本文将介绍lab2C部分的实现, lab2C要求实现raft中的持久化功能, 相比lab2A,和lab2B, 本节的难度其实很小, 但复杂的是lab2A,和lab2B中的一些微小的bug会在2C中显现, 并且相对不太容易注意到。
Lab文档见: https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
我的代码: https://github.com/ToniXWD/MIT6.5840/tree/lab2C
1 bug修复:重复的RPC
在之前的AppendEntries中有这样的代码:
1 | if len(args.Entries) != 0 && len(rf.log) > args.PrevLogIndex+1 && rf.log[args.PrevLogIndex+1].Term != args.Entries[0].Term { |
这段代码所做的事情是, 如果将要追加的位置存在日志项, 且日志项与RPC中的日子切片的第一个发生冲突(Term不匹配), 则将冲突位置及其之后的日志项清除掉。
这段代码看起来没有问题,但在高并发的场景下,会存在如下问题:
Leader先发送了AppendEntries RPC, 我们记为RPC1Follower收到RPC1, 发生上述代码描述的冲突, 将冲突部分的内容清除, 并追加RPC1中的日志切片- 由于并发程度高,
Leader在RPC1没有收到回复时又发送了下一个AppendEntries RPC, 由于nextIndex和matchIndex只有在收到回复后才会修改, 因此这个新的AppendEntries RPC, 我们记为RPC2, 与RPC1是一致的 Follower收到RPC2, 由于RPC2和RPC1完全相同, 因此其一定不会发生冲突, 结果是Follower将相同的一个日志项切片追加了2次!
在考虑另一个场景:
Leader先发送了AppendEntries RPC, 我们记为RPC1- 由于网络问题,
RPC1没有即时到达Follower Leader又追加了新的log, 此时又发送了AppendEntries RPC, 我们记为RPC2- 由于网络问题, 后发送的
RPC2先到达Follower,Follower把RPC2的日志项追加 - 此时
RPC1到达了Follower,Follower把RPC1的日志项强行追加时将导致log被缩短
解决方案:
也就是说, 除了考虑冲突外, 还需要考虑重复的RPC以及顺序颠倒的RPC, 因此需要检查每个位置的log是否匹配, 不匹配就覆盖, 否则不做更改。
这样对于重复的RPC就不会重复追加, 并且如果RPC顺序颠倒,也就是让Leader多通过一次心跳同步
1 | for idx, log := range args.Entries { |
这里的bug是完成
lab3后才发现的bug,lab2分支的代码还没有进行这样的修改也能通过测例。原因是在我的设计中,Start并没有立即广播心跳, 因此不会存在RPC顺序颠倒的情况, 如果想看最新的代码修改, 参见: https://github.com/ToniXWD/MIT6.5840/blob/lab3A/src/raft/raft.go#L606
2 优化: 快速回退
在之前的回退实现中, 如果有Follower的日志不匹配, 每次RPC中, Leader会将其nextIndex自减1来重试, 但其在某些情况下会导致效率很低, 因此需要AppendEntries RPC的回复信息携带更多的字段以加速回退, 核心思想就是:Follower返回更多信息给Leader,使其可以以Term为单位来回退
教授在课堂上已经介绍了快速回退的实现机制, 可以看我整理的笔记
我的实现和课堂的介绍基本一致, 只是将XLen从空白的Log槽位数改为Log的长度:
2.1 结构体定义
1 | type AppendEntriesReply struct { |
2.2 Follower侧的AppendEntries
发现冲突时, 回复的逻辑为:
- 如果
PrevLogIndex位置不存在日志项, 通过设置reply.XTerm = -1告知Leader, 并将reply.XLen设置为自身日志长度 - 如果
PrevLogIndex位置日志项存在但Term冲突, 通过reply.XTerm和reply.XIndex分别告知冲突位置的Term和这个Term在Follower中第一次出现的位置
具体代码如下:
1 | func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) { |
2.3 leader侧的handleAppendEntries
如果需要回退, leader的处理逻辑是:
- 如果
XTerm == -1, 表示PrevLogIndex位置在Follower中不存在log, 需要将nextIndex设置为Follower的log长度即XLen - 如果
XTerm != -1, 表示PrevLogIndex位置在Follower中存在log但其Term为XTerm, 与prevLogTerm不匹配, 同时XIndex表示这个Term在Follower中第一次出现的位置, 需要如下进行判断:- 如果
Follower中存在XTerm, 将nextIndex设置为Follower中最后一个term == XTerm的日志项的下一位 - 否则, 将
nextIndex设置为XIndex
- 如果
具体代码为:
1 | func (rf *Raft) handleAppendEntries(serverTo int, args *AppendEntriesArgs) { |
3 持久化
持久化的内容只包括: votedFor, currentTerm, log, 为什么只需要持久化这三个变量, 也可以参考课堂笔记
3.1 持久化函数
persist函数和readPersist函数很简单, 只需要根据注释的提示完成即可:
1 | func (rf *Raft) persist() { |
3.2 持久化位置
lab的持久化方案很粗糙, 只要修改了votedFor, currentTerm, log中的任意一个, 则进行持久化, 因此只需要在相应位置调用persist即可, 这里旧不给出代码了, 感兴趣可以直接看我提供的仓库。
特别需要说明的是,当崩溃恢复时,其调用的函数仍然是Make函数, 而nextIndex需要在执行了readPersist后再初始化, 因为readPersist修改了log, 而nextIndex需初始化为log长度
3.3 持久化时是否需要锁?
