本文将介绍lab2D部分的实现, lab2D要求实现raft中的快照功能。从个人体验而言, lab2D是目前所有Lab中最难的一个, 各种边界情况层出不穷, debug时看着上千行的debug日志, 一度感到绝望…好在反复调试后终于实现了raft, 还是有点小感动☺️
主要难度在于:
将日志数组截断后, 需要实现全局索引和数组索引之前的转化, 需要考虑更多数组越界的边界条件
在接收InstallSnapshot RPC安装快照后, lastApplied可能已经落后于快照产生时的日志索引, 是无效的日志项, 不应该被应用
由于安装快照后, Leader的nextIndex在回退时可能出现索引越界, 需要考虑边界情况
个人体会是, 本Lab的核心技能是: 一定要学会从日志输出中诊断问题!!!
Lab文档见: https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
我的代码: https://github.com/ToniXWD/MIT6.5840/tree/lab2D
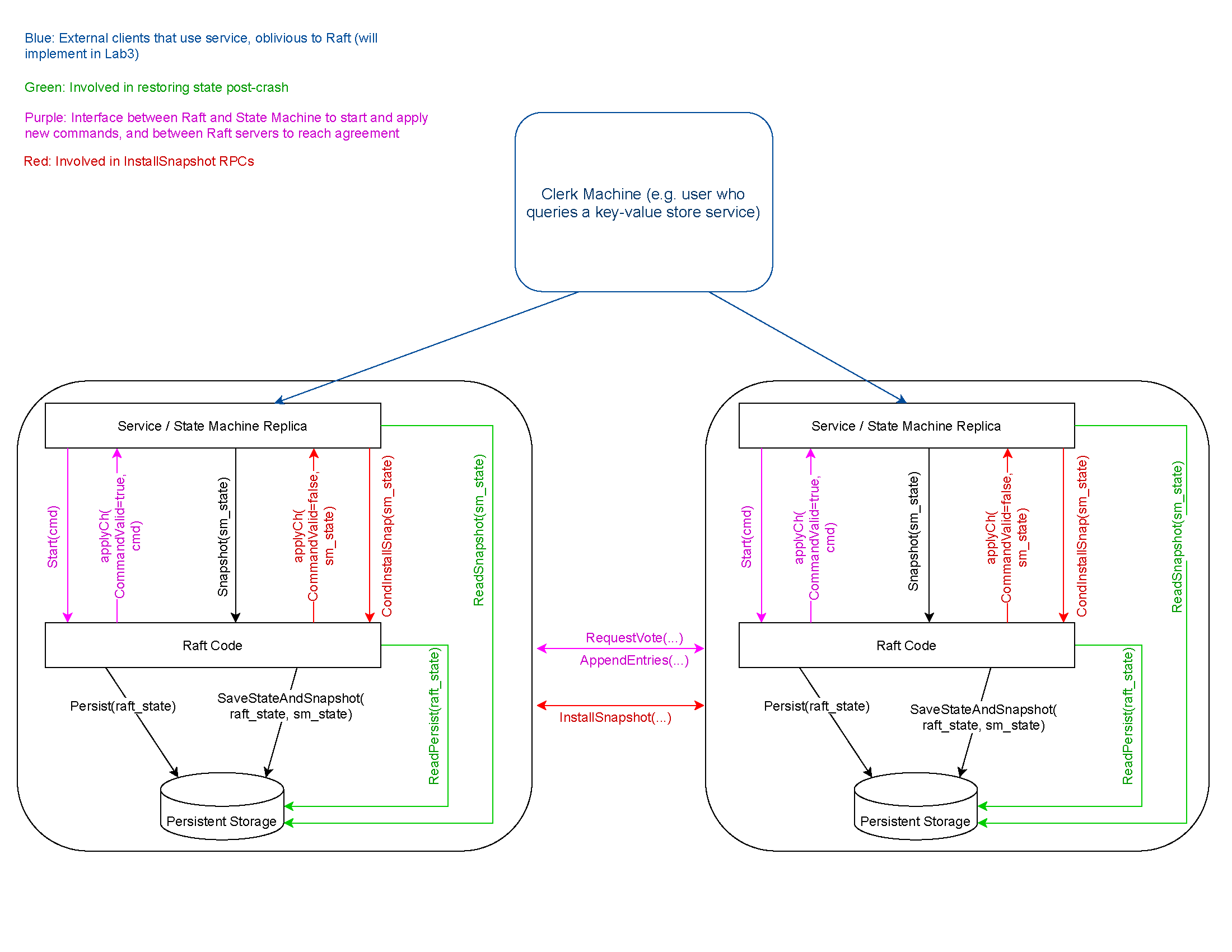
1 代码层级关系梳理 我们需要实现的SnapShot是在raft之上的service层提供的, 因为raft层并不理解所谓的状态机内部状态的机制, 因此有必要了解整个代码的层次结构:
官方的指导书贴心地给出了代码层级的和接口的示意图, 如上。service与raft的交互逻辑如下:
日志复制与应用service, 如Lab3中将实现的KV存储, 位于raft层之上, 通过Start发送命令给Leader一侧的raft层, Leader raft会将日志项复制给集群内的其他Follower raft, Follower raft通过applyCh这个管道将已经提交的包含命令的日志项向上发送给Follower侧的service。
快照请求与传输service为了减小内存压力,将状态机状态封装成一个SnapShot并将请求发送给Leader一侧的raft(Follower侧的sevice也会会存在快照操作), raft层保存SnapShot并截断自己的log数组, 当通过心跳发现Follower的节点的log落后SnapShot时, 通过InstallSnapshot发送给Follower, Follower保存SnapShot并将快照发送给service
持久化存储raft之下还存在一个持久化层Persistent Storage, 也就是Make函数提供的Persister, 调用相应的接口实现持久化存储和读取
2 SnapShot设计 2.1 日志截断和结构体设计 由于发送SnapShot后需要截断日志, 而raft结构体中的字段如commitIndex, lastApplied等, 存储的仍然是全局递增的索引, 由官方的Hint:
Even when the log is trimmed, your implemention still needs to properly send the term and index of the entry prior to new entries in AppendEntries RPCs; this may require saving and referencing the latest snapshot’s lastIncludedTerm/lastIncludedIndex (consider whether this should be persisted).
