1 实验介绍 本次实验是实现一个简易版本的MapReduce编程框架,官方文档在这里:lab1文档 , 强烈建议先阅读MapReduce的论文 , 难度主要体现在设计上, 实际的代码实现倒是相对简单, 这也得益于go的语言特性, 比CMU15445使用Cpp写代码方便多了。实验需要实现的是Coordinator和Worker的设计, 具体实现细节十分自由(无从下手)
我的代码实现点这里: https://github.com/ToniXWD/MIT6.5840/tree/lab1
2 既有框架解读 解读现有的框架设计是第一步。
2.1 代码解读
阅读src/main/mrcoordinator.go可知:MakeCoordinator启动了一个Coordinator c, c.server()中启用了一个协程用于接受RPC调用:go http.Serve(l, nil), 需要注意的是, 在 Go 的 net/http 包中, 使用 http.Serve(l, nil) 启动 HTTP 服务器以侦听和处理请求时,服务器会为每个进来的请求自动启动一个新的协程。这意味着每个 RPC 调用都是在其自己的独立协程中被处理的,允许并发处理多个请求。因此, 我们的设计可能需要使用锁等同步原语实现共享资源的保护, 同时Coordinator不会主动与Worker通信(除非自己额外实现), 只能通过Worker的RPC通信来完成任务。同时, 当所有任务完成时, Done方法将会返回false, 从而将Coordinator关闭。
阅读src/main/mrworker.gomrworker.go仅仅通过Worker函数来运行, 因此Worker函数需要完成请求任务、执行任务、报告任务执行状态等多种任务。因此可以猜测,Worker需要再这个函数里不断地轮训Coordinator,根据Coordinator的不同回复驱使当前Worker完成各种任务。
2.2 任务误区解读
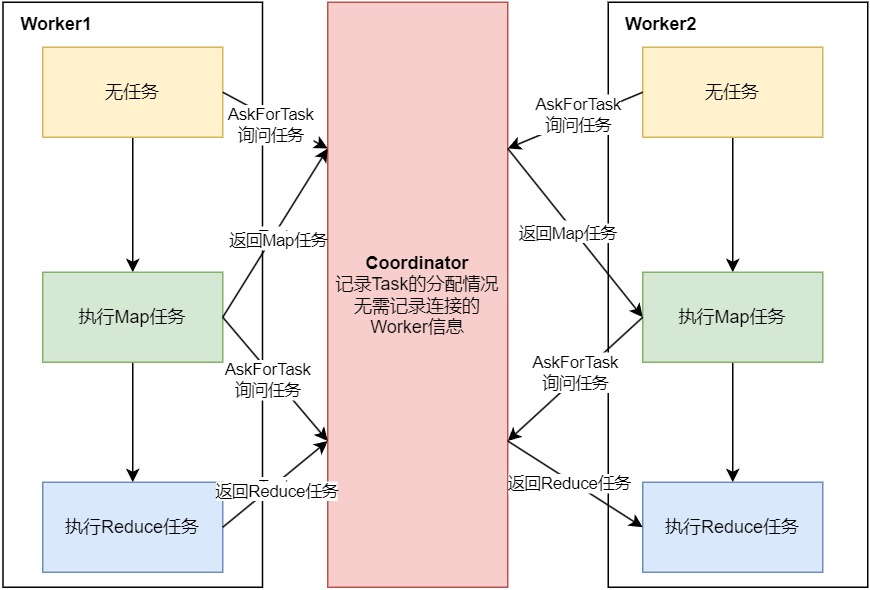
Map、Reduce任务、Coordinator和Worker的关系如何?Task)与Worker是什么关系呢? 是否存在对应关系? 这些对应关系需要记录吗? 通常, 在常见的主从关系中, 主节点需要记录从节点的信息,例如线程id等表名身份的信息, 但在我们的MapReduce中却没有这样的必要, 因为Worker节点是可以扩容的, 而Coordinator与Worker之间只有传递Task相关信息的需求, 因此Coordinator只需要记录Task任务的状态即可, Task分配给Worker后执行可能成功或失败, 因此Coordinator还需要维护任务执行的时间信息, 以便在超时后重新分配任务。因此,Map、Reduce任务、Coordinator和Worker的关系可以参考下图:
Worker可能在不同时间执行不同的Task, 也可能什么也不做(初始状态或等候所有Map Task完成时可能会闲置)
Map、Reduce任务有多少个? 如何分配?
