本文不会将原本rCore文档的内容重复太多, 主要是补充学习过程中遇到的知识点, 因此还需结合原文使用, 原文在后面的链接中
这一章引入了页表和虚拟内存。回顾之前构建的OS, 其内核和应用是共用一份地址空间的。这也就意味着, 某个应用程序可以任意访问其他应用程序甚至内核的代码和数据, 这是不安全的, 并且, 编写应用程序的程序员还需要显式地指定链接的地址。因此, 虚拟内存应运而生。同时, 引入虚拟内存后, 还需要重新设计上下文切换和进程控制快, 因此这一章的代码相对复杂。
本章的内容包括:
- 基于
SV39引入虚拟内存和页表 - 重新设计进程控制块结构体
- 重新设计上下文切换
完整版官方文档: https://rcore-os.cn/rCore-Tutorial-Book-v3/chapter4/index.html
精简版文档: https://learningos.cn/rCore-Tutorial-Guide-2023A/chapter4/index.html
1 引入虚拟内存
1.1 虚拟地址空间的概念
文档中对地址空间的介绍已经很完善了, 这里只做简要总结:
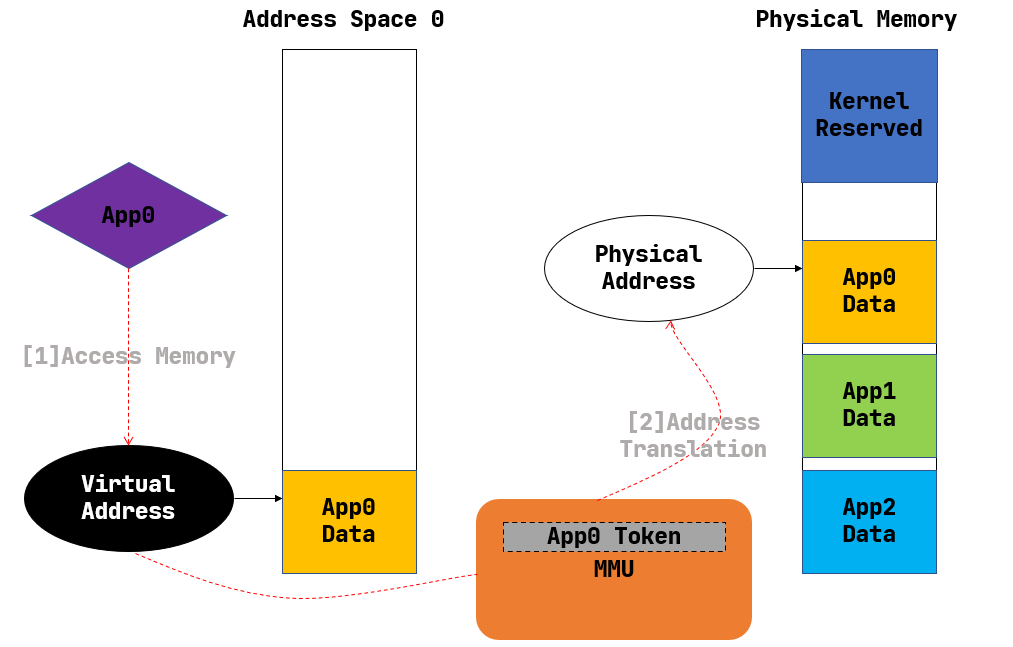
上图摘自官方文档, 根据这个图简单介绍什么是地址空间
- 为什么叫虚拟地址空间?
因为地址不是真正的物理内存地址, 而是需要经过一系列操作映射到物理地址。想象一下, 编写不同C语言程序时,我们的数据可以防止同样的地址中, 但这些不同的应用都可以同时运行,显然他们不是同一个物理地址 - 如何转化为物理地址?
通过硬件单元MMU进行转化,MMU会根据一个映射表查询虚拟地址对应的物理地址, 这个映射表就叫页表, 根页表的地址存放在指定的寄存器中,riscv中是satp寄存器 - 如何实现隔离
U表示用户态是否可以访问,U标记实现了内核和应用程序之间的隔离- 每个应用程序有自己的页表, 并且页表项中的
V标记位表示页表项是否有效, 不属于应用程序的地址没有设置V标记, 这实现了应用程序间的隔离
1.2 分页管理
由于地址的数量是近乎无限的, 不可能以每一个地址为粒度进行映射, 因此将4096个字节作为一个映射单位, 这就是分页的概念, 除了这个原因外, 分页还有一个好处就是方便在硬盘和内存之间加载和替换数据, 因为一次硬盘的IO是昂贵的, 因此一次硬盘的IO应当包含足够大的空间, 通常也就是一个扇区, 大小通常也是4096个字节。
目前的
rCore没有文件系统, 因此虚拟内存的分页也没有在硬盘和内存中进行加载和替换的功能, 只是实现虚拟内存的抽象罢了
虚拟内存中的分页机制可以用一个贴近生活的比喻来理解:假设你有一本非常厚的书(这里的书就像是一个程序需要的内存空间),书架(物理内存)的空间有限,你不能同时把所有的书放在书架上。所以,你决定只把当前正在阅读的几页(活跃的内存页)放在书架上,而把其他的页暂时存放在一个大箱子里(硬盘上的交换空间)。当你想读书中的其他部分时,你会从箱子里取出你需要的页,并把不再需要的页放回箱子里。
虚拟内存分页机制:
分页的基本概念:
就像上面的比喻中,分页机制将虚拟内存分割成许多固定大小的块,每一块称为一个“页”或“页面”。同样地,物理内存也被分割成同样大小的块,称为“页帧”或“物理页”。页表映射:
为了追踪哪些虚拟页对应于物理内存中的哪些页帧,操作系统维护着一张映射表,这就是所谓的页表。当程序尝试访问其虚拟内存中的数据时,操作系统查看页表来找出那个虚拟页在物理内存中的位置。内存访问:
当程序访问一个虚拟地址时,这个地址被分成两部分:页号和页内偏移。页号用于在页表中查找对应的物理页帧,而页内偏移决定了在这个页帧内的具体位置。缺页中断:
如果程序需要访问的页当前不在物理内存中(也就是说,它在硬盘的交换空间里),这会触发一个叫做缺页中断(page fault)的事件。操作系统随后会选择一个物理页(如果需要,可能会将当前的内容保存到硬盘上),并从硬盘上加载所需的虚拟页到这个物理页中,然后更新页表,并重新开始执行刚才中断的指令。页替换算法:
当物理内存满了,而需要加载新的页时,操作系统必须决定哪些页将被移出物理内存以为新页腾出空间。这涉及到页替换算法,如最近最少使用(LRU)、先进先出(FIFO)等,用于选择被替换的页。
通过这种分页机制,操作系统可以非常高效地管理内存,即使物理内存有限,程序也可以使用比物理内存大得多的地址空间。这样不仅提高了内存的使用效率,也简化了程序员的工作,因为他们不需要关心内存的物理限制,只需要关注于程序的逻辑结构。
最后贴上官方文档的图:
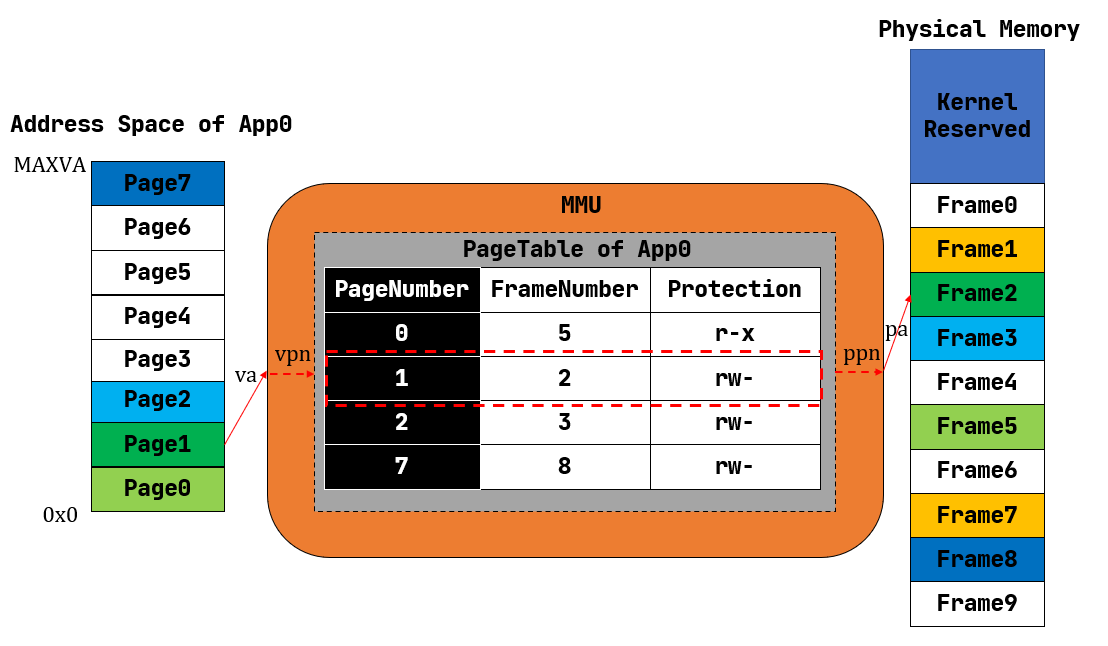
页表中包含3个部分:
- 映射的物理页号
- 页的操作权限
图中的
FrameNumber实际上在页表中是没有的
1.3 SV39分页介绍
这里介绍如何实现映射, 这里采用的是riscv的SV39分页机制:
首先看看虚拟地址和物理地址的格式:

- 虚拟地址被分为39位,意味着虚拟地址空间的大小可以达到239字节,即512GB。其中低12位是页内的偏移量, 高27位可以分为3份, 每份9位, 表示的是在各级页表中的索引(如果看不懂就去看后面给出的地址翻译流程图)
- 物理地址的低12位表示一个页内的偏移,
12-55位表示了页号
下面是详细的SV39分页机制:
三级页表结构:在SV39分页模式下,地址翻译使用三级页表。这意味着虚拟地址被分为四部分:
VPN[2]、VPN[1]、VPN[0]和页内偏移。这里的VPN代表虚拟页号(Virtual Page Number),不同级别的页表项(PTE)由不同的VPN部分索引。页大小:SV39通常使用4KB的页大小,这是最常见的页大小,但也支持大页,如2MB和1GB的大页。因为地址是8字节, 因此一个存放页表项的页就包含了
4096/1024=512个页表项地址转换:虚拟地址转换为物理地址的过程涉及查找三级页表。首先使用VPN[2]在一级页表中查找,得到二级页表的地址;然后使用VPN[1]在二级页表中查找,得到三级页表的地址;最后使用VPN[0]在三级页表中查找,得到物理页号(PPN)。页内偏移保持不变,直接用于定位物理页内的具体地址。
地址翻译缓存(TLB):由于地址翻译过程可能相当耗时,因为它涉及到多次内存访问,RISC-V处理器通常会使用
TLB来缓存最近的地址翻译结果,来加快地址翻译速度。
接下来是地址翻译的流程, 摘自MIT6.S081:
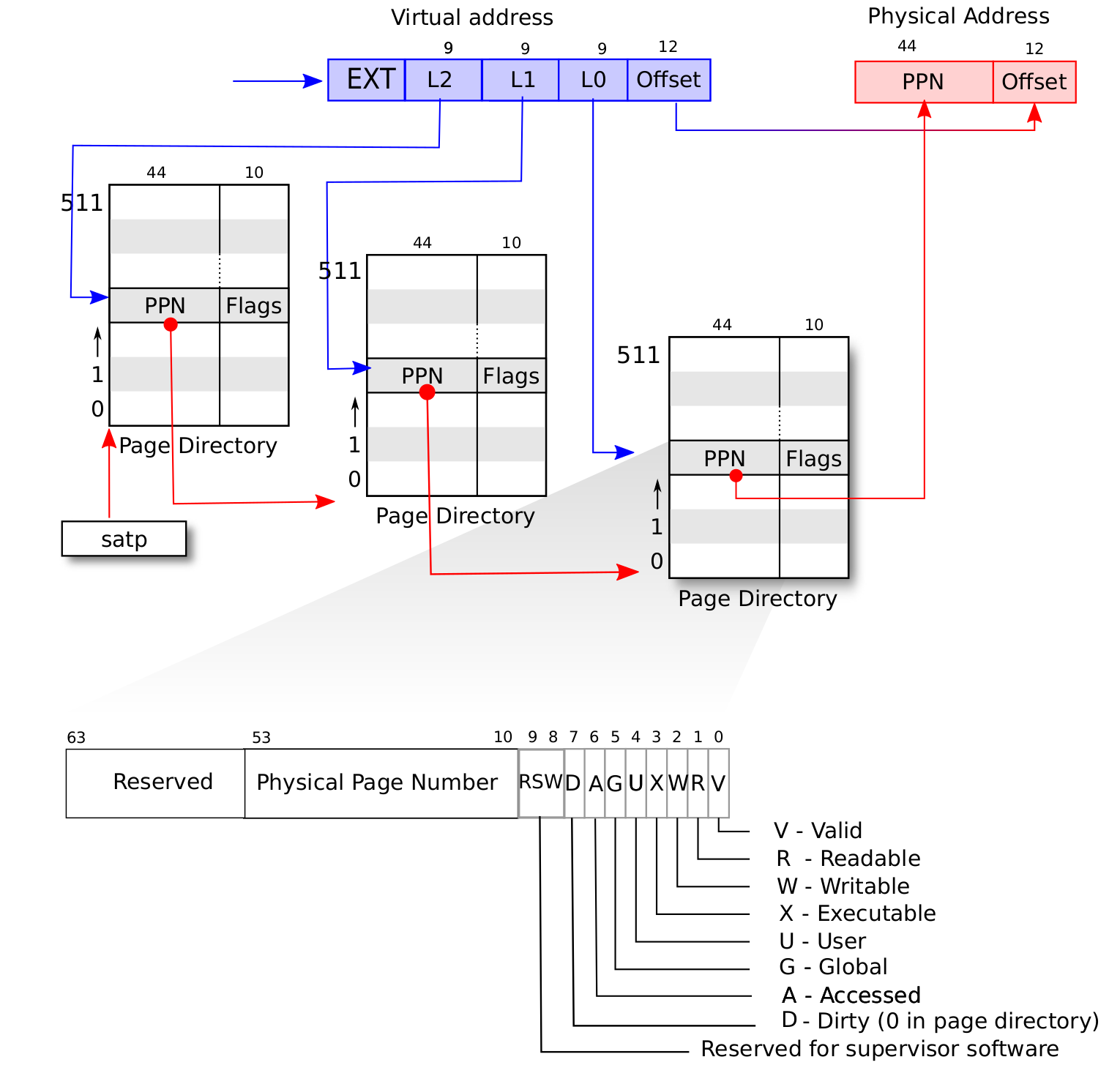
L2是根页表的索引, 29 = 512正好能表示所有的索引, 根页表的页表项记录了L1对应页表的物理页号PPN- 用之前拿到的物理页号
PPN找到L1对应页表的物理页, 用同样的思路找到索引L1的页表项, 其记录了L0对应页表的物理页号PPN - 用之前的
PPN, 结合索引L0拿到实际的数据页的页号PPN - 用最终得到的页号
PPN找到数据页, 使用页内便宜OffSet就找到了最终的物理地址
1.4 SV39分页的代码实现
文档中详细地介绍了页表和地址空间相关数据结构, 这里不详细展开了, 很多内容都是涉及页表号、地址之间的转化以及地址转货为结构体或切片的方法,比较繁琐。 这里只介绍我认为其中比较重要的代码
1.4.1 页帧分配器
这里管理内存既然是以页为单位的,自然需要一个页分配器,分配的页的单位称为页框:
1 | pub struct StackFrameAllocator { |
上面的结构体中, 物理页号区间 [ current , end ) 此前均 从未 被分配出去过,而容器 recycled 以后入先出的方式保存了被回收的物理页号,
具体分配和回收的方法如下:
1 | trait FrameAllocator { |
分配和回收页帧逻辑都很简单:
- 分配时优先从
recycled中重复利用回收的页帧, 否则对current自增完成分配 - 回收时将其放入
recycled
这里有一个很有意思的地方, 就是实际分配时是在前面的StackFrameAllocator基础上再再进行了一层封装:
1 | /// Allocate a physical page frame in FrameTracker style |
这里还是熟悉的 RAII 的思想,将一个物理页帧的生命周期绑定到一个 FrameTracker 变量上,当其生命周期结束时, 使用自定义的drop方法将其回收到StackFrameAllocator的recycle容器中, 这种思想和方法以后还会看到
1.4.2 页表的查询
页表的方法很多, 这里我只列出自己认为比较重要的方法, 首先就是查询页表的方法:
1 | /// Find PageTableEntry by VirtPageNum, create a frame for a 4KB page table if not exist |
这里的find_pte_create和find_pte逻辑类似, 都是实现了之前MIT6.S081中地址翻译的过程, 这里就不重复其过程了
1.4.3 页表的创建与拆除
1 | /// Create a new page table |
页表的创建与拆除就是调用find_pte_create或find_pte, 然后设置页表项完成映射或拆除映射
2 基于虚拟内存的地址空间
2.1 地址空间结构体
完成了虚拟内存的实现后, 下一步是基于虚拟内存实现地址空间的抽象, 在rCore中, 地址空间被进一步划分为多个逻辑段:
1 | // os/src/mm/memory_set.rs |
这里, MemorySet就是一个地址空间, 其中有多个逻辑段存放于一个容器Vec中, 这里也是RAII的思想
1 | pub struct MapArea { |
MapArea的vpn_range表示虚拟页号的返回, data_frames同样是将FrameTracker的生命周期绑定到BTreeMap中
接下来, 只介绍MemorySet和MapArea中比较关键的方法, 因为所有的方法太繁杂了…
2.2 新建和拆除MapArea映射
1 | pub fn map_one(&mut self, page_table: &mut PageTable, vpn: VirtPageNum) { |
map_one的思路如下:
- 新建一个虚拟页到物理页的映射
- 如果映射类型是
MapType::Framed: 从FRAME_ALLOCATOR处分配一个物理页frame,并将vpn和frame插入到data_frames中 - 如果映射类型是
MapType::Identical,ppn和vpn相等
- 如果映射类型是
- 无论是那种类型, 都在
page_table中插入vpn到ppn的映射
unmap_one也是调用PageTable的unmap方法, 思路类似
这里可以看到, MapArea只是逻辑上管理一个虚拟地址段的数据结构, 真正的映射实现还是通过外部提供的PageTable的map实现, 正因如此, MapArea需要被托管到上层的结构体进行管理
最后, map_one和unmap_one只是映射和拆除单一的虚拟页, 因此, 如果在地址空间的所有虚拟页中调用这2个方法, 就完成了整个地址空间的建立和拆除:
1 | pub fn map(&mut self, page_table: &mut PageTable) { |
2.3 内核地址空间
2.3.1 内核地址空间概述
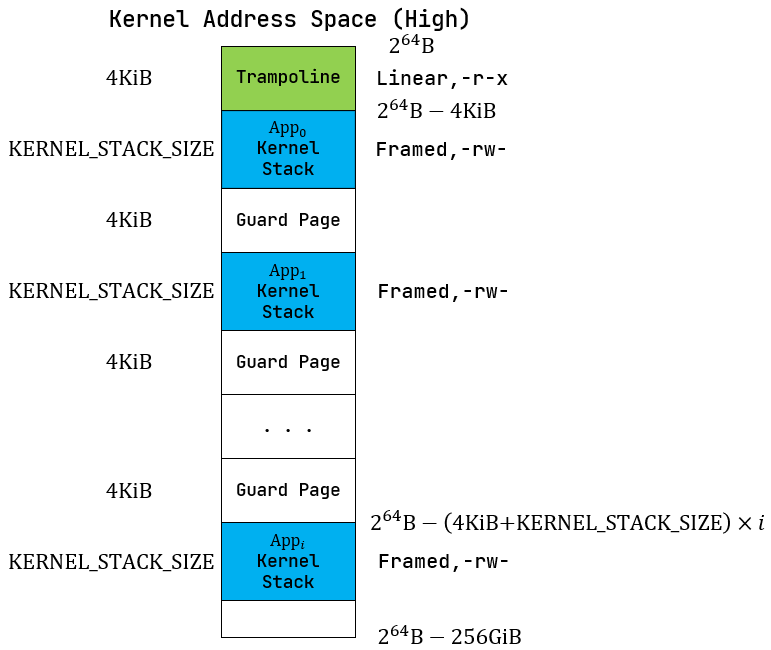
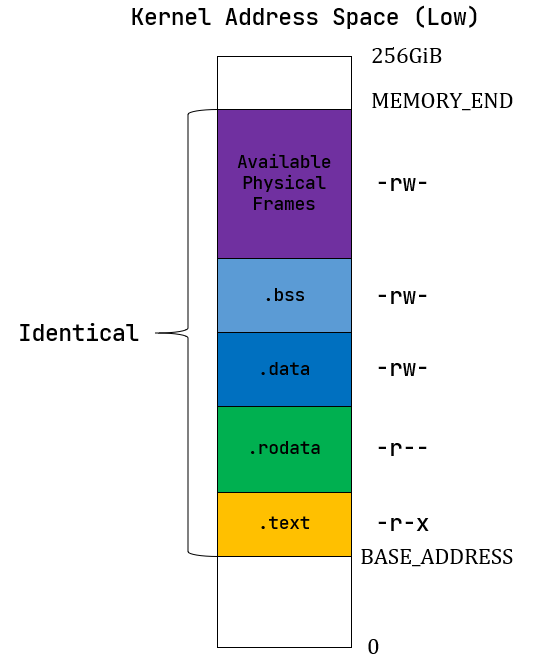
上图摘自官方文档, 第一张图是内核的高地址空间, 第二章图是内核的低地址空间, 和之前ch3类似, 不同的应用程序拥有自己的内核栈, 不同内核栈之间拥有保护页, 说到这里, 那之前ch3的没有引入虚拟内存的内核地址空间不是和现在没啥区别吗? 确实, 因为这里内核地址空间采用的是恒等映射, 也就是内核的虚拟地址和实际物理地址完全相同, 这样也便于内核精确地控制内存。
但区别还是有的,也就是跳板 Trampoline, 这会在后文中介绍
2.3.2 应用地址空间概述
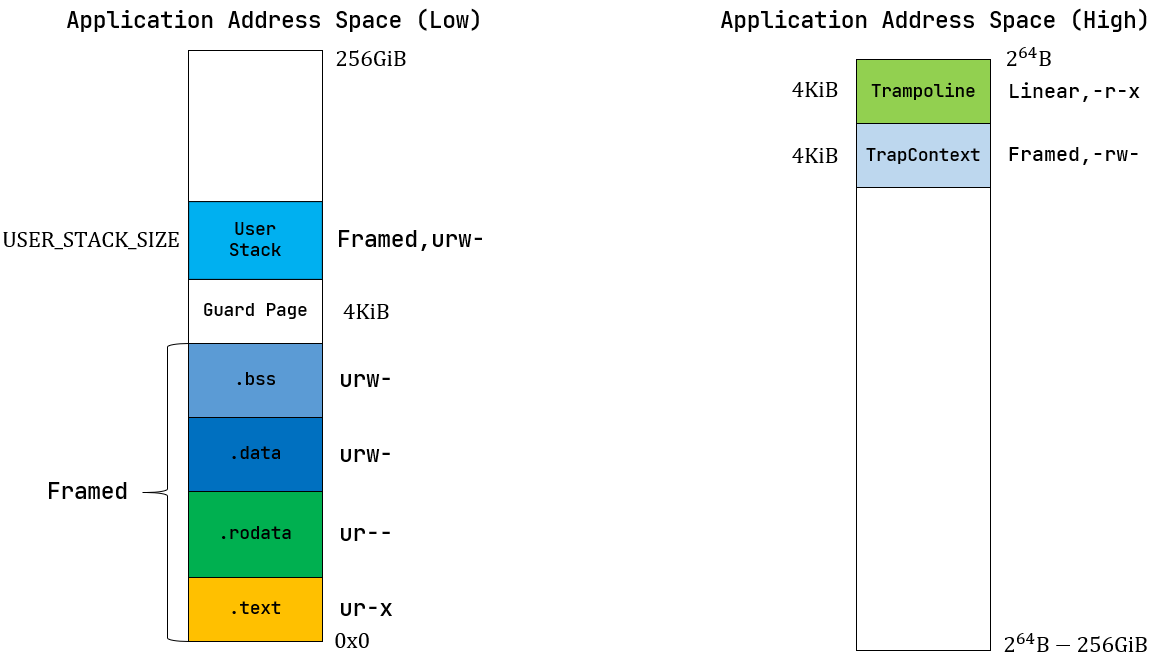
上图摘自官方文档, 和之前的内容相比, 现在的地址克难攻坚在顶层多了Trampoline和TrapContext, 这涉及到引入虚拟内存后的上下文切换, 后面会详细描述
其实地址空间这一部分, 最复杂的是解析
elf的工作, 这一部分rCore目前直接使用了第三方库实现, 没有深入
3 引入虚拟内存后的上下文切换
这一部分才是我们这一章节的最核心的内容
3.1 思考和ch3的变化
回忆ch3的上下文切换, 其在trap中将不同任务的上下文信息保存在自己的内核栈中, 我们注意到在trap.S中有这样的汇编代码:
1 | __alltraps: |
在陷入trap时, 应用程序将用户栈指针和内核栈指针交换, 然后将上下文信息存储在了内核栈上, 这在内核和用户公用一套地址空间时看起来是否自然, 但现在的问题是, 内核和用户的地址空间不一样, 换句话说就是satp中的根页表地址不一样。因此陷入内核时需要将内核地址空间的根页表地址(token)写入satp, 因此需要一个寄存器存储原来用户空间的token, 同时用户栈的指针也需要被存储, 但我们只有一个 sscratch 寄存器可用来进行周转。因此我们没有办法像原来一样将应用程序的上下文信息保存在内核栈中
3.2 从新的trap.S分析TrapContext和Trampoline
先分析新的trap.S:
1 | .altmacro |
这里先只分析__alltraps的代码:
通过注释我们看出, 此时的sscratch存储的是用户态下TrapContext的地址, 这里需要尤其注意, 尽管我们现在进入的内核模式(硬件会自动设置一些csr寄存器), 但是我们目前的地址空间还没有发送变化, 相关寄存器还是用户态时的内容, 也就是说, 此时我们是将上下文地址存储到了用户的地址空间中的一段连续的内存中, 这个区域也就是之前图中的trapContext
存储完成后, 从trapContext的固定位置读取内核的token和内核栈的地址, 重新设置sp后并调用sfence.vma完成地址空间的切换, 这里的问题在于, 完成地址空间切换后, 我们的pc还是指向__alltraps的最后一句jr t1吗?
首先这是必要的, 不然操作系统就没法玩了。但由于地址空间发生了切换,要实现这一点,**trap.S中的代码在内核地址空间和用户地址空间必须是相同的映射吗, 这一块映射的地址段就是Trampoline**
接下来看看映射Trampoline的方法:
1 | fn map_trampoline(&mut self) { |
需要注意的是map_trampoline方法直接被一个地址空间映射, 不属于一个MapArea:
1 | pub fn new_kernel() -> Self { |
4 引入虚拟内存后的任务控制
4.1 任务控制块
1 | pub struct TaskControlBlock { |