因此, 在raft结构体中额外增加字段:
1 2 3 4 5 6 type Raft struct { ... snapShot []byte lastIncludedIndex int lastIncludedTerm int }
我将全局真实递增的索引称为Virtual Index, 将log切片使用的索引称为Real Index, 因此如果SnapShot中包含的最高索引: lastIncludedIndex, 转换的函数应该为:
1 2 3 4 5 6 7 8 9 func (rf *Raft) int ) int { return vIdx - rf.lastIncludedIndex } func (rf *Raft) int ) int { return rIdx + rf.lastIncludedIndex }
在以上的转换函数中, 所有有效的日志项索引从1开始, 这与最开始没有日志和持久化数据时的log数组一致:
1 2 3 4 5 6 7 8 func Make (peers []*labrpc.ClientEnd, me int , persister *Persister, applyCh chan ApplyMsg) DPrintf("server %v 调用Make启动" , me) ... rf.log = make ([]Entry, 0 ) rf.log = append (rf.log, Entry{Term: 0 }) ... }
在我之前的Make中, 0索引处需要一个空的日志项占位, 截断日志时, 则使用lastIncludedIndex占位
有了RealLogIdx和VirtualLogIdx, 我的代码将遵循以下的规则 :
访问rf.log一律使用真实的切片索引, 即Real Index
其余情况, 一律使用全局真实递增的索引Virtual Index
设计完成这两个函数后, 修改所有代码中对索引的操作, 调用RealLogIdx将Virtual Index转化为Real Index, 或调用VirtualLogIdx将Real Index转化为Virtual Index, 由于涉及代码太多且并不复杂, 此处不贴代码, 可以参考仓库
2.2 Snapshot函数设计 Snapshot很简单, 接收service层的快照请求, 并截断自己的log数组, 但还是有几个点需要说明:
判断是否接受Snapshot
创建Snapshot时, 必须保证其index小于等于commitIndex, 如果index大于commitIndex, 则会有包括未提交日志项的风险。快照中不应包含未被提交的日志项
创建Snapshot时, 必须保证其index小于等于lastIncludedIndex, 因为这可能是一个重复的或者更旧的快照请求RPC, 应当被忽略
将snapshot保存Follower可能需要snapshot, 以及持久化时需要找到snapshot进行保存, 因此此时要保存以便后续发送给Follower
除了更新lastIncludedTerm和lastIncludedIndex外, 还需要检查lastApplied是否位于Snapshot之前, 如果是, 需要调整到与index一致
调用persist持久化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (rf *Raft) int , snapshot []byte ) { rf.mu.Lock() defer rf.mu.Unlock() if rf.commitIndex < index || index <= rf.lastIncludedIndex { DPrintf("server %v 拒绝了 Snapshot 请求, 其index=%v, 自身commitIndex=%v, lastIncludedIndex=%v\n" , rf.me, index, rf.commitIndex, rf.lastIncludedIndex) return } DPrintf("server %v 同意了 Snapshot 请求, 其index=%v, 自身commitIndex=%v, 原来的lastIncludedIndex=%v, 快照后的lastIncludedIndex=%v\n" , rf.me, index, rf.commitIndex, rf.lastIncludedIndex, index) rf.snapShot = snapshot rf.lastIncludedTerm = rf.log[rf.RealLogIdx(index)].Term rf.log = rf.log[rf.RealLogIdx(index):] rf.lastIncludedIndex = index if rf.lastApplied < index { rf.lastApplied = index } rf.persist() }
2.3 相关持久化函数 2.3.1 persist函数 添加快照后, 调用persist时还需要编码额外的字段lastIncludedIndex和lastIncludedTerm, 在调用Save函数时需要传入快照rf.snapShot