按照我的理解, 持久化时不需要锁保护log, 原因如下:
Leader视角Leader永远不会删除自己的log(此时没有快照), 因此不需要锁保护Follower视角
尽管Follower可能截断log, 但永远不会截断在commit的log之前, 而持久化只需要保证已经commit的log, 因此也不需要锁
4 测试
4.1 常规测试
2B测试
由于我们实现了快速回退, 此时可以测试2B, 看看是否速度有显著提升:
执行测试命令结果如下:1
go test -v -run 2B
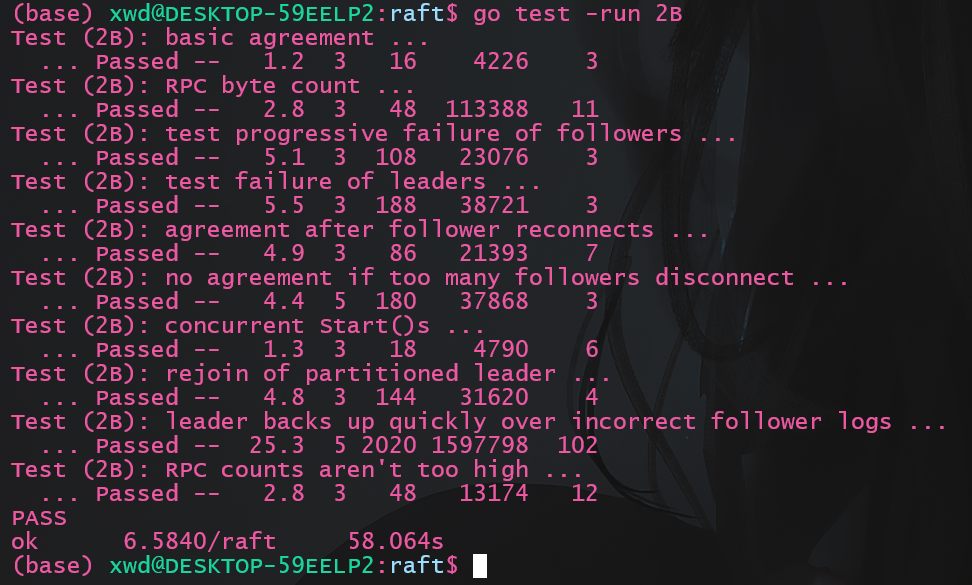
相比于之前快了15s左右, 勉勉强强满足了任务书中的一份子以内… 看了实现还是不够精妙啊
2C测试
执行测试命令结果如下:1
go test -v -run 2C
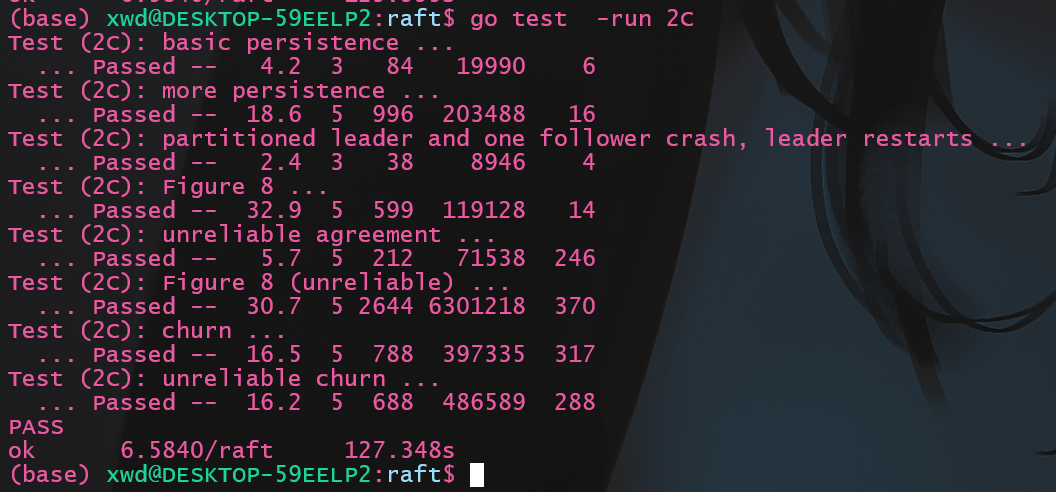
比官方的示例满了4s, 还不错
4.2 多次测试
raft的许多特性导致其一次测试并不准确, 有些bug需要多次测试才会出现, 编写如下脚本命名为manyTest_2B.sh:
1 | !/bin/bash |
再次进行测试:
1 | ./manyTest_2C.sh |
结果: