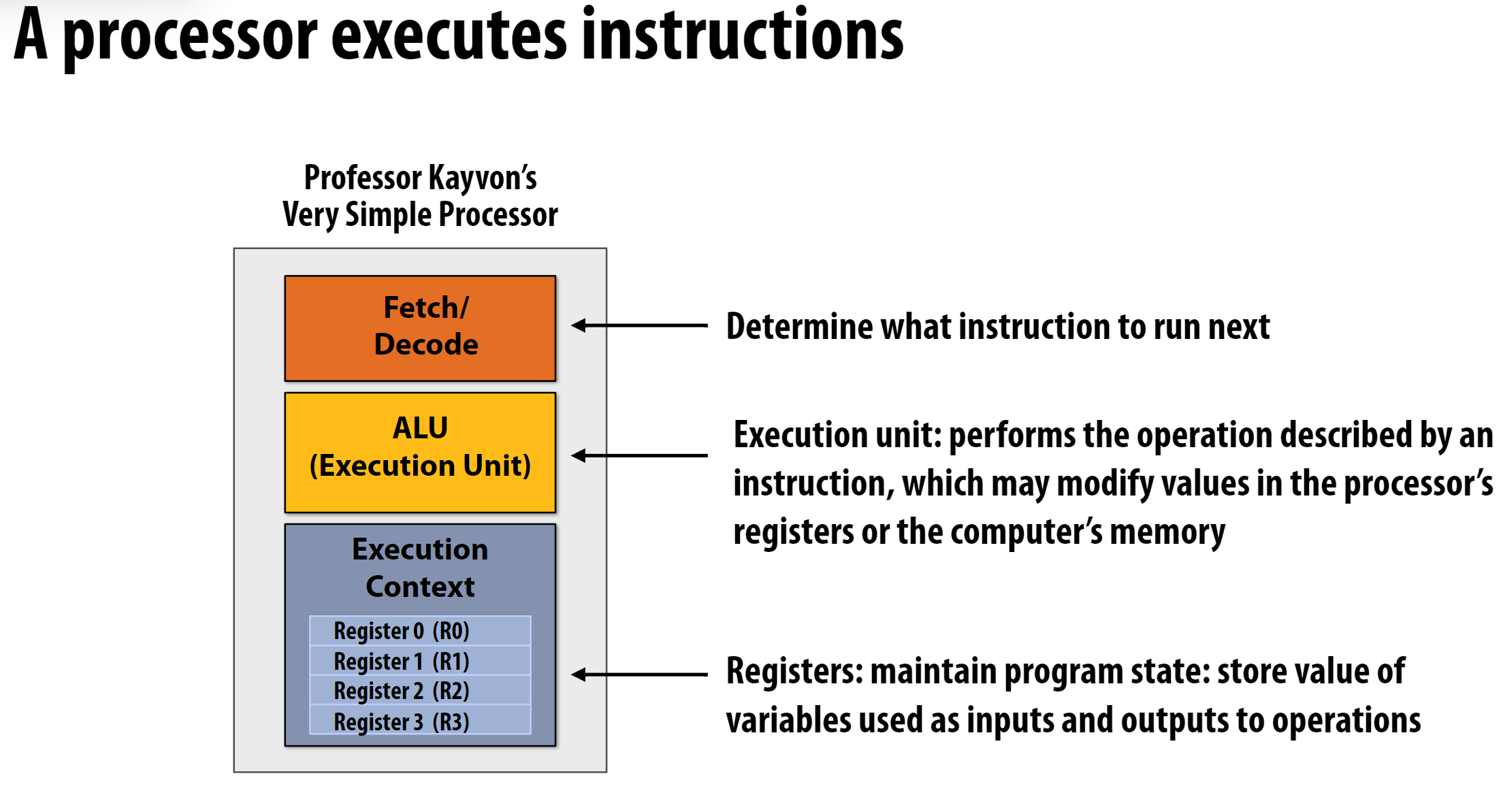
这张图片展示了一个简单处理器的基本结构,处理器包含三个主要部分:
取指/解码(Fetch/Decode)
- 位于顶部的橙色方框
- 功能是确定下一条要执行的指令
ALU(算术逻辑单元)/执行单元
- 位于中间的黄色方框
- 负责执行指令描述的操作
- 可以修改处理器寄存器中的值或计算机内存
执行上下文(Execution Context)
- 位于底部的灰色方框
- 包含4个寄存器(R0到R3)
- 寄存器用于维护程序状态
- 存储用作操作输入和输出的变量值
结合处理器的构造, CPU的运算流程如下:
取指阶段 (Fetch)
- CPU从内存中读取下一条要执行的指令
- 程序计数器(PC)指向当前要执行的指令地址