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func (rf *Raft) w := new (bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(rf.votedFor) e.Encode(rf.currentTerm) e.Encode(rf.log) e.Encode(rf.lastIncludedIndex) e.Encode(rf.lastIncludedTerm) raftstate := w.Bytes() rf.persister.Save(raftstate, rf.snapShot) }
2.3.2 读取持久化状态和快照 readPersist和readSnapshot分别读取持久化状态和快照:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 func (rf *Raft) byte ) { if len (data) == 0 { return } r := bytes.NewBuffer(data) d := labgob.NewDecoder(r) var votedFor int var currentTerm int var log []Entry var lastIncludedIndex int var lastIncludedTerm int if d.Decode(&votedFor) != nil || d.Decode(¤tTerm) != nil || d.Decode(&log) != nil || d.Decode(&lastIncludedIndex) != nil || d.Decode(&lastIncludedTerm) != nil { DPrintf("server %v readPersist failed\n" , rf.me) } else { rf.votedFor = votedFor rf.currentTerm = currentTerm rf.log = log rf.lastIncludedIndex = lastIncludedIndex rf.lastIncludedTerm = lastIncludedTerm rf.commitIndex = lastIncludedIndex rf.lastApplied = lastIncludedIndex DPrintf("server %v readPersist 成功\n" , rf.me) } } func (rf *Raft) byte ) { if len (data) == 0 { DPrintf("server %v 读取快照失败: 无快照\n" , rf.me) return } rf.snapShot = data DPrintf("server %v 读取快照c成功\n" , rf.me) }
由于目前尽在Make函数中调用这两个函数, 此时没有协程在执行, 因此不需要加锁, 需要额外注意的是:
1 2 rf.commitIndex = lastIncludedIndex rf.lastApplied = lastIncludedIndex
此操作保证了commitIndex和lastApplied的下限, 因为快照包含的索引一定是被提交和应用的, 此操作可以避免后续的索引越界问题
2.3.3 Make函数修改 由于初始化状态时, 索引需要变为Virtual Index, 因此需要借助读取的持久化状态, 代码修改如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func Make (peers []*labrpc.ClientEnd, me int , persister *Persister, applyCh chan ApplyMsg) ... rf := &Raft{} rf.peers = peers rf.persister = persister rf.me = me rf.log = make ([]Entry, 0 ) rf.log = append (rf.log, Entry{Term: 0 }) rf.nextIndex = make ([]int , len (peers)) rf.matchIndex = make ([]int , len (peers)) ... rf.readSnapshot(persister.ReadSnapshot()) rf.readPersist(persister.ReadRaftState()) for i := 0 ; i < len (rf.nextIndex); i++ { rf.nextIndex[i] = rf.VirtualLogIdx(len (rf.log)) } ... }
如果日志和持久化存储为空, 则readSnapshot和readPersist无作用, 初始化过程和以往相同
3 InstallSnapshot RPC设计 3.1 RPC结构体设计 先贴上原论文的描述图
根据图中的描述, 设计RPC结构体如下:
1 2 3 4 5 6 7 8 9 10 11 12 type InstallSnapshotArgs struct { Term int LeaderId int LastIncludedIndex int LastIncludedTerm int Data []byte LastIncludedCmd interface {} } type InstallSnapshotReply struct { Term int }
注意, 由于我的设计中, log数据组索引从1开始, 0索引需要LastIncludedIndex位置的日志项进行占位, 因此我在InstallSnapshotArgs中额外添加了LastIncludedCmd字段以补全这个占位用的日志项
3.2 InstallSnapshot RPC发起端设计 3.2.1 InstallSnapshot RPC发送时机 阅读论文可知, 当Leader发现Follower要求回退的日志已经被SnapShot截断时, 需要发生InstallSnapshot RPC, 在我设计的代码中, 以下2个场景会出现:
3.2.1.1 心跳发送函数发起 SendHeartBeats发现PrevLogIndex < lastIncludedIndex, 表示其要求的日志项已经被截断, 需要改发送心跳为发送InstallSnapshot RPC
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 func (rf *Raft) ... for !rf.killed() { ... for i := 0 ; i < len (rf.peers); i++ { ... args := &AppendEntriesArgs{ Term: rf.currentTerm, LeaderId: rf.me, PrevLogIndex: rf.nextIndex[i] - 1 , LeaderCommit: rf.commitIndex, } sendInstallSnapshot := false if args.PrevLogIndex < rf.lastIncludedIndex { DPrintf("leader %v 取消向 server %v 广播新的心跳, 改为发送sendInstallSnapshot, lastIncludedIndex=%v, nextIndex[%v]=%v, args = %+v \n" , rf.me, i, rf.lastIncludedIndex, i, rf.nextIndex[i], args) sendInstallSnapshot = true } else if rf.VirtualLogIdx(len (rf.log)-1 ) > args.PrevLogIndex { args.Entries = rf.log[rf.RealLogIdx(args.PrevLogIndex+1 ):] DPrintf("leader %v 开始向 server %v 广播新的AppendEntries, lastIncludedIndex=%v, nextIndex[%v]=%v, args = %+v\n" , rf.me, i, rf.lastIncludedIndex, i, rf.nextIndex[i], args) } else { DPrintf("leader %v 开始向 server %v 广播新的心跳, lastIncludedIndex=%v, nextIndex[%v]=%v, args = %+v \n" , rf.me, i, rf.lastIncludedIndex, i, rf.nextIndex[i], args) args.Entries = make ([]Entry, 0 ) } if sendInstallSnapshot { go rf.handleInstallSnapshot(i) } else { args.PrevLogTerm = rf.log[rf.RealLogIdx(args.PrevLogIndex)].Term go rf.handleAppendEntries(i, args) } } ... } }
3.2.1.2 心跳回复处理函数发起 handleAppendEntries检查心跳(和AppendEntries是一致的)RPC的回复, 并进行相应的回退, 如果发现已经回退到lastIncludedIndex还不能满足要求, 就需要发送InstallSnapshot RPC:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 func (rf *Raft) int , args *AppendEntriesArgs) { ... if reply.Term == rf.currentTerm && rf.role == Leader { if reply.XTerm == -1 { DPrintf("leader %v 收到 server %v 的回退请求, 原因是log过短, 回退前的nextIndex[%v]=%v, 回退后的nextIndex[%v]=%v\n" , rf.me, serverTo, serverTo, rf.nextIndex[serverTo], serverTo, reply.XLen) if