最新的更新在博客 ToniBlog
本文将介绍lab3B部分的实现, lab3B要求基于在lab3A的基础上实现快照, 仅从lab本省来讲其实很简单, 可以说是目前我做的所有lab里面难度最小的一个模块了, 但实际上遇到了很多困难, 调试的时间比lab3A还久, 核心原因就是自己的lab2实现的raft底层有一些问题(真真真真太折磨了, 即时过了所有单元测试, 还是时不时地在后续的lab暴露出问题来, 并且这些问题还挺难定位, 得仔细分析海量的log输出才可以)
Lab文档见: http://nil.csail.mit.edu/6.5840/2023/labs/lab-kvraft.html
我的代码: https://github.com/ToniXWD/MIT6.5840/tree/lab3B
1 快照的生成和传递逻辑 简单说, lab3B就是要在底层raft的log过大时生成快照并截断日志, 从而节省内存空间, 并且快照会持久化存储到本地。因此, 原来的代码结构只需要在以下几个方面做出调整:
需要再某个地方定期地判断底层raft的日志大小, 决定是否要生成快照, 生成快照直接调用我们在lab2中实现的接口Snapshot即可
由于follower的底层raft会出现无法从Leader获取log的情况, 这时Leader会发送给follower的raft层一个快照, raft层会将其上交给server, server通过快照改变自己的状态机
server启动时需要判断是否有持久化的快照需要加载, 如果有就加载
2 代码实现 2.1 快照应该包含什么? 快照首先应该包含的肯定是内存中的KV数据库, 也就是自己维护的map, 但是还应该包含对每个clerk序列号的记录信息, 因为从快照恢复后的server应该具备判断重复的客户端请求的能力, 同时也应该记录最近一次应用到状态机的日志索引, 凡是低于这个索引的日志都是包含在快照中
因此, server结构体需要添加如下成员:
1 2 3 4 5 type KVServer struct { ... persister *raft.Persister lastApplied int }
2.2 加载和生成快照 通过上述分析, 快照的加载和生成就很简单了,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func (kv *KVServer) byte { w := new (bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(kv.db) e.Encode(kv.historyMap) serverState := w.Bytes() return serverState } func (kv *KVServer) byte ) { if len (snapShot) == 0 || snapShot == nil { ServerLog("server %v LoadSnapShot: 快照为空" , kv.me) return } r := bytes.NewBuffer(snapShot) d := labgob.NewDecoder(r) tmpDB := make (map [string ]string ) tmpHistoryMap := make (map [int64 ]*Result) if d.Decode(&tmpDB) != nil || d.Decode(&tmpHistoryMap) != nil { ServerLog("server %v LoadSnapShot 加载快照失败\n" , kv.me) } else { kv.db = tmpDB kv.historyMap = tmpHistoryMap ServerLog("server %v LoadSnapShot 加载快照成功\n" , kv.me) } }
