本文不会将原本rCore文档的内容重复太多, 主要是补充学习过程中遇到的知识点, 因此还需结合原文使用, 原文在后面的链接中
本章节的内容是介绍如何构建一个能在裸机上运行的Rust程序, 这一部分其实也是很多操作系统课程, 包括MIT 6.S081缺少的部分, 通过这一部分, 我们可以学习到操作系统和硬件之间是如何工作的, 还是挺重要的。
本文是只个人对官方文档第一章知识的梳理和补充,因此一些基础的知识概念并不会再设计, 这些细节请阅读:
完整版官方文档: https://rcore-os.cn/rCore-Tutorial-Book-v3/chapter1/1app-ee-platform.html
精简版文档: https://learningos.cn/rCore-Tutorial-Guide-2023A/chapter1/index.html
1 理论知识梳理
1.1 应用程序执行环境
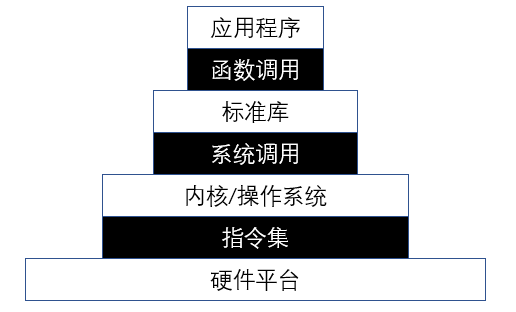
上图是从官方文档中摘取的,操作系统承接了硬件平台和各种编程语言标准库中的系统调用, 裸机程序就是没有操作系统的程序, 因此我们实现的程序需要绕过标准库直接和硬件打交道, 一句话就是, 不能调包了, 得手写
1.2 平台与目标三元组
目标三元组 (Target Triplet): CPU 指令集、操作系统类型和标准运行时库。
Rust工具链中的rustc可以获取以上信息:
1 | $ rustc --version --verbose |
host中展示了: 目标平台是 x86_64-unknown-linux-gnu, CPU 架构是 x86_64,CPU 厂商是 unknown, 操作系统是 linux,运行时库是 gnu
1.3 从qemu看层级架构
1 | qemu-system-riscv64 \ |
下面是qemu的启动命令, 其中os.bin就是我们构建的裸机程序, 但为什么又存在一个rustsbi-qemu.bin呢?
这涉及到计算机的启动流程, 在qemu虚拟平台上, 第一阶段的启动是qemu自己提供的程序, 第二段启动是bootloader, bootloader进行硬件相关的初始化工作, 第三个阶段是加载操作系统镜像(就是这里的裸机程序)。每一阶段的程序都需要将下一阶段程序放在指定的位置并进行跳转。
也就是说,我们的裸机程序直接在bootloader启动后就运行了, 不需要操作系统
更详细的启动流程请见官方文档说明
1.4 裸机程序构建思路
第一章中, 裸机程序的构建实际上就是一步步剥离标准库并实现替代标准库中相应数据结构和函数的过程。因为std依赖于操作系统, 因此需要用不依赖与操作系统的core代替
裸机程序的代码其实不复杂, 只是涉及一些不常用的知识点, 包括内联汇编等, 这些在后面的补充知识会介绍到, 除此外, 原始文档给的代码很详细了, 因此这里就不进行代码分析了。
1.5 链接脚本的作用
由于上述的原因,bootloader启动后跳转的地址是固定的(bootloader已经提供了, 不需要自己实现), 所以程序需要将起始位置放置在这固定的内存位置(此时还没有页表, 是物理内存地址), 这就是链接脚本的作用
具体内存也参见官方文档说明
1.6 剥离elf
编译后的代码存在一些元数据段, 因此需要将其剥离才能将程序的第一条指令放在指定的位置:
1 | rust-objcopy --strip-all target/riscv64gc-unknown-none-elf/release/os -O binary target/riscv64gc-unknown-none-elf/release/os.bin |
具体的解析参考源文档
1.7 sbi的调用时机
我第一次阅读官方文档后仍然有一个疑惑, 就是我们是如何调用sbi, 提供的服务的?