rf.lastIncludedIndex >= reply.XLen { go rf.handleInstallSnapshot(serverTo) } else { rf.nextIndex[serverTo] = reply.XLen } return } i := rf.nextIndex[serverTo] - 1 if i < rf.lastIncludedIndex { i = rf.lastIncludedIndex } for i > rf.lastIncludedIndex && rf.log[rf.RealLogIdx(i)].Term > reply.XTerm { i -= 1 } if i == rf.lastIncludedIndex && rf.log[rf.RealLogIdx(i)].Term > reply.XTerm { go rf.handleInstallSnapshot(serverTo) } else if rf.log[rf.RealLogIdx(i)].Term == reply.XTerm { DPrintf("leader %v 收到 server %v 的回退请求, 冲突位置的Term为%v, server的这个Term从索引%v开始, 而leader对应的最后一个XTerm索引为%v, 回退前的nextIndex[%v]=%v, 回退后的nextIndex[%v]=%v\n" , rf.me, serverTo, reply.XTerm, reply.XIndex, i, serverTo, rf.nextIndex[serverTo], serverTo, i+1 ) rf.nextIndex[serverTo] = i + 1 } else { DPrintf("leader %v 收到 server %v 的回退请求, 冲突位置的Term为%v, server的这个Term从索引%v开始, 而leader对应的XTerm不存在, 回退前的nextIndex[%v]=%v, 回退后的nextIndex[%v]=%v\n" , rf.me, serverTo, reply.XTerm, reply.XIndex, serverTo, rf.nextIndex[serverTo], serverTo, reply.XIndex) if reply.XIndex <= rf.lastIncludedIndex { go rf.handleInstallSnapshot(serverTo) } else { rf.nextIndex[serverTo] = reply.XIndex } } return } }
这里会有3个情况触发发送InstallSnapshot RPC:
Follower的日志过短(PrevLogIndex这个位置在Follower中不存在), 甚至短于lastIncludedIndexFollower的日志在PrevLogIndex这个位置发生了冲突, 回退时发现即使到了lastIncludedIndex也找不到匹配项(大于或小于这个Xterm)nextIndex中记录的索引本身就小于lastIncludedIndex
前2个情况很容易想到, 但第3个情况容易被忽视(单次运行测例很容易测不出这种情况, 需要多次运行测例)
3.2.2 InstallSnapshot发送 这里的实现相对简单, 只要构造相应的请求结构体即可, 但需要注意:
需要额外发生Cmd字段, 因为构造0索引时的占位日志项, 尽管其已经被包含在了快照中
发送RPC时不要持有锁
发送成功后, 需要将nextIndex设置为VirtualLogIdx(1), 因为0索引处是占位, 其余的部分已经不需要再发送了
和心跳一样, 需要根据回复检查自己是不是旧Leader1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 func (rf *Raft) int ) { reply := &InstallSnapshotReply{} rf.mu.Lock() if rf.role != Leader { rf.mu.Unlock() return } args := &InstallSnapshotArgs{ Term: rf.currentTerm, LeaderId: rf.me, LastIncludedIndex: rf.lastIncludedIndex, LastIncludedTerm: rf.lastIncludedTerm, Data: rf.snapShot, LastIncludedCmd: rf.log[0 ].Cmd, } rf.mu.Unlock() ok := rf.sendInstallSnapshot(serverTo, args, reply) if !ok { return } rf.mu.Lock() defer func () rf.mu.Unlock() }() if reply.Term > rf.currentTerm { rf.currentTerm = reply.Term rf.role = Follower rf.votedFor = -1 rf.ResetTimer() rf.persist() return } rf.nextIndex[serverTo] = rf.VirtualLogIdx(1 ) }
3.2.3 InstallSnapshot响应 InstallSnapshot响应需要考虑更多的边界情况:
如果是旧leader, 拒绝
如果Term更大, 证明这是新的Leader, 需要更改自身状态, 但不影响继续接收快照
如果LastIncludedIndex位置的日志项存在, 即尽管需要创建快照, 但并不导致自己措施日志项, 只需要截断日志数组即可
如果LastIncludedIndex位置的日志项不存在, 需要清空切片, 并将0位置构造LastIncludedIndex位置的日志项进行占位
需要检查lastApplied和commitIndex 是否小于LastIncludedIndex, 如果是, 更新为LastIncludedIndex
完成上述操作后, 需要将快照发送到service层
由于InstallSnapshot可能是替代了一次心跳函数, 因此需要重设定时器
第5, 7点最容易被忽略, 因此代码里需要提供足够的日志信息来协助debug
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 func (rf *Raft) rf.mu.Lock() defer func () rf.ResetTimer() rf.mu.Unlock() DPrintf("server %v 接收到 leader %v 的InstallSnapshot, 重设定时器" , rf.me, args.LeaderId) }() if args.Term < rf.currentTerm { reply.Term = rf.currentTerm DPrintf("server %v 拒绝来自 %v 的 InstallSnapshot, 更小的Term\n" , rf.me, args.LeaderId) return } if args.Term > rf.currentTerm { rf.currentTerm = args.Term rf.votedFor = -1 DPrintf("server %v 接受来自 %v 的 InstallSnapshot, 且发现了更大的Term\n" , rf.me, args.LeaderId) } rf.role = Follower hasEntry := false rIdx := 0 for ; rIdx < len (rf.log); rIdx++ { if rf.VirtualLogIdx(rIdx) == args.LastIncludedIndex && rf.log[rIdx].Term == args.LastIncludedTerm { hasEntry = true break } } msg := &ApplyMsg{ SnapshotValid: true , Snapshot: args.Data, SnapshotTerm: args.LastIncludedTerm, SnapshotIndex: args.LastIncludedIndex, } if hasEntry { DPrintf("server %v InstallSnapshot: args.LastIncludedIndex= %v 位置存在, 保留后面的log\n" , rf.me, args.LastIncludedIndex) rf.log = rf.log[rIdx:] } else { DPrintf("server %v InstallSnapshot: 清空log\n" , rf.me) rf.log = make ([]Entry, 0 ) rf.log = append (rf.log, Entry{Term: rf.lastIncludedTerm, Cmd: args.LastIncludedCmd}) } rf.snapShot = args.Data rf.lastIncludedIndex = args.LastIncludedIndex rf.lastIncludedTerm = args.LastIncludedTerm if rf.commitIndex < args.LastIncludedIndex { rf.commitIndex = args.LastIncludedIndex } if rf.lastApplied < args.LastIncludedIndex { rf.lastApplied = args.LastIncludedIndex } reply.Term = rf.currentTerm rf.applyCh <- *msg rf.persist() }
4 其他边界情况与bug修复 4.1 并发优化 这里指的并发优化专指CommitChecker函数, 这个函数是单独的一个协程运行, 不断地将需要应用的日志发送到应用层。
但在我完成前3节的任务后, 运行测例发现最基本的TestSnapshotBasic2D出现了永久运行但不成功输出结果情况, 观察日志后发现,Snapshot函数获永久地阻塞在获取锁的代码上, 而上一个获取锁的函数正是CommitChecker函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func (rf *Raft) for !rf.killed() { rf.mu.Lock() for rf.commitIndex <= rf.lastApplied { rf.condApply.Wait() } for rf.commitIndex > rf.lastApplied { rf.lastApplied += 1 msg := &ApplyMsg{ CommandValid: true , Command: rf.log[rf.lastApplied].Cmd, CommandIndex: rf.lastApplied, } rf.applyCh <- *msg } rf.mu.Unlock() } }
观察代码可知, 原来的实现中, 将commitIndex和lastApplied之间的所有日志项发送到applyCh进行应用时, 全阶段都是持有锁的状态, 而applyCh通道可能长时间阻塞, 因此出现了上述的死锁 现象。
解决方案是,先将要发送的msg缓存到一个切片后, 然后释放锁以避免死锁, 再发送到applyCh中, 因此不难写出下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (rf *Raft) for !rf.killed() { rf.mu.Lock() for rf.commitIndex <= rf.lastApplied { rf.condApply.Wait() } msgBuf := make ([]*ApplyMsg, 0 , rf.commitIndex-rf.lastApplied) for rf.commitIndex > rf.lastApplied { rf.lastApplied += 1 msg := &ApplyMsg{ CommandValid: true , Command: rf.log[rf.RealLogIdx(rf.lastApplied)].Cmd, CommandIndex: rf.lastApplied, } msgBuf = append (msgBuf, msg) } rf.mu.Unlock() for _, msg := range msgBuf { rf.applyCh <- *msg } } }
这个代码看齐来没有问题, 但是实际运行测例时发现, 仍然会出现与预期不一样的要apply的日志项, 原因在于高并发场景下, 执行rf.mu.Unlock()释放锁后, 可能切换到了InstallSnapshot响应函数, 并更新了lastApplied, 这也意味着, 之后发送到applyCh要应用的日志项已经包含在了快照中, 再次应用这个已经包含在了快照中的日志项是不合理的, 因此还需要再次进行检查:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 func (rf *Raft) for !rf.killed() { rf.mu.Lock() for rf.commitIndex <= rf.lastApplied { rf.condApply.Wait() } msgBuf := make ([]*ApplyMsg, 0 , rf.commitIndex-rf.lastApplied) tmpApplied := rf.lastApplied for rf.commitIndex > tmpApplied { tmpApplied += 1 if tmpApplied <= rf.lastIncludedIndex { continue } msg := &ApplyMsg{ CommandValid: true , Command: rf.log[rf.RealLogIdx(tmpApplied)].Cmd, CommandIndex: tmpApplied, SnapshotTerm: rf.log[rf.RealLogIdx(tmpApplied)].Term, } msgBuf = append (msgBuf, msg) } rf.mu.Unlock() for _, msg := range msgBuf { rf.mu.Lock() if msg.CommandIndex != rf.lastApplied+1 { rf.mu.Unlock() continue } DPrintf("server %v 准备commit, log = %v:%v, lastIncludedIndex=%v" , rf.me, msg.CommandIndex, msg.SnapshotTerm, rf.lastIncludedIndex) rf.mu.Unlock() rf.applyCh <- *msg rf.mu.Lock() if msg.CommandIndex != rf.lastApplied+1 { rf.mu.Unlock() continue } rf.lastApplied = msg.CommandIndex rf.mu.Unlock() } } }
