本文将介绍lab2B部分的实现, lab2B要求实现raft中的日志复制和提交两部分的内容, 相比lab2A, lab2B的Hint更少, 难度也相对较大。
Lab文档见: https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
我的2A部分的实现在这里
我的代码:
- 时间戳实现: https://github.com/ToniXWD/MIT6.5840/tree/lab2B
- timer实现: https://github.com/ToniXWD/MIT6.5840/tree/lab2B-timer
1 2A部分的bug修复
1.1 修复孤立节点被选举的bug
- 问题追溯
2A部分中,RequestVote中允许投票的判断我的实现是这样的:在调试1
2
3
4
5
6
7if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
// 首先确保是没投过票的
if args.Term > rf.currentTerm ||
(args.LastLogIndex >= len(rf.log)-1 && args.LastLogTerm >= rf.log[len(rf.log)-1].Term) {
...
}
}2B的时候, 遇到了已经committed的信息丢失的问题, 问题就在于上述的代码, 其判断统一投票的逻辑为:
- 首先要求其没有投过票或者投票对象就是这个
RPC请求发起者 - 如果
args.Term > rf.currentTerm投票, 也就是投票者有更新的term - 如果
term相同, 则只有请求者的log至少和自己一样长, 并且LastLogTerm也至少和自己的最后一个log的term一样新, 才投票
这样的实现会导致以下的情况:
- 某一时刻一个
server网络出现了问题(称其为S), 其自增currentTerm后发出选举, 经过多次选举超时后其currentTerm已经远大于离开集群时的currentTerm - 后来网络恢复了正常, 这时其他的服务器收到了
S的选举请求, 这个选举请求有更新的term, 因此都同意向它投票,S成为了最新的leader - 由于
S离开集群时集群其他的服务器已经提交了多个log, 这些提交在S中不存在, 而S信任自己的log, 并将自己的log复制到所有的follower上, 这将覆盖已经提交了多个log, 导致了错误
- bug修改
因此, 重新审视raft论文中Figure 2的描述:Receiver implementation:
- Reply false if term < currentTerm (§5.1)
- If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)
这里的日志至少一样新指的并不是raft结构体中的currentTerm, 而是指的log中最后一项的Term, 因此需要将if判断条件修改为:
1 | if rf.votedFor == -1 || rf.votedFor == args.CandidateId { |
PS: 为什么这么显眼的错误能通过2A的测例…
1.2 修复currentTerm的追赶问题
还是RequestVote中的bug:
1 | if args.Term > rf.currentTerm { |
这里在收到其他节点的投票申请后, 如果当前的Term更小, 则撤销以前任期的投票记录, 改为未投票, 这将导致后续的if判断满足第一个投票条件: 首先要求其没有投过票或者投票对象就是这个RPC请求发起者, 但除了撤销以前任期的投票记录外, 还应该将自身转化为Follower, 同时直接将Term更新到args.Term
为什么之前的实现忽略了这些呢? 因为在之前的实现中, 预想中的角色的转化是发生在接受到心跳后。换言之, 需要等待新的leader产生后通过心跳函数来完成之前在RequestVote中出现args.Term > rf.currentTerm的节点的角色转换, 但是问题在于可能存在孤立节点, 因为孤立节点的log中的最后一项的Term很小, 但由于多次的选举超时, 其currentTerm很大, 而新的leader产生后通过心跳函数来完成某个节点角色切换为follower的前提是term更大*, 因此如果孤立节点的currentTerm很大, 需要新的leader经过非常多次的选举, 因为每次选举自增的currentTerm为1, 这将导致很长且并不要的时间消耗
所以, 修改过后的代码为:
1 | if args.Term > rf.currentTerm { |
2 论文解读: 日志复制和commit部分
日志复制的逻辑如下:
leader视角
client想集群的一个节点发送的命令, 如果不是leader,follower会通过心跳得知leader并返回给clientleader收到了命令, 将其构造为一个日志项, 添加当前节点的currentTerm为日志项的Term, 并将其追加到自己的log中leader发送AppendEntries RPC将log复制到所有的节点,AppendEntries RPC需要增加PrevLogIndex、PrevLogTerm以供follower校验, 其中PrevLogIndex、PrevLogTerm由nextIndex确定- 如果
RPC返回了成功, 则更新matchIndex和nextIndex, 同时寻找一个满足过半的matchIndex[i] >= N的索引位置N, 将其更新为自己的commitIndex, 并提交直到commitIndex部分的日志项 - 如果
RPC返回了失败, 且伴随的的Term更大, 表示自己已经不是leader了, 将自身的角色转换为Follower, 并更新currentTerm和votedFor, 重启计时器 - 如果
RPC返回了失败, 且伴随的的Term和自己的currentTerm相同, 将nextIndex自减再重试
follower视角
follower收到AppendEntries RPC后,currentTerm不匹配直接告知更新的Term, 并返回falsefollower收到AppendEntries RPC后, 通过PrevLogIndex、PrevLogTerm可以判断出”leader认为自己log的结尾位置”是否存在并且Term匹配, 如果不匹配, 返回false并不执行操作;- 如果上述位置的信息匹配, 则需要判断插入位置是否有旧的日志项, 如果有, 则向后将
log中冲突的内容清除 - 将
RPC中的日志项追加到log中 - 根据
RPC的传入参数更新commitIndex, 并提交直到commitIndex部分的日志项
3 设计思路
3.1 心跳和AppendEntries的区别?