- 指令被加载到CPU的指令寄存器中
解码阶段 (Decode)
- CPU解析指令的内容,确定:
- 需要执行什么操作
- 需要使用哪些寄存器
- 是否需要访问内存
- CPU解析指令的内容,确定:
执行阶段 (Execute)
- ALU(算术逻辑单元)执行指令指定的操作
- 可能的操作包括:
- 算术运算(加、减、乘、除等)
- 逻辑运算(与、或、非等)
- 数据传输
- 控制转移
数据存储/更新阶段
- 执行结果被存储到指定的位置:
- 可能是寄存器(R0-R3)
- 可能是内存
- 更新程序计数器,指向下一条指令
- 执行结果被存储到指定的位置:
这就是所谓的”指令周期”(Instruction Cycle),CPU会不断重复这个过程来执行程序。这是一个简化的模型,现代CPU实际上更复杂,包含流水线、分支预测、缓存等优化机制。
上面的处理器很原始, 如果想要实现并行加速的话, 有什么办法呢?
2 一个并行加速的例子
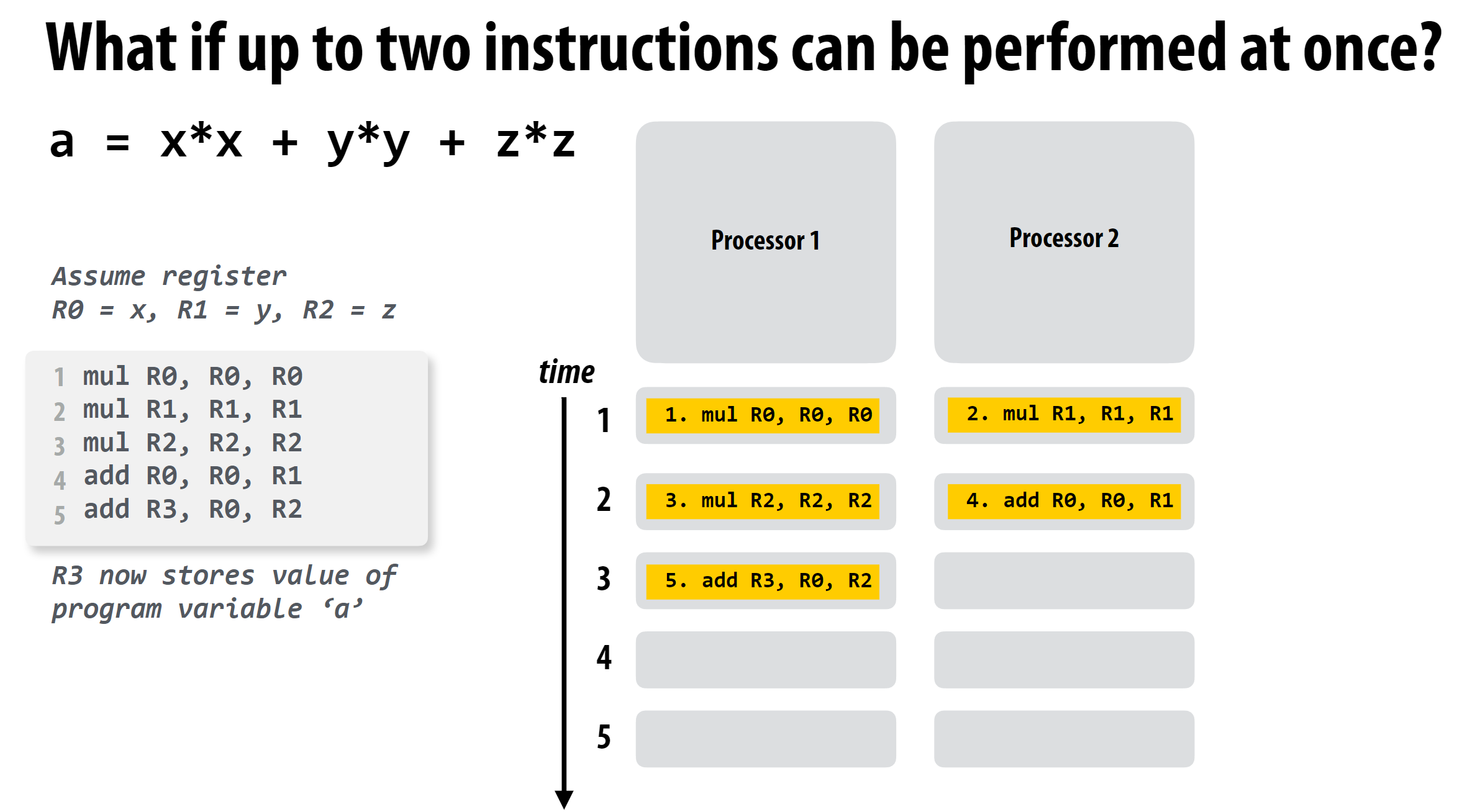
这个例子展示的核心思路就是将前后没有依赖关系的指令分配到不同的执行上下文中执行, 从而实现并行加速。
这里还引入了ILP的概念, 即Instruction Level Parallelism, ILP表示在同一时刻可以并行执行的指令数量。上述例子的ILP如下: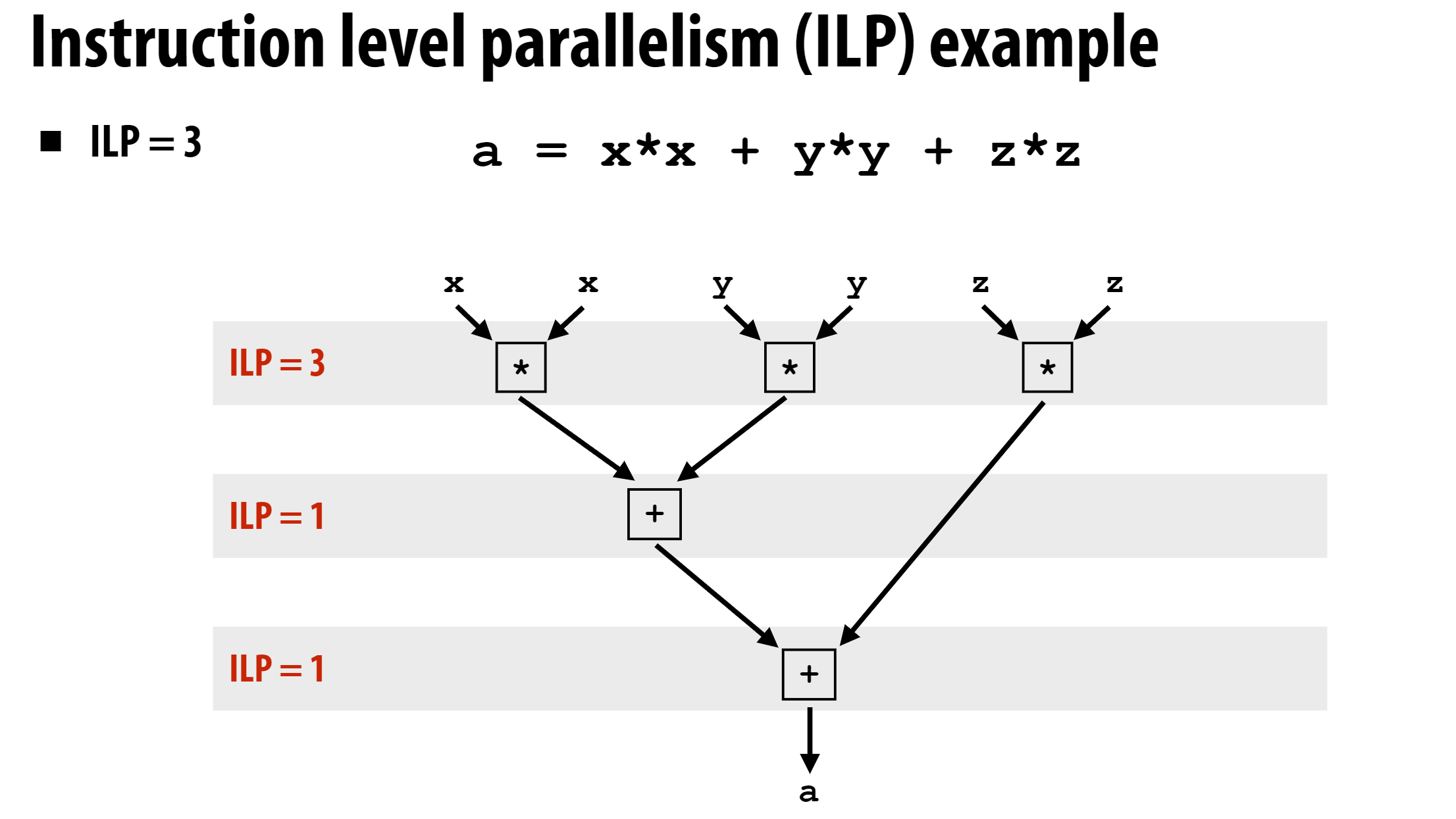
3 并行方案1-超标量处理器
基于之前并行加速的例子的原理, 可以设计一种超标量处理器Superscalar execution, 其核心思想是:
- 能够自动发现指令序列中的独立指令