实际上还是使用ecall, 先贴出调用sbi的代码:
1 |
|
这里, 和U模式下的系统调用中ecall的使用类似, S模式下也是通过ecall来进入M模式, 从而使用sbi提供的服务。相关部分会在后续的系统调用章节进行更多的介绍, 此处只简单介绍:
- S 模式下的操作系统设置
a0-a7和t0寄存器,以指定所需的 SBI 调用和参数。 - 操作系统执行
ecall指令,触发异常并切换到 M 模式。 - M 模式下的
SBI实现查看寄存器的值,确定请求的服务并执行它。 SBI实现将结果存入寄存器中。- 控制权返回给 S 模式的操作系统,操作系统读取寄存器以获取服务结果。
这种机制允许分离操作系统和机器模式执行环境,使得操作系统无须了解硬件的详细实现,也能够利用硬件提供的功能。
2 补充知识
2.1 cargo配置
Rust 项目中,.cargo/config 是一个配置文件,用于定义和调整 Cargo 的各种行为和设置。Cargo 是 Rust 的包管理器和构建工具,它处理依赖下载、编译过程及更多功能。.cargo/config 文件通常位于项目的根目录下的 .cargo 文件夹内,或者在用户的主目录下的 .cargo 文件夹内作为全局配置。
下面是 .cargo/config 文件中一些基本配置操作的概述:
设置构建目标
可以指定默认的构建目标(target triple):1
2[build]
target = "riscv64gc-unknown-none-elf"设置构建标志
可以添加自定义的构建标志,比如优化等级、链接参数等:1
2[build]
rustflags = ["-C", "opt-level=2"]设置环境变量
可以设置在构建脚本中使用的环境变量:1
2[build]
rustc-env = ["RUST_BACKTRACE=1"]定义自定义构建目标
如果有一个自定义的架构,可以指定链接器和其他构建参数:1
2[target.i686-unknown-linux-gnu]
linker = "gcc"重写依赖源
如果需要从不同的源或者私有源下载依赖项,可以重写它们:1
2
3
4
5[source.crates-io]
replace-with = 'tuna'
[source.tuna]
registry = "https://mirrors.tuna.tsinghua.edu.cn/git/crates.io-index.git"设置别名
可以为常用的命令设置别名,以便更快地调用:1
2
3
4[alias]
b = "build"
r = "run"
t = "test"配置货物配置文件
可以为不同的构建配置(例如 debug 或 release)指定不同的设置:1
2
3
4
5[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
在实际使用中,应该根据项目的具体需要来调整这些设置。此外,.cargo/config 文件支持层级结构,可以在多个目录级别定义配置文件,Cargo 会合并这些配置,其中更具体(更深层目录)的配置会覆盖更通用(更高层目录)的配置。
下面是本项目的cargo配置文件:
1 | [build] |
其中 两个 Rust 编译器标志(rustflags)解释如下:
-Clink-arg=-Tsrc/linker.ld: 这告诉 Rust 编译器传递linker.ld链接器脚本文件的路径给链接器。链接器脚本文件通常用于指导链接器如何生成最终的可执行文件,包括内存布局等。这里linker.ld文件位于项目的src目录下。-Cforce-frame-pointers=yes: 这指示 Rust 编译器在生成可执行文件时,即使在优化模式下也保留帧指针。帧指针通常用于帮助调试和获取函数调用栈信息,但有时在优化时会被省略以提高性能。
2.2 链接脚本的语法
下面是ch1中使用的链接脚本:
1 | OUTPUT_ARCH(riscv) |
链接脚本 (Linker Script) 是由 GNU 链接器 (ld) 使用的脚本语言,用于控制程序的链接过程。链接脚本的语法允许用户定义输出文件的内存布局,指定各个段的位置、大小和属性。
输出架构 (
OUTPUT_ARCH)OUTPUT_ARCH(architecture)
指定目标架构,告诉链接器生成针对特定架构的代码。入口点 (
ENTRY)ENTRY(symbol)
指定程序的入口点,即程序开始执行的地方。符号赋值
symbol = expression;
定义符号,并将其设置为特定的值或地址。段定义 (
SECTIONS)SECTIONS {...}
段定义块开始和结束的标志,里面包含了对输出段的具体指令。地址计数器
.(点) 表示当前地址计数器,可以设置为特定值或者用于符号赋值。
进行字段包含后, 其会自动地增长段地址和属性
segment : { subsections }
定义一个段(如.text,.data),并指定包含在该段的子段内容。子段
*(.subsection)
将特定的子段包含进父段中,如将.text子段包含进.text段中。对齐指令 (ALIGN)
ALIGN(expression)
对当前地址计数器进行对齐,确保地址是特定值的倍数,常用于页对齐或数据结构对齐。输出段属性
>region
指定输出段应该放置在哪个内存区域。AT(address)
指定输出段的加载地址,与放置地址可能不同。:alignment
指定段对齐。
- 内存布局 (
MEMORY)
MEMORY { ... }
定义内存布局和属性,用于告诉链接器如何使用不同的内存区域。
/DISCARD/
/DISCARD/ : { ... }
用于丢弃不需要的段,例如调试信息或未使用的段。
现在再来看本章的链接脚本:
1 | OUTPUT_ARCH(riscv) |
这就很好理解了, 其分别将指的目标文件中各个段的内容整合在一起, 并且为每个段的开始地址声明了变量: stext, etext, erodata, edata, ebss
2.3 Rust宏语法
本项目执行实现了println!宏, 在我之前学Rust时, 主要是使用已定义的宏, 自己实现宏的部分仅仅是略过, 因此这里特别来复习下宏的定义, 项目中定义了下面的宏:
1 |
|
解释如下:
#[macro_export]
表示这个宏是要被导出的,使得当这个宏所在的crate被其他crate引用时,这个宏也可以被使用。macro_rules!