GenSnapShot和LoadSnapShot分别生成和加载快照, 唯一需要注意的就是这两个函数应当在持有锁时才能调用
2.3 生成快照的时机判断 由于ApplyHandler协程会不断地读取raft commit的通道, 所以每收到一个log后进行判断即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func (kv *KVServer) for !kv.killed() { log := <-kv.applyCh if log.CommandValid { ... if log.CommandIndex <= kv.lastApplied { kv.mu.Unlock() continue } ... if kv.maxraftstate != -1 && kv.persister.RaftStateSize() >= kv.maxraftstate/100 *95 { snapShot := kv.GenSnapShot() kv.rf.Snapshot(log.CommandIndex, snapShot) } kv.mu.Unlock() } ... } }
这里还需要进行之前提到的判断: 低于lastApplied索引的日志都是包含在快照中, 在尽显lab3A的操作之后, 再判断是否需要生成快照, 在我的实现中, 如果仅仅比较maxraftstate和persister.RaftStateSize()相等才生成快照的话, 无法通过测例, 因为可能快照RPC存在一定延时, 所以我采用的手段是只要达到阈值的95%, 就生成快照
2.4 加载快照的时机判断 首先启动时需要判断是否需要加载快照, 然后就是ApplyHandler从通道收到快照时需要判断加载, 都很简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func StartKVServer (servers []*labrpc.ClientEnd, me int , persister *raft.Persister, maxraftstate int ) ... kv.persister = persister ... kv.mu.Lock() kv.LoadSnapShot(persister.ReadSnapshot()) kv.mu.Unlock() go kv.ApplyHandler() return kv }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func (kv *KVServer) for !kv.killed() { log := <-kv.applyCh if log.CommandValid { ... } else if log.SnapshotValid { kv.mu.Lock() if log.SnapshotIndex >= kv.lastApplied { kv.LoadSnapShot(log.Snapshot) kv.lastApplied = log.SnapshotIndex } kv.mu.Unlock() } } }