- 可以在多个执行单元上并行执行这些指令
- 在保证程序正确性的前提下实现并行
下面是这类处理器的简易结构图: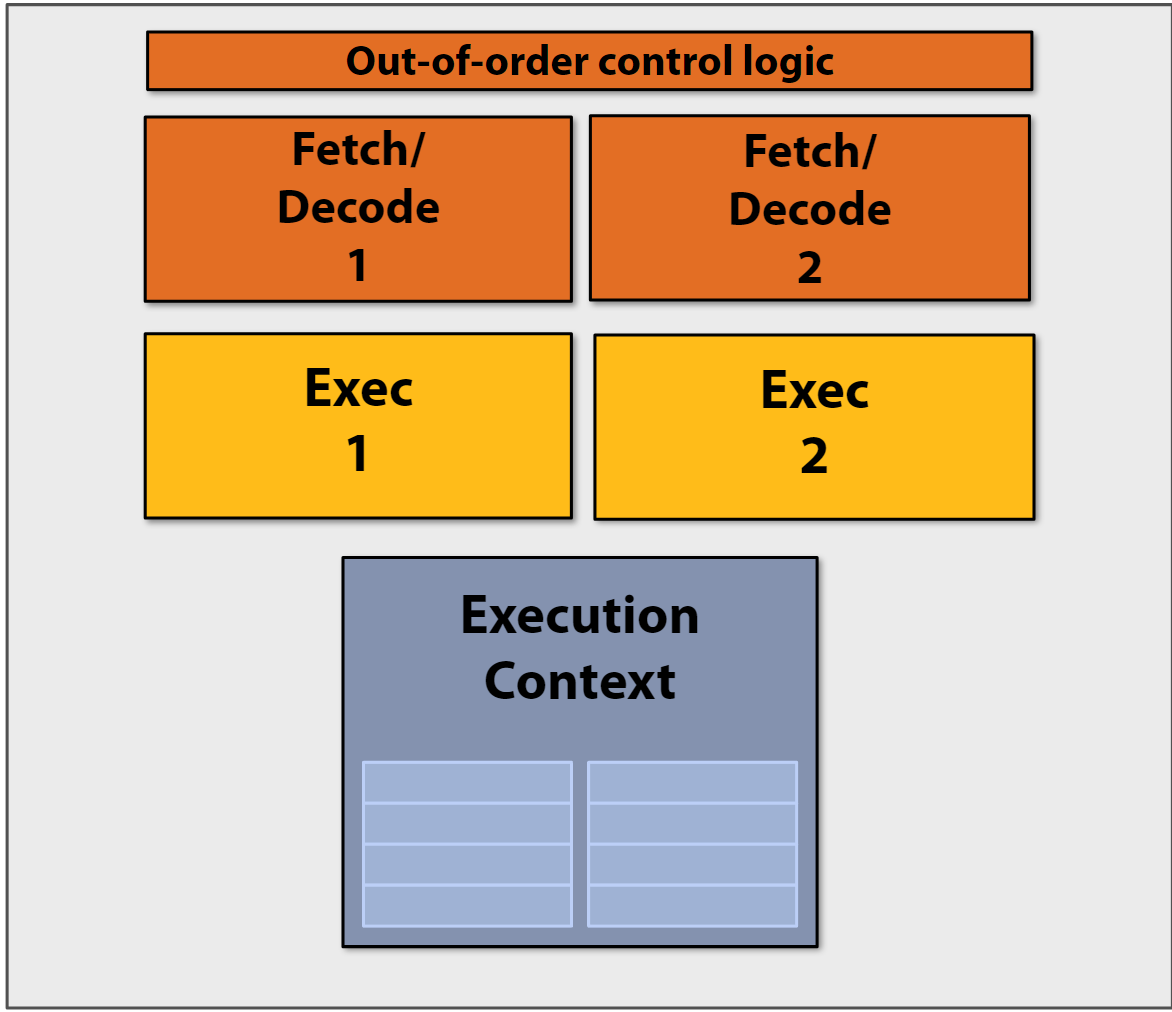
这里的Out-of-order control logic是现代处理器中的一个关键组件,负责管理指令的乱序执行。功能是分析指令间的依赖关系、识别可以并行执行的指令并动态调度指令的执行顺序。
4 并行方案2-多核处理器
这个方案应该没学过并行计算的同学都有所耳闻,就不过多介绍了。
5 其他知识点
5.1 处理器停顿
什么是处理器停顿
- 当处理器无法执行指令流中的下一条指令时发生
- 原因是后续指令依赖于尚未完成的前序指令的结果
- 这种情况会导致处理器暂时无法继续执行
内存访问是主要停顿源
- 示例代码展示了典型的内存依赖:
1
2
3ld r0 mem[r2] # 从内存加载数据到r0
ld r1 mem[r3] # 从内存加载数据到r1
add r0, r0, r1 # 需要等待前两条加载指令完成 - add指令必须等待两个内存加载操作完成才能执行
- 示例代码展示了典型的内存依赖:
内存访问延迟问题
- 内存访问时间约为数百个时钟周期
- “访问时间”是衡量延迟的指标
- 这种长延迟会导致严重的性能损失
影响
- 降低处理器效率
- 影响指令级并行的效果
- 是处理器性能优化需要重点考虑的问题
这个问题也是为什么现代处理器设计中会采用多级缓存、预取等技术来减少内存访问造成的停顿。
5.2 缓存
对于缓存的基本概念,学过CSAPP的同学应该对缓存有所了解, 这里就不多介绍了。
这里主要介绍以下什么是缓存行(Cache Line):
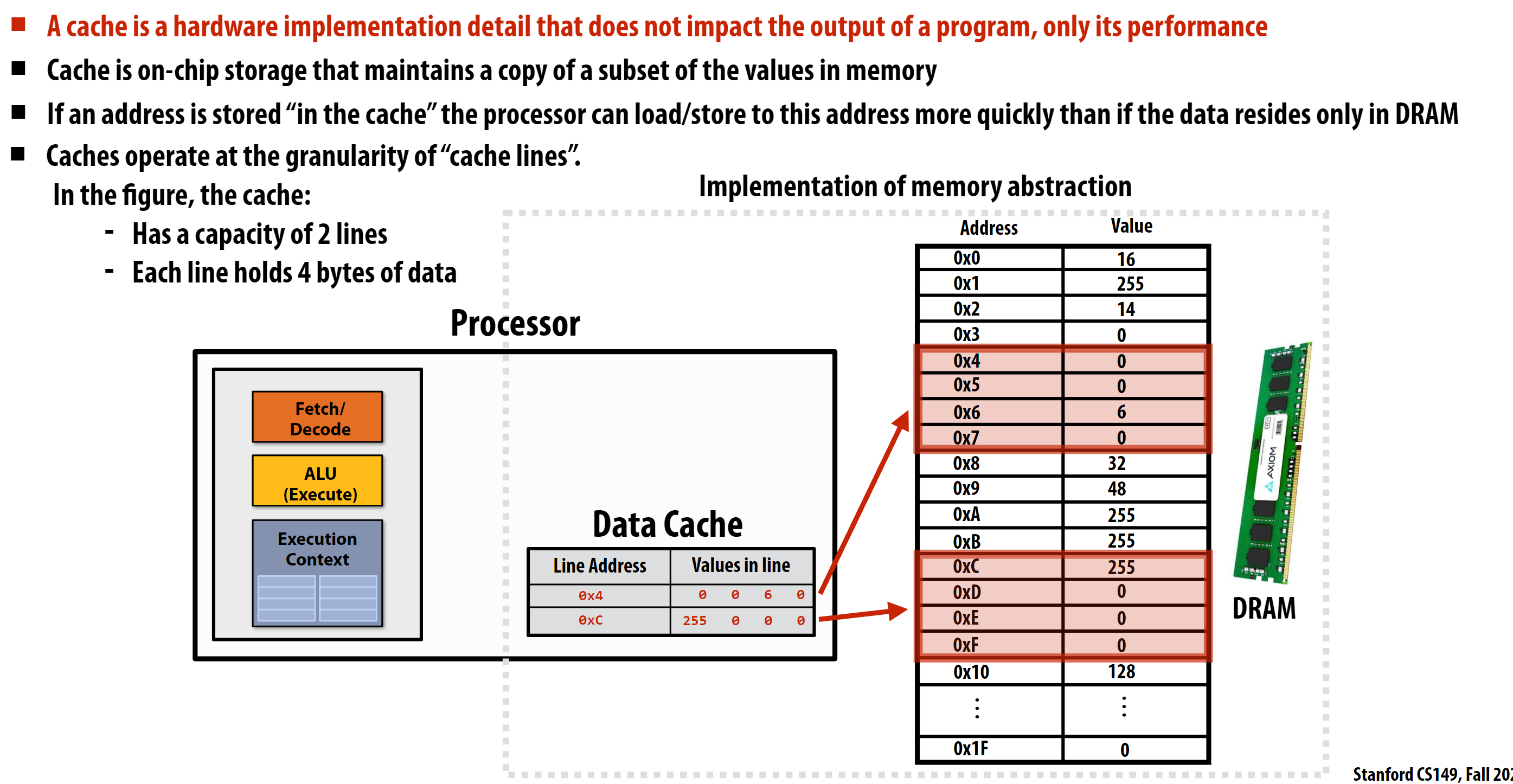
缓存行(Cache Line)是缓存系统的基本操作单位,其主要包含以下几个要点:
基本概念
- 是缓存中数据传输的最小单位
- 由连续的内存地址组成
- 通常大小是2的幂次字节(如32字节、64字节、128字节等)
组成部分
- 标记(Tag):用于标识数据来自哪个内存块
- 数据(Data):实际存储的内存数据
- 状态位:如有效位(Valid bit)、脏位(Dirty bit)等
示例中的缓存行特点
1
2
3Line Address | Values in line
0x4 | 0 0 6 0
0xC | 255 0 0 0- 每行存储4字节数据
- 按照内存地址对齐
- 一次加载/存储整个缓存行