Map Task实际上在此实验中被简化了, 每个Map Task的任务就是处理一个.txt文件, 因此Map Task的数量实际上就是.txt文件的数量。 因此, 每个.txt文件对应的Map Task需要Coordinator记录其执行情况并追踪。Reduce Task的数量是nReduce。由于Map Task会将文件的内容分割为指定的nReduce份, 每一份应当由序号标明, 拥有这样的序号的多个Map Task的输出汇总起来就是对应的Reduce Task的输入。
中间文件的格式是怎么样的? Reduce任务如何选择中间文件作为输入?Map Task分割采用的是统一的哈希函数ihash, 所以相同的key一定会被Map Task输出到格式相同的中间文件上。例如在wc任务中, Map Task 1和Map Task 2输入文件中都存在hello这个词, Map Task 1中所有的hello会被输出到mr-out-1-5这个中间文件, 1代表Map Task序号, 5代表被哈希值取模的结果。那么,Map Task 2中所有的hello会被输出到mr-out-2-5这个中间文件。那么Reduce Task 5读取的就是形如mr-out-*-5这样的文件。
3 设计与实现 3.1 RPC设计 3.1.1. 消息类型 ,通信时首先需要确定这个消息是什么类型, 通过前述分析可知, 通信的信息类型包括:
Worker请求任务Coordinator分配Reduce或Map任务Worker报告Reduce或Map任务的执行情况(成功或失败)Coordinator告知Worker休眠(暂时没有任务需要执行)Coordinator告知Worker退出(所有任务执行成功)
每一种消息类型会需要附带额外的信息, 例如Coordinator分配任务需要告知任务的ID, Map任务还需要告知NReduce,和输入文件名。Send和Reply是从Worker视角出发的):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 const ( AskForTask MsgType = iota MapTaskAlloc ReduceTaskAlloc MapSuccess MapFailed ReduceSuccess ReduceFailed Shutdown Wait ) type MessageSend struct { MsgType MsgType TaskID int } type MessageReply struct { MsgType MsgType NReduce int TaskID int TaskName string }
3.1.2 通信函数设计 在我的设计中,Worker只需要有2个动作:
向Coordinator请求Task
向Coordinator报告之前的Task的执行情况
因此, worker.go中通信函数应该是下面的样子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 func CallForReportStatus (succesType MsgType, taskID int ) error { args := MessageSend{ MsgType: succesType, TaskID: taskID, } err := call("Coordinator.NoticeResult" , &args, nil ) return err } func CallForTask () args := MessageSend{ MsgType: AskForTask, } reply := MessageReply{} err := call("Coordinator.AskForTask" , &args, &reply) if err == nil { return &reply } else { return nil } }
在coordinator.go有相应的处理函数:
1 2 func (c *Coordinator) error {}func (c *Coordinator) error {}
这些处理函数则需要进一步的设计。
3.2 Worker设计 3.2.1 Worker主函数设计 由之前的分析可以看出,Woker所做的内容就是不断的请求任务、执行任务和回复任务执行情况,因此,可以很容易地写出Worker函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func Worker (mapf func (string , string ) reducef func (string , []string ) string ) { for { replyMsg := CallForTask() switch replyMsg.MsgType { case MapTaskAlloc: err := HandleMapTask(replyMsg, mapf) if err == nil { _ = CallForReportStatus(MapSuccess, replyMsg.TaskID) } else { _ = CallForReportStatus(MapFailed, replyMsg.TaskID) } case ReduceTaskAlloc: err := HandleReduceTask(replyMsg, reducef) if err == nil { _ = CallForReportStatus(ReduceSuccess, replyMsg.TaskID) } else { _ = CallForReportStatus(ReduceFailed, replyMsg.TaskID) } case Wait: time.Sleep(time.Second * 10 ) case Shutdown: os.Exit(0 ) } time.Sleep(time.Second) } }