根据2A的内容可知, 心跳就是一种特殊的AppendEntries, 其特殊在Entries长度为0, 并且有论文可知
• If last log index ≥ nextIndex for a follower: send AppendEntries RPC with log entries starting at nextIndex
• If successful: update nextIndex and matchIndex for follower (§5.3)
• If AppendEntries fails because of log inconsistency: decrement nextIndex and retry (§5.3)
AppendEntries除了PRC失败的情况下, 会一直重试, 直到返回true, 那么如果我们单独创建一个协程用于发送真正的不为心跳的AppendEntries, 需要考虑如下的问题:
- 重试是应该立即重试, 还是设置一个重置超时?
- 何时触发这个处理
AppendEntries的协程? 是累计了多个个日志项后再出发处理协程? 还是一旦有一个日志项就触发? - 发射心跳处理函数时也会附带
PrevLogIndex和PrevLogTerm以供follower验证, 心跳函数的这些参数会不会和之前的AppendEntries冲突?follower端如何处理这些重复的内容?
看完上述几点, 我们可以看出, 如果将AppendEntries和心跳的发射器分开实现, 会增加代码的复杂度, 同时AppendEntries也具有重复发送的特点, 这和心跳的特点完美契合, 因此, 我们得出如下结论: AppendEntries可以和心跳公用同一个发射器
3.2 结构体参数解读
首先raft结构体会新增几个2A中没有使用过的成员, 解释如下:
1 | type Raft struct { |
因此, 发送心跳或者AppendEntries时, AppendEntriesArgs应如下构造:
1 | args := &AppendEntriesArgs{ |
PS: 术语补充
commited: 集群中半数节点都已经复制了日志, 这保证了这个日志即使在重新选举后仍然存在, 因为不存在commited日志项的节点不会被选举applied: 指日志项的内容已经被应用到状态机
3.3 代码架构分析
- 由于
AppendEntries和心跳公用同一个发射器(此后就称为心跳发射), 因此leader只需要将从client接收的心得日志项追加到log中即可, 发射器在每次超时到达后, 从每个nextIndex[i]构造Entries切片, 如果切片长度为0就是心跳, 不需要显式地判断是心跳或者是真的AppendEntries。 - 处理每个
AppendEntrie RPC回复的函数只需要调整nextIndex和matchIndex即可, 下次心跳发送时会自动更新切片的长度。 - 处理每个