以上这个代码在发送消息后再次检查了lastApplied, 对于通过测例已经没有问题了, 但还是存在这样的问题:rf.applyCh <- *msg 执行之前,即在 rf.mu.Unlock() 与 rf.applyCh <- *msg 之间的时间窗口内,发生了接收快照的操作,导致 rf.lastApplied 被修改,那么 msg 可能就不再是应该应用的消息。对于这个问题, 持有锁发送能保证线程安全, 但实际上会导致死锁, 目前这个潜在的bug暂且搁置…
4.2 新Leader的初始化 新Leader需要对nextIndex和matchIndex进行如下初始化:
1 2 3 4 for i := 0 ; i < len (rf.nextIndex); i++ { rf.nextIndex[i] = rf.VirtualLogIdx(len (rf.log)) rf.matchIndex[i] = rf.lastIncludedIndex }
因为lastIncludedIndex保证不高于commitIndex, 因此其matchIndex至少设置为matchIndex是合理的, 这会加速正确的commitIndex的恢复
4.3 常见数组索引越界原因 在我调试代码的过程中, 发现了很多次数组索引越界, 而且写代码时很多数组索引越界的原因并没有记录在git commit中, 因此无法逐一提及, (自己也忘了 ), 但索引越界的原因大多是差不多的, 总结如下:
快照接收时, 没有检查commitIndex
快照接收时, 没有检查lastApplied
没有进行索引转化
没有设置lastIncludedIndex为for循环的下限, 例如确定N时的for循环
新的Leader没有使用索引转化进行nextIndex和matchIndex的初始化
5 测试 5.1 常规测试
如果使用 -race的话需要注释掉所有的DPrintf, 因为在输出日志时并没有仔细考虑线程同步的问题, 可能引起数据竞争, 除DPrintf的其他的部分我自己检查是不存在数据竞争的
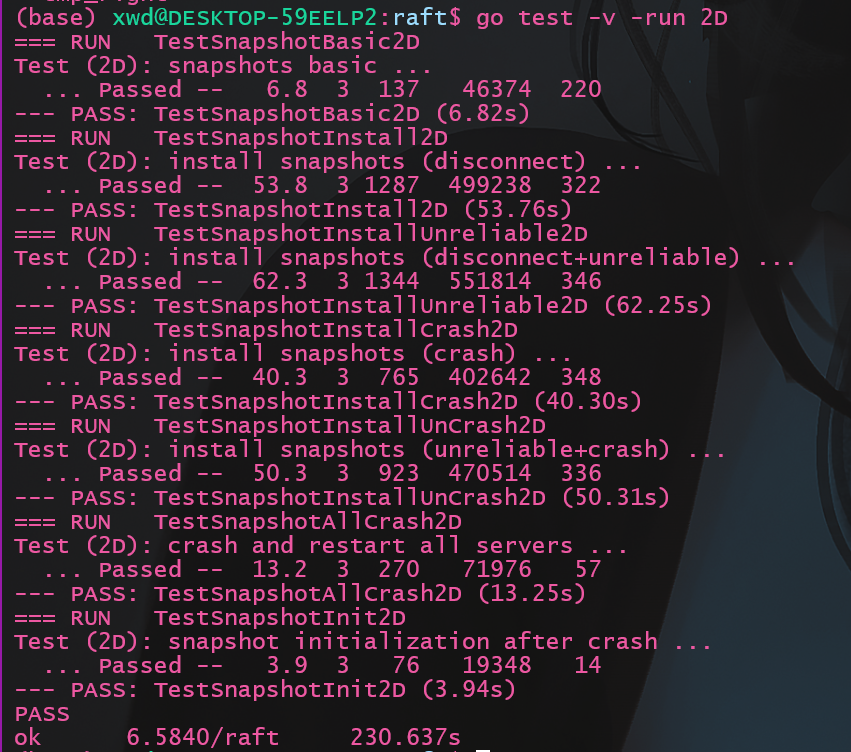
执行测试命令
结果如下:
用时230s, 快于官方的293s, 还可以
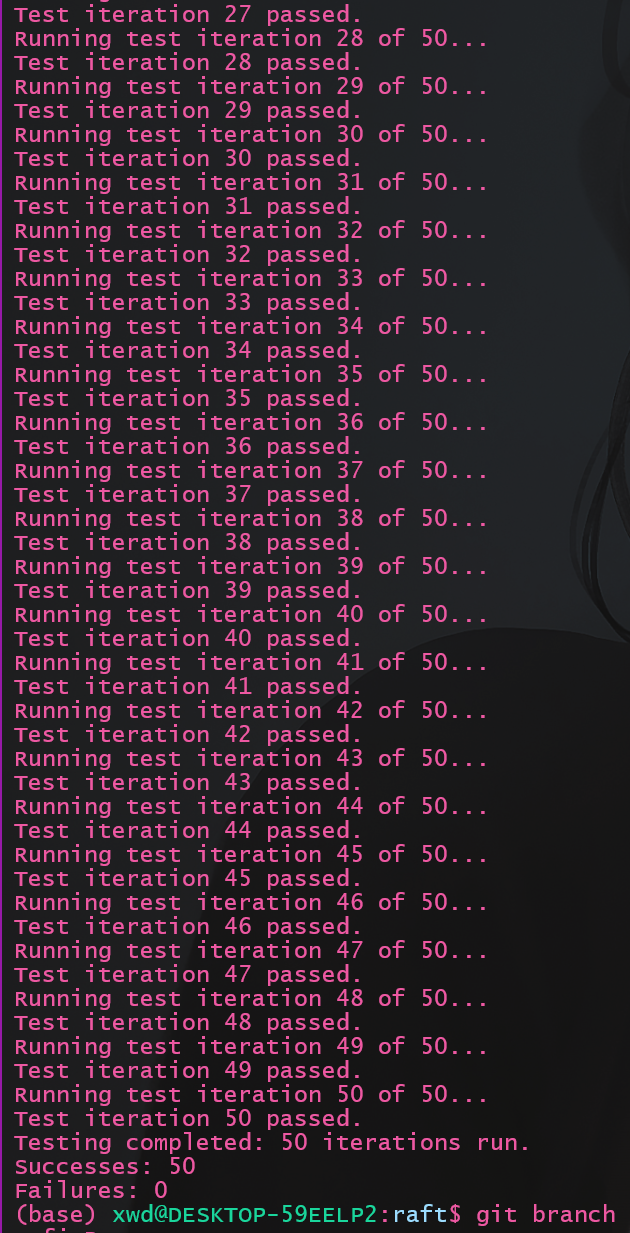
5.2 多次测试 raft的许多特性导致其一次测试并不准确, 有些bug需要多次测试才会出现, 编写如下脚本命名为manyTest_2D.sh:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 # !/bin/bash # 初始化计数器 count=0 success_count=0 fail_count=0 # 设置测试次数 max_tests=50 for ((i=1; i<=max_tests; i++)) do echo "Running test iteration $i of $max_tests..." # 运行 go 测试命令 go test -v -run 2D &> output2D.log # 检查 go 命令的退出状态 if [ "$?" -eq 0 ]; then # 测试成功 success_count=$((success_count+1)) echo "Test iteration $i passed." # 如果想保存通过的测试日志,取消下面行的注释 # mv output2D.log "success_$i.log" else # 测试失败 fail_count=$((fail_count+1)) echo "Test iteration $i failed, check 'failure2D_$i.log' for details." mv output2D.log "failure2D_$i.log" fi done # 报告测试结果 echo "Testing completed: $max_tests iterations run." echo "Successes: $success_count" echo "Failures: $fail_count"
再次进行测试:
结果:
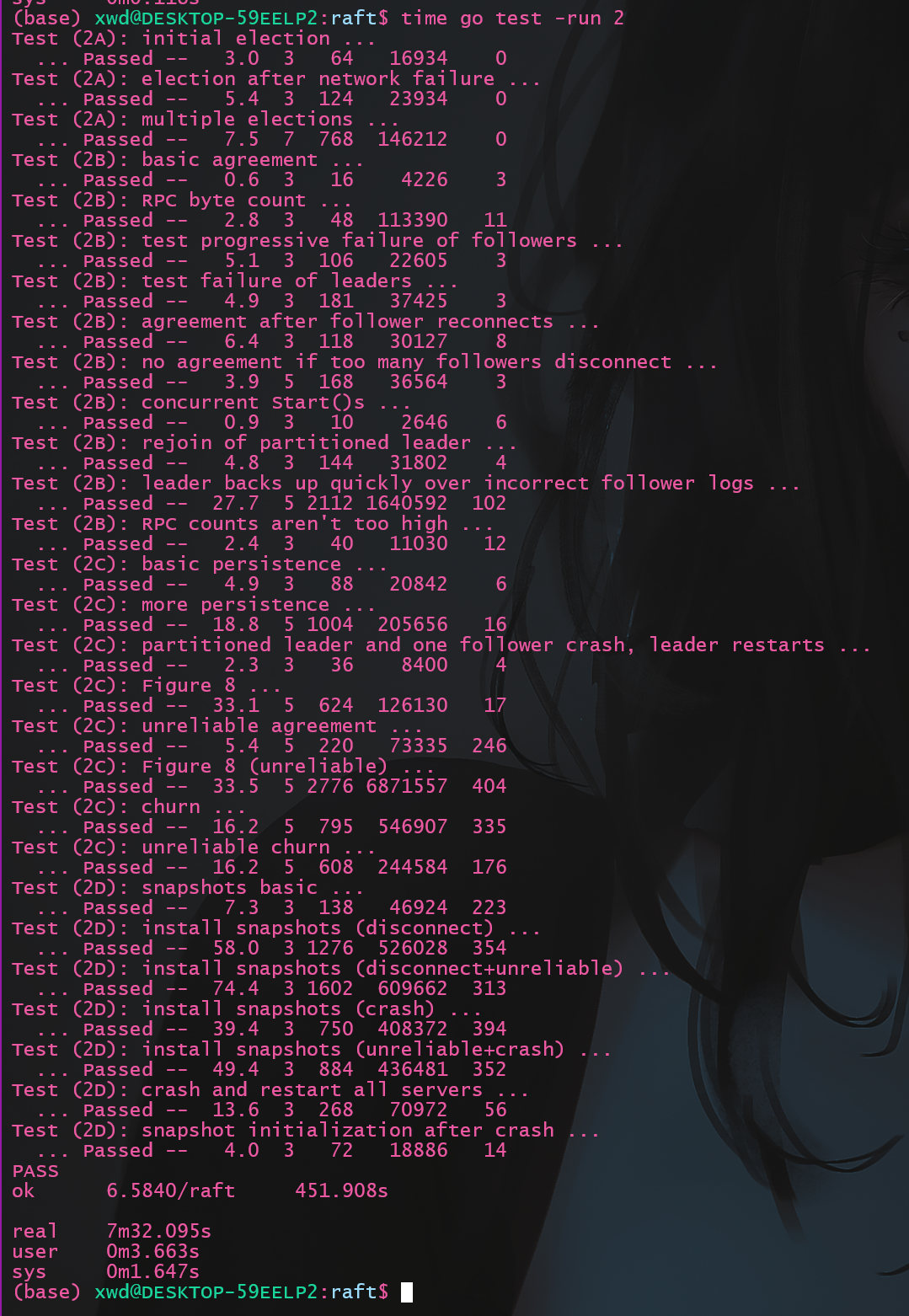
5.3 lab2完整测试 执行测试命令
结果如下:
耗时444s, 和文档要求的6分钟da
6 lab2总结 lab2是一个相对庞大且复杂的实验, 难度相对lab1大很多, 而且lab2需要考虑的边界条件更多, 并发场景更加复杂。
复杂的并发场景raft的过程中, 代码语法方面的错误是相对容易debug的, 但难以debug是忽略高并发场景下各种边界条件处理的逻辑bug
阅读原论文的重要性raft时, 吃透论文是十分重要的, 我在做lab前通读了一遍论文, 有些细节不太理解, 做lab过程中还再次阅读了论文
日志调试的重要性bug最有效的方法, 日志输出应当详略得当, 提供有效信息而忽略一些垃圾信息, 比如我是在加锁时输出日志才定位到了CommitChecker函数的死锁问题, 此时需要关闭其他如心跳的无关输出以避免日志混乱
终于从头到尾实现了raft, 尽管性能也就那样, 自己的代码还是写得太乱, 但成就感还是满满的!