引入虚拟内存后, 需要添加地址空间MemorySet的结构体以及每个任务的trap context的物理页号, 这样以来, 内核才可以在任务控制时获取其trap的上下文信息
4.2 任务运行的实例
其实TaskControlBlock很多地方都尽量修改, 但在理解了上下文切换的变化和挑板页Trampoline的原理后, 看看官方文档很容易理解, 就不展开了
这里还是以一个我画的流程图的形式来总结引入虚拟内存的变化, 这里从运行第一个程序开始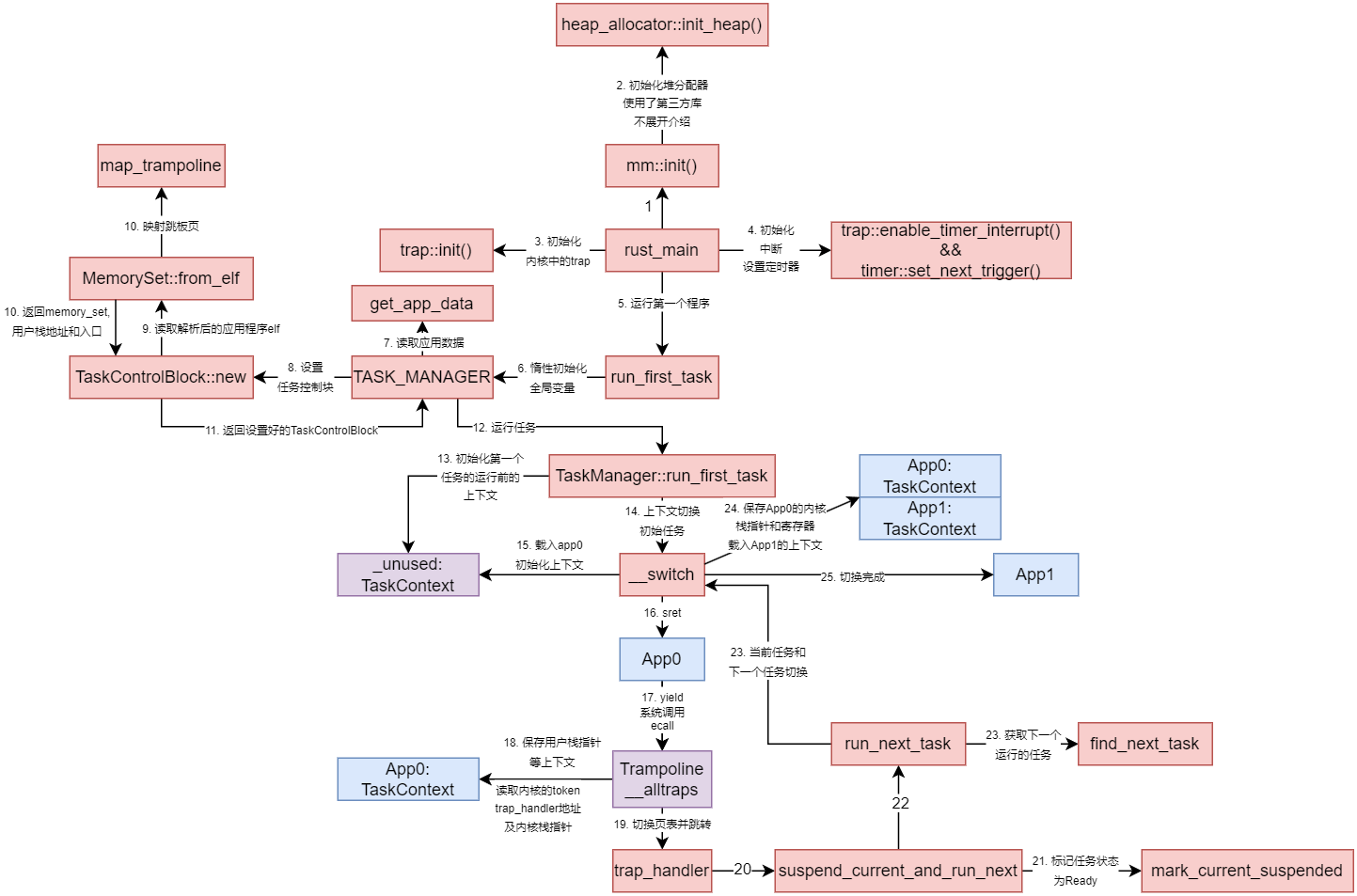
图例说明:
- 红色表示内核函数
- 蓝色表示用户函数或用户地址空间的内存段
- 紫色表示跳板页的中间状态
注意, 这里上下文切换时, App0的TaskContext有2次使用:
__alltraps时使用了TaskContext:
这里的目的是切换App0的用户上下文和内核上下文App0切换到App1的__switch时使用了TaskContext:
这里是保存App0在内核态时的寄存器和内核栈指针, 也就是切换的是App0的内核态上下文和App1的上下文, 在这里App1的上下文是用户上下文, 因为APP1也是第一次运行, 但之运行一段时间后的上下文切换则不一定, 可能切换到某个App之前让出Cpu时执行到__switch的内核上下文, 例如这里的App0
这里由于太拥挤了, 没有画出App0之后恢复执行的流程, 这里简单说明一下:
- 某一时刻另外的
App因执行结束或者让出CPU, 又进入了run_next_task - 这次
run_next_task选择下一个task是App0 - 由于
App0的TaskContext保存了上一次其在内核中被切换的上下文: 执行run_next_task时的返回地址ra,ra被加载后将按照下面的路径返回:__switch->run_next_task->suspend_current_and_run_next->trap_handler - 此后执行:
trap_return->__restore->之前让出CPu的用户代码, 这个过程中的最后一步中, 之前恢复的sepc会在sret返回时会被加载到pc