AppendEntrie RPC回复的函数还需要找到N以更新commitIndex并唤醒应用到状态机的协程(这个协程也可以是Sleep+ 轮训的方式实现) - 由于
AppendEntries也会附带上一次跳发射的回复处理中可能被更新的commitIndex, 因此follower端也会根据commitIndex唤醒自己的应用到状态机的协程(这个协程也可以是Sleep+ 轮训的方式实现)
4 代码实现
4.1 修改后的发射器
1 | func (rf *Raft) SendHeartBeats() { |
与之前的区别就是为每个发送的follower单独构建了AppendEntriesArgs, 代码整体很简单, 几乎没啥区别
4.2 AppendEntries handler
1 | func (rf *Raft) handleAppendEntries(serverTo int, args *AppendEntriesArgs) { |
这里做出了如下几个修改:
- 回复成功后, 添加了确定
N的代码, 并判断是否更新commitIndex, 由于这里采取的应用到状态机的协程使用的是Sleep+轮训的方式, 因此没有别的操作, 如果采用条件变量, 还需要唤醒条件变量 - 如果返回
false但term相同, 表明对应的follower在prevLogIndex位置没有与prevLogTerm匹配的项或者不存在prevLogIndex, 将nextIndex自减, 下一次发射器会重试
4.3 AppendEntries RPC
1 | // AppendEntries handler |
这里的改动主要是增加了具体的append业务, 架构与之前变化不大, 需要注意的是, 如果采用条件变量实现应用到状态机的协程, 还需要唤醒条件变量。
4.4 Start函数
Start函数只是将command追加到自己的log中, 因此其不保证command一定会提交。 其不需要调用任何其他的协程, 因此心跳函数是周期性自动检测的。
1 | func (rf *Raft) Start(command interface{}) (int, int, bool) { |
4.5 应用到状态机的协程
CommitChecker也是一个轮询的协程, 也可以使用条件变量来实现, 其不断检查rf.commitIndex > rf.lastApplied, 将rf.lastApplied递增然后发送到管道applyCh 。
1 | func (rf *Raft) CommitChecker() { |
4.6 修改选举函数
由于nextIndex[]和matchIndex[]是易失性数据, 每次重新选出leader后需要重新初始化, 因此对collectVote修改如下:
1 | func (rf *Raft) collectVote(serverTo int, args *RequestVoteArgs) { |
5 测试