3.2.2 Map Task执行函数 HandleMapTask函数是执行具体的MapTask, 这样部分很简单, 可以从mrsequential.go中偷代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 func HandleMapTask (reply *MessageReply, mapf func (string , string ) error { file, err := os.Open(reply.TaskName) if err != nil { return err } defer file.Close() content, err := io.ReadAll(file) if err != nil { return err } kva := mapf(reply.TaskName, string (content)) sort.Sort(ByKey(kva)) oname_prefix := "mr-out-" + strconv.Itoa(reply.TaskID) + "-" key_group := map [string ][]string {} for _, kv := range kva { key_group[kv.Key] = append (key_group[kv.Key], kv.Value) } _ = DelFileByMapId(reply.TaskID, "./" ) for key, values := range key_group { redId := ihash(key) oname := oname_prefix + strconv.Itoa(redId%reply.NReduce) var ofile *os.File if _, err := os.Stat(oname); os.IsNotExist(err) { ofile, _ = os.Create(oname) } else { ofile, _ = os.OpenFile(oname, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644 ) } enc := json.NewEncoder(ofile) for _, value := range values { err := enc.Encode(&KeyValue{Key: key, Value: value}) if err != nil { ofile.Close() return err } } ofile.Close() } return nil }
虽然偷了很多代码, 但是有家店需要注意, 因为之前的Worker可能写入了一部分数据到中间文件后失败的情况, 之后Coordinator重新分配任务时, 文件是可能存在脏数据的, 因此需要先执行清理:
1 _ = DelFileByMapId(reply.TaskID, "./" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 func DelFileByMapId (targetNumber int , path string ) error { pattern := fmt.Sprintf(`^mr-out-%d-\d+$` , targetNumber) regex, err := regexp.Compile(pattern) if err != nil { return err } files, err := os.ReadDir(path) if err != nil { return err } for _, file := range files { if file.IsDir() { continue } fileName := file.Name() if regex.MatchString(fileName) { filePath := filepath.Join(path, file.Name()) err := os.Remove(filePath) if err != nil { return err } } } return nil }
DelFileByMapId函数删除特定Map Task的输出文件, 但这样的执行存在一定隐患:
首先是Coordinator只能重新分配一个Worker执行Coordinator认为死掉的任务, 这一点可以通过加锁和记录时间戳完成, 后续会讲到
其次, 如果之前死掉的Worker又活了,其可能和现在的Worker的输出又有交叉了
因此, 目前的实现是存在一定漏洞的, 有以下的改进方案:
参考官方的提示, 先为当前的中间文件使用临时名, 完成操作后再进行原子重命名
通过加文件锁的方式保护文件
Ps: 后续有时间再改代码吧
3.2.3 Reduce Task执行函数 Reduce Task手机对应序号的中间文件, 汇总后应用指定的reduce函数,实现也比较简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 func HandleReduceTask (reply *MessageReply, reducef func (string , []string ) string ) error { key_id := reply.TaskID k_vs := map [string ][]string {} fileList, err := ReadSpecificFile(key_id, "./" ) if err != nil { return err } for _, file := range fileList { dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } k_vs[kv.Key] = append (k_vs[kv.Key], kv.Value) } file.Close() } var keys []string for k := range k_vs { keys = append (keys, k) } sort.Strings(keys) oname := "mr-out-" + strconv.Itoa(reply.TaskID) ofile, err := os.Create(oname) if err != nil { return err } defer ofile.Close() for _, key := range keys { output := reducef(key, k_vs[key]) _, err := fmt.Fprintf(ofile, "%v %v\n" , key, output) if err != nil { return err } } DelFileByReduceId(reply.TaskID, "./" ) return nil }