3 调试Bug和修复 这里才是这个lab的重头戏, 我在完成上述所有修改后, 会在TestSnapshotUnreliable3B这个单元测试中大概率卡死, 一直会卡到go默认的十分钟单元测试时间截止后才报错退出, 在反复检查了死锁 和持锁接发通道消息 等常见问题并确认无误后, 我再次观察超时报错的堆栈信息和日志输出, 得到结论就是:raft层因为无法承受测试的高并发程度而导致大量的RPC请求失败, 从而导致clerk无限重复发送请求RPC(我的实现是RPC请求失败)就重试
……陷入了沉思, 自己还是菜啊, 但代码还得慢慢修, 总不能把raft推倒重来吧……
我最后分别从raft层和server层进行了优化
3.1 raft层优化 3.1.1 修复过多的AppendEntries RPC 通过对日志的调试发现, AppendEntries RPC数量太多了, 这是因为我在lab3A中做了如下修改:
1 2 3 4 5 6 7 8 func (rf *Raft) interface {}) (int , int , bool ) { ... defer func () rf.ResetHeartTimer(1 ) }() return rf.VirtualLogIdx(len (rf.log) - 1 ), rf.currentTerm, true }
也就是在接受一个请求并追加一个log后立即发送AppendEntries RPC, 但是如果在高并发的场景下, 新的请求绵绵不断地到来, 每到达一个请求都发一个RPC, 并且每个RPC可能只包含了长度为1的日志切片, 这是不太合理的设计, 过多的RPC使得raft无法及时处理而出现RPC卡死的情况, 因此, 我手动修改了重置定时器的时间为15ms, 这个值比心跳间隔小很多, 但又不是很小, 足以在满足响应速度的前提下摊销多个命令, 使一次AppendEntries RPC包含多个新的日志项:
1 2 3 4 5 6 7 8 func (rf *Raft) interface {}) (int , int , bool ) { ... defer func () rf.ResetHeartTimer(15 ) }() return rf.VirtualLogIdx(len (rf.log) - 1 ), rf.currentTerm, true }
至于为什么是15ms…, 我自己也说不出理由, 随便设的, 比心跳小很多, 但又不太小就是了, 本质目的就是积攒多个AppendEntries RPC后一次性发送, 避免AppendEntries RPC数量过大
3.1.2 修复过多的InstallSnapshot RPC 在我原来的设计中, InstallSnapshot RPC的发送有2中情形:
handleAppendEntries在处理AppendEntries RPC回复时发现follower需要的日志项背快照截断, 立即调用go rf.handleInstallSnapshot(serverTo)协程发送快照心跳函数发送时发现PrevLogIndex < rf.lastIncludedIndex, 则发送快照
这和之前的情形类似, 在高并发的场景下,follower和Leader之间的日志复制也很频繁, 如果某一个日志触发了InstallSnapshot RPC的发送, 接下来连续很多个日志也会触发InstallSnapshot RPC的发送, 因为InstallSnapshot RPC的发送时间消耗更大, 这样以来, 又加大了raft的压力, 所以, 我对InstallSnapshot RPC的发送做出修改:
handleAppendEntries在处理AppendEntries RPC回复时发现follower需要的日志项背快照截断, 仅仅设置rf.nextIndex[serverTo] = rf.lastIncludedIndex, 这将导致下一次心跳时调用go rf.handleInstallSnapshot(serverTo)协程发送快照心跳函数发送时发现PrevLogIndex < rf.lastIncludedIndex, 则发送快照
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func (rf *Raft) int , args *AppendEntriesArgs) { ... if reply.Term == rf.currentTerm && rf.role == Leader { if reply.XTerm == -1 { DPrintf("leader %v 收到 server %v 的回退请求, 原因是log过短, 回退前的nextIndex[%v]=%v, 回退后的nextIndex[%v]=%v\n" , rf.me, serverTo, serverTo, rf.nextIndex[serverTo], serverTo, reply.XLen) if rf.lastIncludedIndex >= reply.XLen { rf.nextIndex[serverTo] = rf.lastIncludedIndex } else { rf.nextIndex[serverTo] = reply.XLen } return } ... if i == rf.lastIncludedIndex && rf.log[rf.RealLogIdx(i)].Term > reply.XTerm { rf.nextIndex[serverTo] = rf.lastIncludedIndex } else if rf.log[rf.RealLogIdx(i)].Term == reply.XTerm { ... } else { if reply.XIndex <= rf.lastIncludedIndex { rf.nextIndex[serverTo] = rf.lastIncludedIndex } else { rf.nextIndex[serverTo] = reply.XIndex } } return } }
3.2 server层优化 server层应该尽量减小对raft层的接口的调用, 因为大量的接口调用将获取raft层的一把大锁, 从而阻碍RPC的响应
3.2.1 调用Start前过滤 之前的实现中, 无论是Put/Append还是Get, 都是封装成OP结构体, 在HandleOp中一股脑调用Start扔给raft层处理, 然后在ApplyHandler处进行去重判断, 现在可以在调用raft层的Start之前就从historyMap中判断是否有历史记录可以直接返回:
1 2 3 4 5 6 7 8 9 10 11 func (kv *KVServer) kv.mu.Lock() if hisMap, exist := kv.historyMap[opArgs.Identifier]; exist && hisMap.LastSeq == opArgs.Seq { kv.mu.Unlock() ServerLog("leader %v HandleOp: identifier %v Seq %v 的请求: %s(%v, %v) 从历史记录返回\n" , kv.me, opArgs.Identifier, opArgs.OpType, opArgs.Key, opArgs.Val) return *hisMap } kv.mu.Unlock() ... }
3.2.2 减少GetState的调用 ratf的GetState也会获取锁, 从而阻碍RPC的响应速度, 我原来的实现中, GetState会在2个地方调用:
Get和PutAppend调用GetState判断是否是leader, 不是则返回错误ApplyHandler在通过通道唤醒HandleOp时, 需要判断当前节点是不是leader, 不是leader则不需要唤醒
以上2不操作看似合理, 但实际上是冗余的:
首先, Get和PutAppend在后续的HandleOp会调用Start, Start也会因为当前节点不是leader而返回, 所以GetState是冗余的, 反而阻碍RPC响应速度
其次, ApplyHandler在通过通道唤醒HandleOp时, 日志项本身有term的记录, HandleOp会调用Start时也会获取那时的term, HandleOp只需要在被唤醒后比较前后的term是否相同, 就可以判断出当前的节点是不是一个过时的leader
以上2处修改很简单, 由于是删代码而不是新增和修改, 就不贴代码了, 感兴趣可以看仓库
3.2.3 clerk先sleep再重试 这个修改也很简单, 如果server返回了需要重试类型的错误, clerk先sleep一会, 再重试, 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 func (ck *Clerk) string ) string { args := &GetArgs{Key: key, Seq: ck.GetSeq(), Identifier: ck.identifier} for { reply := &GetReply{} ok := ck.servers[ck.leaderId].Call("KVServer.Get" , args, reply) if !ok || reply.Err == ErrNotLeader || reply.Err == ErrLeaderOutDated { if !ok { reply.Err = ERRRPCFailed } if reply.Err != ErrNotLeader { DPrintf("clerk %v Seq %v 重试Get(%v), Err=%s" , args.Identifier, args.Key, args.Key, reply.Err) } ck.leaderId += 1 ck.leaderId %= len (ck.servers) time.Sleep(RpcRetryInterval) continue } switch reply.Err { case ErrChanClose: DPrintf("clerk %v Seq %v 重试Get(%v), Err=%s" , args.Identifier, args.Key, args.Key, reply.Err) time.Sleep(time.Microsecond * 5 ) continue case ErrHandleOpTimeOut: DPrintf("clerk %v Seq %v 重试Get(%v), Err=%s" , args.Identifier, args.Key, args.Key, reply.Err) time.Sleep(RpcRetryInterval) continue case ErrKeyNotExist: DPrintf("clerk %v Seq %v 成功: Get(%v)=%v, Err=%s" , args.Identifier, args.Key, args.Key, reply.Value, reply.Err) return reply.Value } DPrintf("clerk %v Seq %v 成功: Get(%v)=%v, Err=%s" , args.Identifier, args.Key, args.Key, reply.Value, reply.Err) return reply.Value } } func (ck *Clerk) string , value string , op string ) { args := &PutAppendArgs{Key: key, Value: value, Op: op, Seq: ck.GetSeq(), Identifier: ck.identifier} for { reply := &PutAppendReply{} ok := ck.servers[ck.leaderId].Call("KVServer.PutAppend" , args, reply) if !ok || reply.Err == ErrNotLeader || reply.Err == ErrLeaderOutDated { if !ok { reply.Err = ERRRPCFailed } if reply.Err != ErrNotLeader { DPrintf("clerk %v Seq %v 重试%s(%v, %v), Err=%s" , args.Identifier, args.Key, args.Op, args.Key, args.Value, reply.Err) } ck.leaderId += 1 ck.leaderId %= len (ck.servers) time.Sleep(RpcRetryInterval) continue } switch reply.Err { case ErrChanClose: DPrintf("clerk %v Seq %v 重试%s(%v, %v), Err=%s" , args.Identifier, args.Key, args.Op, args.Key, args.Value, reply.Err) time.Sleep(RpcRetryInterval) continue case ErrHandleOpTimeOut: DPrintf("clerk %v Seq %v 重试%s(%v, %v), Err=%s" , args.Identifier, args.Key, args.Op, args.Key, args.Value, reply.Err) time.Sleep(RpcRetryInterval) continue } DPrintf("clerk %v Seq %v 成功: %s(%v, %v), Err=%s" , args.Identifier, args.Key, args.Op, args.Key, args.Value, reply.Err) return } }
4 测试
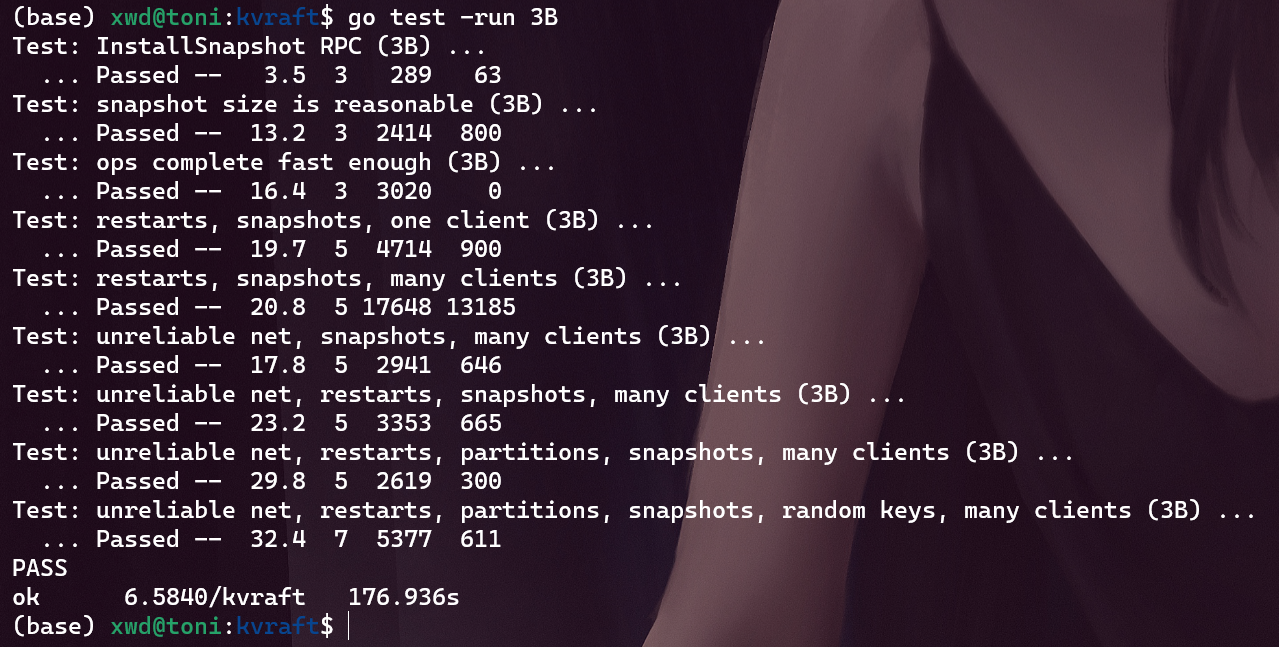
执行测试命令测试lab3B不想优化了, 麻木了)
该代码经过150次测试没有报错
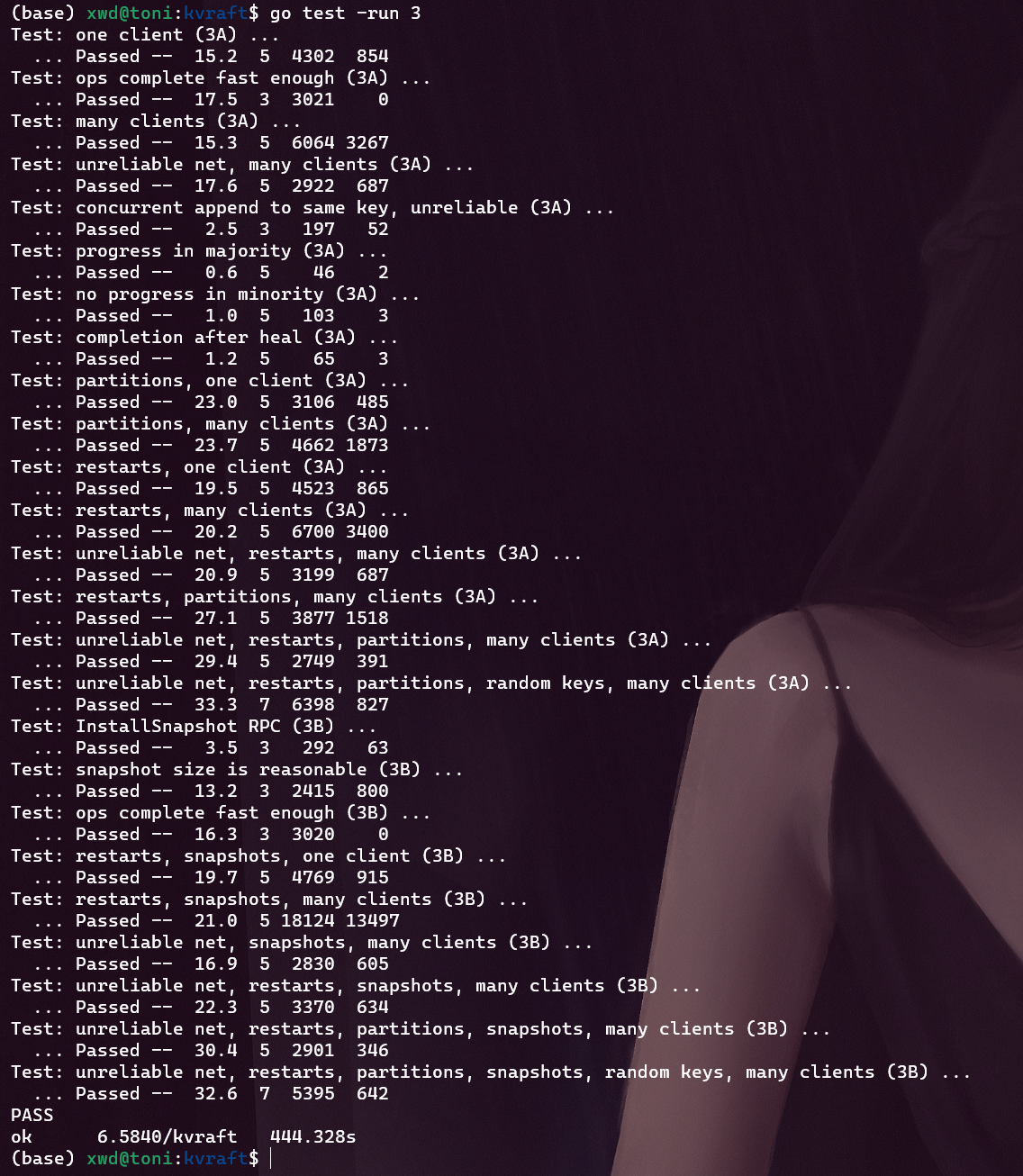
执行测试命令测试整个lab3
结果如下:
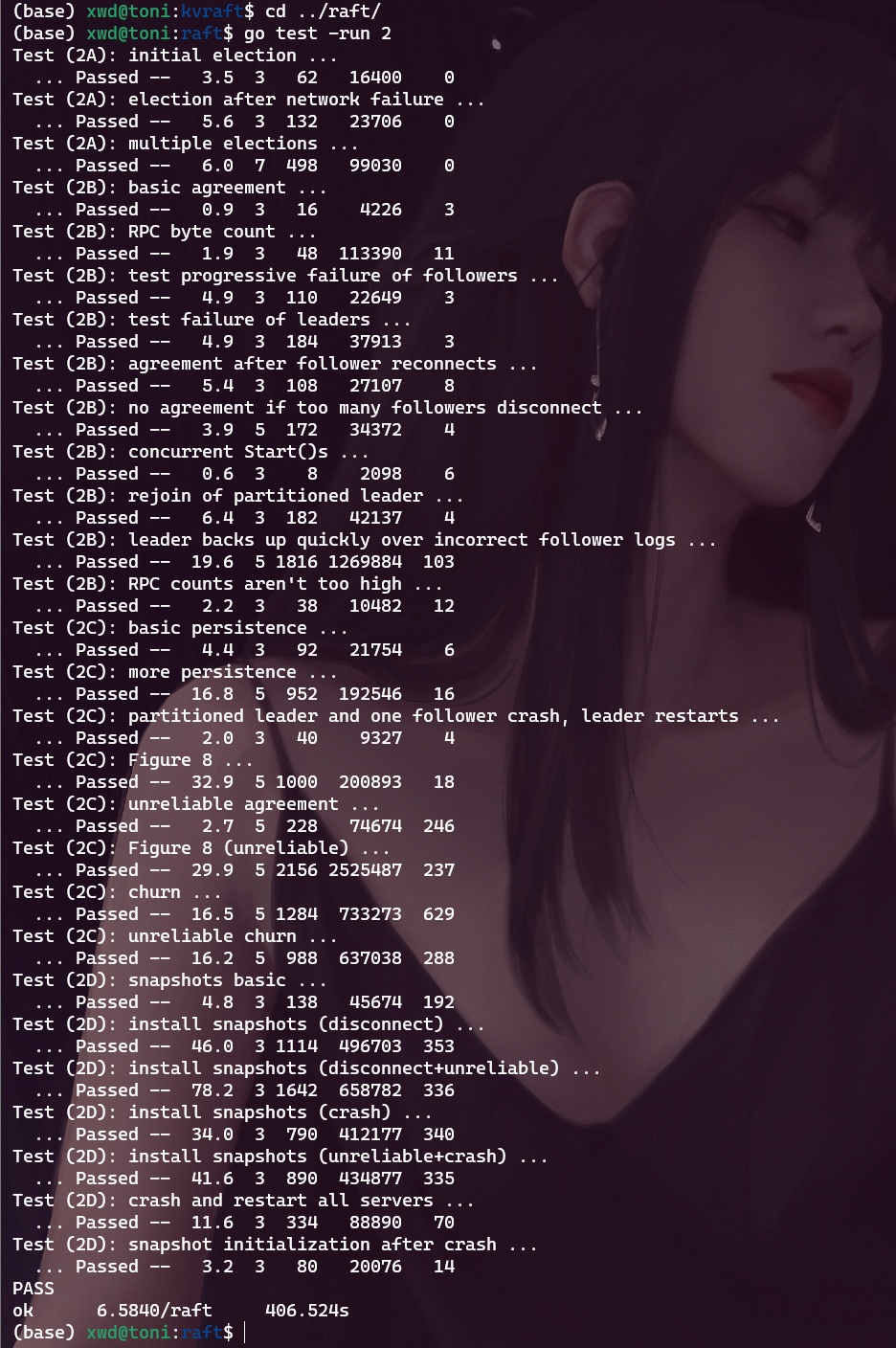
修改后再次测试lab2
1 2 cd ../raft/go test -run 2
结果如下:
该代码经过150次测试没有报错