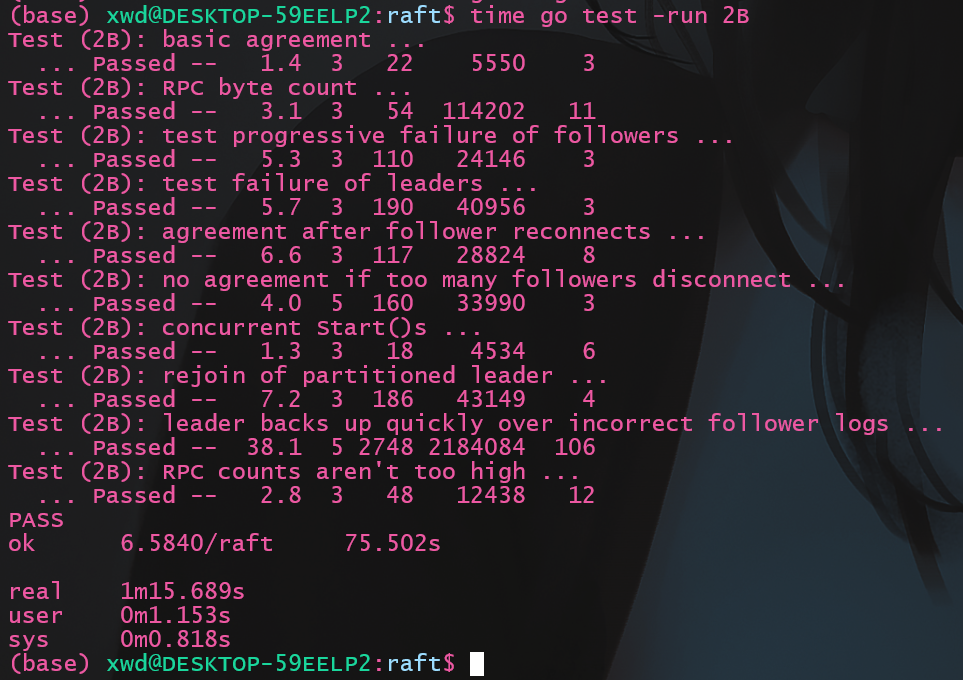
5.1 常规测试
执行测试命令
1 | go test -v -run 2B |
结果如下:
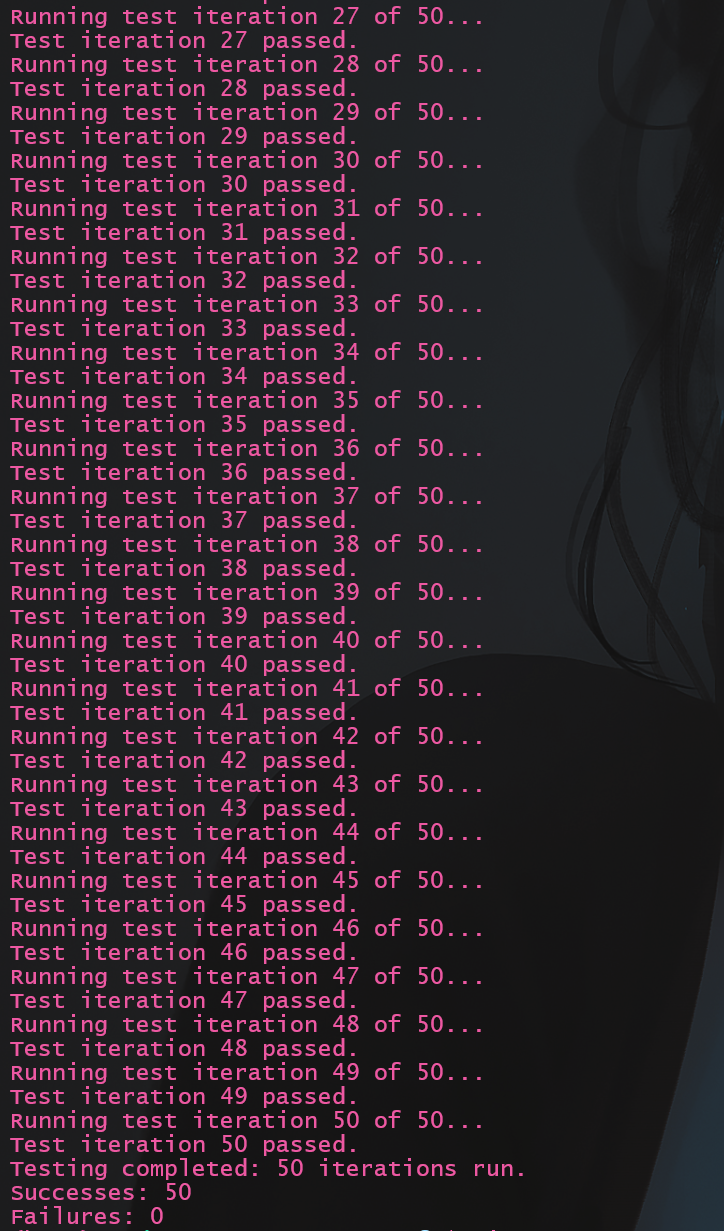
5.2 多次测试
raft的许多特性导致其一次测试并不准确, 有些bug需要多次测试才会出现, 编写如下脚本命名为manyTest_2B.sh:
1 | !/bin/bash |
再次进行测试:
1 | ./manyTest_2B.sh |
结果:
6 代码优化
代码优化的初衷是看到了官网的描述:
The “ok 6.5840/raft 35.557s” means that Go measured the time taken for the 2B tests to be 35.557 seconds of real (wall-clock) time. The “user 0m2.556s” means that the code consumed 2.556 seconds of CPU time, or time spent actually executing instructions (rather than waiting or sleeping). If your solution uses much more than a minute of real time for the 2B tests, or much more than 5 seconds of CPU time, you may run into trouble later on. Look for time spent sleeping or waiting for RPC timeouts, loops that run without sleeping or waiting for conditions or channel messages, or large numbers of RPCs sent.
我之前的时间花了75.5s, 因此准备优化, 不过优化后发现也没多大改善, 主要原因是没有实现快速回退, 目前回退是一个一个的, 当然慢, 不过这个是2C的后话了
- 优化1: 使用条件变量
将CommitChecker改为条件变量控制而不是轮询, 这里就不贴代码了, 很简单 - 优化1: 使用timer
尽管课程不推荐timer, 但ticker如果是轮训的话, 应该是不如定时器快的, 因此试了下定时器的实现
这里也不贴代码了, 很简单
优化后再次测试:
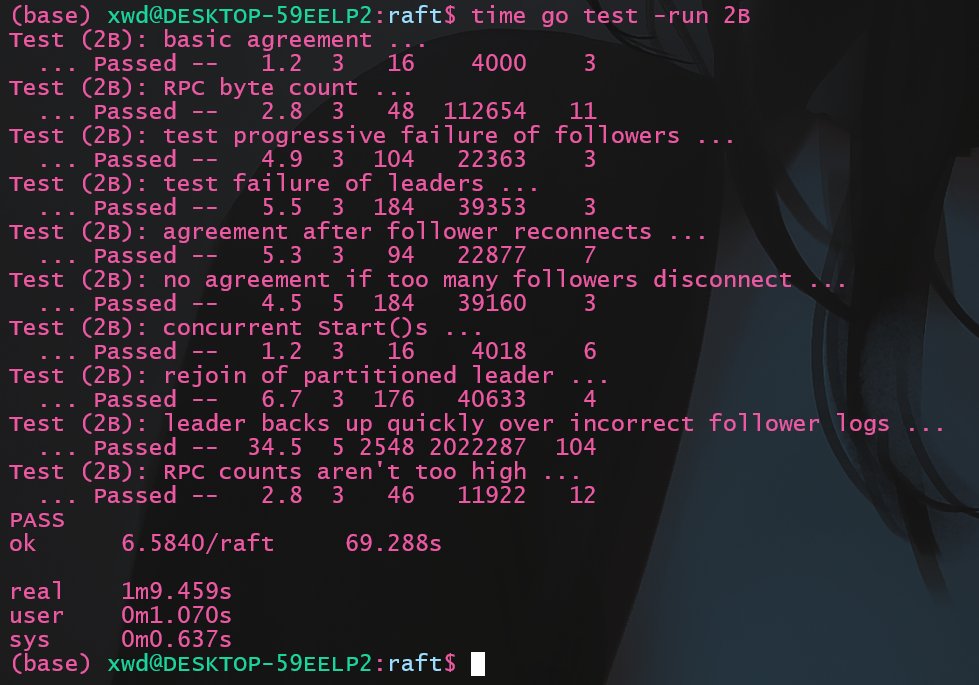
快了6s, 有一定程度提升, 但倒数第二个测试Test (2B): leader backs up quickly over incorrect follower logs ...
还是很慢, 应该是暂时还没实现快速回退的原因