这是宏的声明开始,macro_rules!是Rust中定义宏的关键字,后面跟着的println是宏的名字。宏的匹配部分
1
($fmt: literal $(, $($arg: tt)+)?)
这行定义了宏的模式匹配部分。它匹配一个字面量
$fmt作为第一个参数,后面可以跟一个逗号和任意数量的额外参数$arg。参数使用Rust宏的”token tree” (tt)设计,它可以匹配几乎任何Rust语法。
$fmt: literal表示第一个参数必须是一个字面量(通常是一个字符串字面量)。literal: 一个特定的关键字, 用来指定宏参数应该是一个字面量$(, $($arg: tt)+)?是一个可选的模式,它使用了Rust宏的重复模式:$($arg: tt)+表示可以有一个或多个额外的参数,每个参数都是一个token tree。
补充宏知识
在Rust的宏定义中,$和?符号都用于模式匹配,但它们在宏规则中扮演着不同的角色。
$符号:
- 用法1: 指示一个变量的开始,可以捕获宏输入中的相应部分。在宏规则中,
$后面通常跟着一个标识符和一个冒号,再跟着一个设计符(designator),用来指定变量的类型。例如,$var:ident表示匹配一个标识符并将其绑定到变量$var中。- 用法2: 标识重复的开始,例如
$($arg:tt),*表示重复匹配$arg零次或多次,每次匹配由逗号分隔。?符号: 它用于表示前面的模式是可选的。在宏规则中,将?放在模式的外部,表示这个模式可以出现零次或一次。这类似于正则表达式中的?运算符。例如,在$($arg:tt)?中,?表明$arg是可选的,可以有或没有。+符号: 它用于表示前面的模式出现一次多次。在宏规则中,将+放在模式的外部,表示这个模式可以出现一次或多次。这类似于正则表达式中的+运算符。例如,在$($arg:tt)+中,?表明$arg以出现一次或多次结合上面的符号使用时,
$捕获宏参数,而?或+指定这些参数的重复模式。所以$(, $($arg: tt)+)?这部分的意思是:
$( ... )?表示整个模式是可选的,即可以有也可以没有。,表示模式的开始,一个逗号,用来分隔参数。$($arg: tt)+表示匹配一个或多个$arg,每个$arg是一个token tree。
- 匹配后的动作
根据前面的分析, 这个模式可以匹配零个或多个以逗号分隔的token trees,如果匹配到,则将这些token trees作为参数传递给format_args!宏。1
$crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?))
这是宏展开的部分。
$crate是一个特殊的变量,它在宏内部用于引用当前crate的根路径,这样即使宏被移动到其他crate中,它也能正确地引用到原来的crate中定义的项。format_args!是Rust的一个内置宏,用于处理格式化参数。它接受一个格式化字符串和对应的参数,并返回一个可以延迟计算的格式化参数结构体,这通常用于避免字符串的分配和复制。concat!($fmt, "\n")将传入的格式化字符串和一个换行符连在一起,确保输出后会自动换行。$(, $($arg)+)?是对传入参数的引用,如果有参数的话,它们会被插入到格式化参数结构体中。
2.4 Rust内联汇编
使用的RustSbi中存在如下的Rust内联汇编的用法:
1 |
|
解释如下:
#[inline(always)]Rust的属性#[inline(always)]告诉编译器这个函数应该总是被内联,也就是说,在每个调用点替换为函数体的代码,而不是实际进行函数调用。asm!asm!宏是用来编写内联汇编代码的,这段代码直接使用了RISC-V的汇编语法:"li x16, 0":这条指令将立即数0加载到寄存器x16中。li代表”load immediate”。"ecall":陷入更低级的模式inlateout("x10") arg0 => ret
在ecall执行后,返回值通常存放在x10寄存器中。Rust内联汇编通过inlateout("x10") arg0 => ret这个约束来传递这个信息,即arg0的值在ecall执行前被放入x10寄存器中,并且ecall执行后,x10寄存器中的值会存放到变量ret中。in("x11") arg1&&in("x12") arg2&&in("x17") which
在执行汇编代码前将值加载到指定的寄存器中。在这种情况下,arg1被加载到x11寄存器,arg2被加载到x12寄存器,which被加载到x17寄存器。
这里容易产生一个误区, 就是, 存放输入寄存器的操作位于ecall出现之后, 实际上所有的输入操作数都是在执行任何汇编指令之前就被放入相应寄存器中的。
2.5 直接嵌入汇编代码
可以使用 global_asm! 宏包含全局汇编代码。这个宏允许在 Rust 代码中直接嵌入汇编代码片段,并且这些代码会在全局范围内被汇编器处理。
以下项目代码中的 global_asm! 的例子:
1 |
|