需要注意的是, 我收集文件内容是使用了map, 而迭代map时, key的顺序是随机的, 因此需要先进行对key排序的操作:
1 2 3 4 5 6 var keys []string for k := range k_vs { keys = append (keys, k) } sort.Strings(keys)
其实这里也存在漏洞:同样就是死了的Worker突然复活了怎么办的问题,相比Map Task来说, 这里虽然相对不容易出错, 因为这里对多个中间文件只存在读取而不存在写入, 将内容读取到内存中不会有冲突的。出错只可能在将数据在写入到指定的文件时, os.Create(oname)也会存在竞争条件:因为网络等问题,Coordinator启动了多个Worker, 多个Worker同时运行,并且都尝试创建同一个文件名oname, 假设一个Worker先创建了oname并写入了一部分数据,当另一个Worker再次调用os.Create(oname)时,之前的数据将会被清空。这意味着第一个Worker在接下来的写操作中不会出现错误,但它写入的部分数据会丢失,因为第二个Worker已经截断了文件。
因此, 目前的实现是也存在一定漏洞的, 有以下的改进方案:
参考官方的提示, 先为当前的中间文件使用临时名, 完成操作后再进行原子重命名
通过加文件锁的方式保护文件
3.3 Coordinator设计 3.3.1 TaskInfo设计 首先需要考虑的是, 如何维护Task的执行信息, Task执行状态包括了: 未执行、执行者、执行失败、执行完成。Coordinator与Worker是通过RPC来驱动彼此运行的, 当然你也可以启动一个goroutine间隔地检查是否超时, 但为了使设计更简单, 我们可以这样设计检查超时的方案:
为每个Worker分配Task时需要记录Task被分配的时间戳, 并将其状态置为running
为每个Worker分配Task, 遍历存储TaskInfo的数据结构, 检查每一个状态为running的Task的时间戳是否与当前时间戳差距大于10s, 如果是, 则代表这个Task超时了, 立即将它分配给当前请求的Worker, 并更新其时间戳
如果导致Task超时的老旧的Woker之后又完成了, 结果也就是这个Task返回了多次执行成功的报告而已, 可忽略
PS: Worker执行失败有2种, 一种是Worker没有崩溃但发现了error, 这时Worker会将错误报告给Coordinator, Coordinator会将其状态设置为failed, 另一种情况是Worker崩溃了, 连通知都做不到, 这就以超时体现出来, 处理好超时即可
因此, 我如下设计TaskInfo的数据结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 type taskStatus int const ( idle taskStatus = iota running finished failed ) type MapTaskInfo struct { TaskId int Status taskStatus StartTime int64 } type ReduceTaskInfo struct { Status taskStatus StartTime int64 } type Coordinator struct { NReduce int MapTasks map [string ]*MapTaskInfo mu sync.Mutex ReduceTasks []*ReduceTaskInfo }
添加TaskInfo的初始化方法, 并在MakeCoordinator中调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (c *Coordinator) string ) { for idx, fileName := range files { c.MapTasks[fileName] = &MapTaskInfo{ TaskId: idx, Status: idle, } } for idx := range c.ReduceTasks { c.ReduceTasks[idx] = &ReduceTaskInfo{ Status: idle, } } } func MakeCoordinator (files []string , nReduce int ) c := Coordinator{ NReduce: nReduce, MapTasks: make (map [string ]*MapTaskInfo), ReduceTasks: make ([]*ReduceTaskInfo, nReduce), } c.initTask(files) c.server() return &c }
3.3.2 RPC 响应函数-AskForTask 这部分算是较为复杂的, 其逻辑如下:
如果有闲置的任务(idle)和之前执行失败(failed)的Map Task, 选择这个任务进行分配
如果检查到有超时的任务Map Task, 选择这个任务进行分配
如果以上的Map Task均不存在, 但Map Task又没有全部执行完成, 告知Worker先等待
Map Task全部执行完成的情况下, 按照1和2相同的逻辑进行Reduce Task的分配所有的Task都执行完成了, 告知Worker退出
因此, AskForTask代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 func (c *Coordinator) error { if req.MsgType != AskForTask { return BadMsgType } c.mu.Lock() defer c.mu.Unlock() count_map_success := 0 for fileName, taskinfo := range c.MapTasks { alloc := false if taskinfo.Status == idle || taskinfo.Status == failed { alloc = true } else if taskinfo.Status == running { curTime := time.Now().Unix() if curTime-taskinfo.StartTime > 10 { taskinfo.StartTime = curTime alloc = true } } else { count_map_success++ } if alloc { reply.MsgType = MapTaskAlloc reply.TaskName = fileName reply.NReduce = c.NReduce reply.TaskID = taskinfo.TaskId taskinfo.Status = running taskinfo.StartTime = time.Now().Unix() return nil } } if count_map_success < len (c.MapTasks) { reply.MsgType = Wait return nil } count_reduce_success := 0 for idx, taskinfo := range c.ReduceTasks { alloc := false if taskinfo.Status == idle || taskinfo.Status == failed { alloc = true } else if taskinfo.Status == running { curTime := time.Now().Unix() if curTime-taskinfo.StartTime > 10 { taskinfo.StartTime = curTime alloc = true } } else { count_reduce_success++ } if alloc { reply.MsgType = ReduceTaskAlloc reply.TaskID = idx taskinfo.Status = running taskinfo.StartTime = time.Now().Unix() return nil } } if count_reduce_success < len (c.ReduceTasks) { reply.MsgType = Wait return nil } reply.MsgType = Shutdown return nil }
在这里, 我对数据的保护是一把大锁保平安, 这其实可以优化的
3.3.3 RPC 响应函数-NoticeResult 这个函数就简单很多了, 只需要改变对应TaskInfo的状态即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (c *Coordinator) error { c.mu.Lock() defer c.mu.Unlock() if req.MsgType == MapSuccess { for _, v := range c.MapTasks { if v.TaskId == req.TaskID { v.Status = finished break } } } else if req.MsgType == ReduceSuccess { c.ReduceTasks[req.TaskID].Status = finished } else if req.MsgType == MapFailed { for _, v := range c.MapTasks { if v.TaskId == req.TaskID { v.Status = failed break } } } else if req.MsgType == ReduceFailed { c.ReduceTasks[req.TaskID].Status = failed } return nil }
3.3.4 Done方法 Done方法是最简单的, 遍历TaskInfo的数据结构, 如果全部完成则返回True,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 func (c *Coordinator) bool { for _, taskinfo := range c.MapTasks { if taskinfo.Status != finished { return false } } for _, taskinfo := range c.ReduceTasks { if taskinfo.Status != finished { return false } } return true }
有一个小细节, time.Sleep(time.Second * 5)是为了让Coordinator延迟关闭, 这样可以留出时间告知Worker退出, 也可以直接注释掉它, 让测试跑得更快
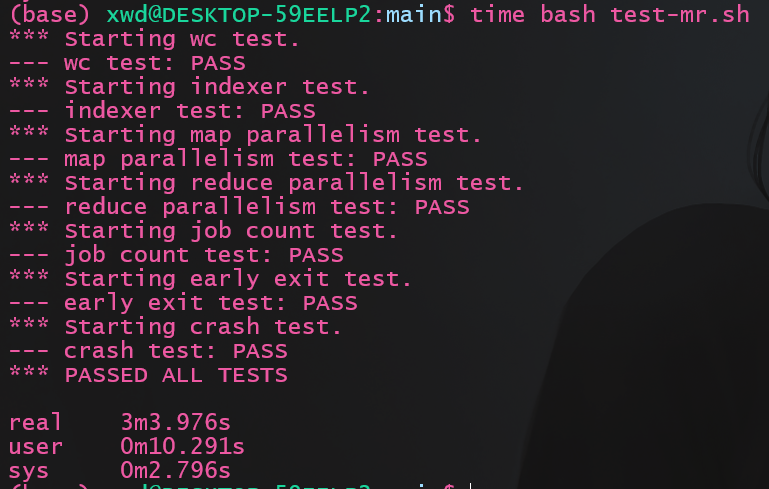
4 测试和优化 4.1 原实现测试 运行测试:
结果如下图, 耗时3m3s
4.2 优化 4.2.1 原子重命名 按照官方提示, 使用原子重命名避免竞争, 修改HandleMapTask函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 func HandleMapTask (reply *MessageReply, mapf func (string , string ) error { file, err := os.Open(reply.TaskName) if err != nil { return err } defer file.Close() content, err := io.ReadAll(file) if err != nil { return err } kva := mapf(reply.TaskName, string (content)) sort.Sort(ByKey(kva)) tempFiles := make ([]*os.File, reply.NReduce) encoders := make ([]*json.Encoder, reply.NReduce) for _, kv := range kva { redId := ihash(kv.Key) % reply.NReduce if encoders[redId] == nil { tempFile, err := ioutil.TempFile("" , fmt.Sprintf("mr-map-tmp-%d" , redId)) if err != nil { return err } defer tempFile.Close() tempFiles[redId] = tempFile encoders[redId] = json.NewEncoder(tempFile) } err := encoders[redId].Encode(&kv) if err != nil { return err } } for i, file := range tempFiles { if file != nil { fileName := file.Name() file.Close() newName := fmt.Sprintf("mr-out-%d-%d" , reply.TaskID, i) if err := os.Rename(fileName, newName); err != nil { return err } } } return nil }
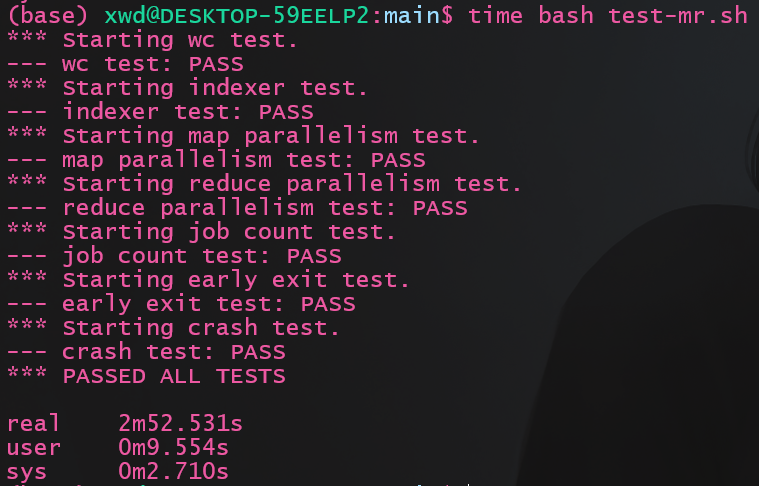
运行测试:
结果如下图, 耗时2m52s, 原子重命名节省了原实现中的清理耗费的时间, 节约了差不多10s的样子
4.2.2 锁细化 我们可以发现, 在Worker请求任务时, Map Task是需要先全部执行成功的, 因此我们可以增加一个字段记录Map Task是否全部完成, 同时为MapTaskInfo和ReduceTaskInfo分别实现设计一个锁来取代原来的大锁, 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 type Coordinator struct { NReduce int MapTasks map [string ]*MapTaskInfo MapSuccess bool muMap sync.Mutex ReduceTasks []*ReduceTaskInfo ReduceSuccess bool muReduce sync.Mutex } func (c *Coordinator) error { if req.MsgType != AskForTask { return BadMsgType } if !c.MapSuccess { c.muMap.Lock() count_map_success := 0 for fileName, taskinfo := range c.MapTasks { alloc := false if taskinfo.Status == idle || taskinfo.Status == failed { alloc = true } else if taskinfo.Status == running { curTime := time.Now().Unix() if curTime-taskinfo.StartTime > 10 { taskinfo.StartTime = curTime alloc = true } } else { count_map_success++ } if alloc { reply.MsgType = MapTaskAlloc reply.TaskName = fileName reply.NReduce = c.NReduce reply.TaskID = taskinfo.TaskId taskinfo.Status = running taskinfo.StartTime = time.Now().Unix() c.muMap.Unlock() return nil } } c.muMap.Unlock() if count_map_success < len (c.MapTasks) { reply.MsgType = Wait return nil } else { c.MapSuccess = true } } if !c.ReduceSuccess { c.muReduce.Lock() count_reduce_success := 0 for idx, taskinfo := range c.ReduceTasks { alloc := false if taskinfo.Status == idle || taskinfo.Status == failed { alloc = true } else if taskinfo.Status == running { curTime := time.Now().Unix() if curTime-taskinfo.StartTime > 10 { taskinfo.StartTime = curTime alloc = true } } else { count_reduce_success++ } if alloc { reply.MsgType = ReduceTaskAlloc reply.TaskID = idx taskinfo.Status = running taskinfo.StartTime = time.Now().Unix() c.muReduce.Unlock() return nil } } c.muReduce.Unlock() if count_reduce_success < len (c.ReduceTasks) { reply.MsgType = Wait return nil } else { c.ReduceSuccess = true } } reply.MsgType = Shutdown return nil }
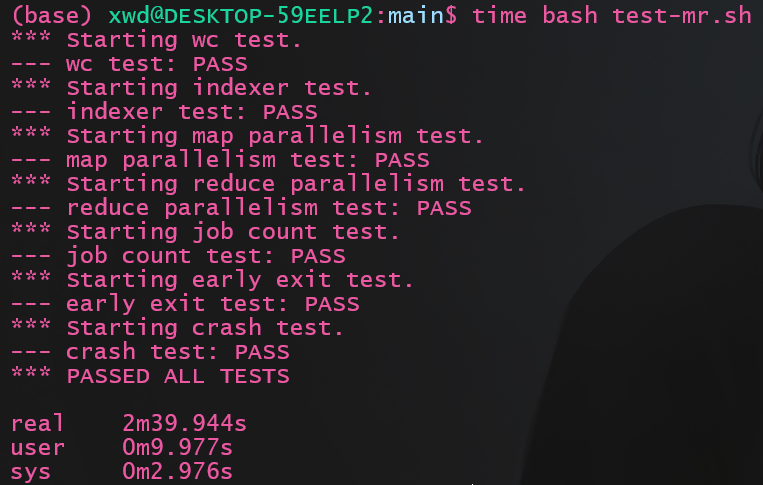
运行测试:
结果如下图, 耗时2m39s, 原子重命名节省了原实现中的清理耗费的时间, 又节约了差不多13s的样子NoticeResult也要相应地修改, 由于比较简单就不列出来了, 可以直接看仓库代码。